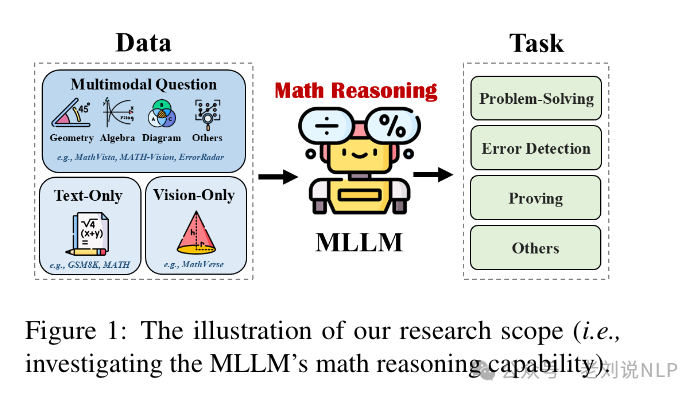
多模态大模型数学推理挑战与方案
在多模态大型语言模型(MLLMs)时代,数学推理是一个极具挑战性且重要的研究方向。解决这一问题需要克服多个层面的困难。
首先,数学问题往往涉及复杂的视觉内容提取与推理,例如图表、表格或几何图形。当前模型在处理三维几何解释或分析不规则结构表格等复杂视觉细节时仍存在显著短板。
其次,现实世界的数学推理不仅限于文本和视觉,还可能涉及音频解释、交互式问题解决环境或动态模拟。当前模型在处理这些多样化输入源方面的能力较为有限,难以适应真实场景的复杂性。
此外,数学推理涵盖代数、几何、图表分析和常识等多个领域,每个领域都有其特定的问题解决要求。现有模型通常在一个特定领域表现良好,但缺乏跨领域的泛化能力,导致在不同类型题目间切换时性能波动较大。
同时,数学推理过程中涉及多种类型的错误,包括计算错误、逻辑不一致和问题误解。当前模型缺乏有效检测和纠正这些错误的能力,这可能导致推理过程中的错误累积,最终影响答案的正确性。
最后,现有的基准测试和模型评估常常忽视现实教育情境,例如学生如何使用草稿(如手写笔记或图表)来辅助解决问题。这些现实元素对于理解人类如何进行数学推理至关重要,也是提升模型实用性的关键。
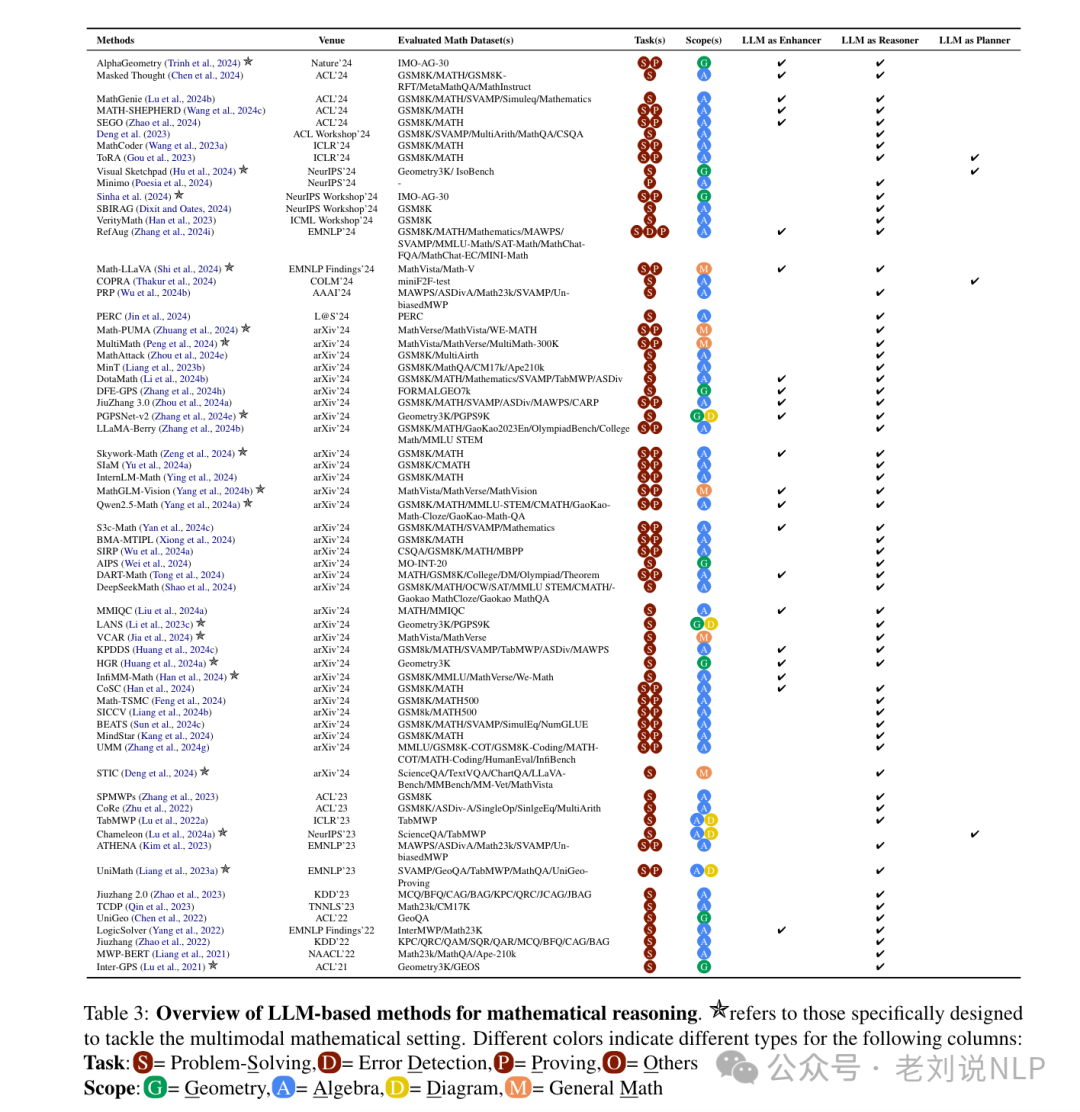
针对上述挑战,近期工作《A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges》对多模态大模型在数学推理领域的进展进行了综述,并提出了三种 LLM 应用范式:
1. 推理器 (Reasoner)
推理器利用 LLMs 自身的推理能力直接解决问题。典型策略包括结合多步推理的步骤级和路径级策略。例如,Math-SHEPHERD 作为一个过程导向的数学验证器,能够为 LLMs 输出的每一步分配奖励分数,从而引导模型生成更准确的中间步骤。
2. 增强器 (Enhancer)
增强器通过数据增强技术提高模型性能。方法包括在训练过程中引入扰动和随机掩盖思维链中的标记来增强输入鲁棒性。Math-Genie 则通过从小规模数据集中迭代创建新解决方案,生成多样且可靠的数学问题和解决方案,从而丰富训练数据分布。
3. 规划器 (Planner)
规划器协调多个模型或工具以协同解决问题。例如,使用自然语言理由和基于程序的工具序列协同解决数学问题。这种方法允许模型调用外部计算器或代码解释器来处理精确计算,弥补纯文本模型的数值弱点。
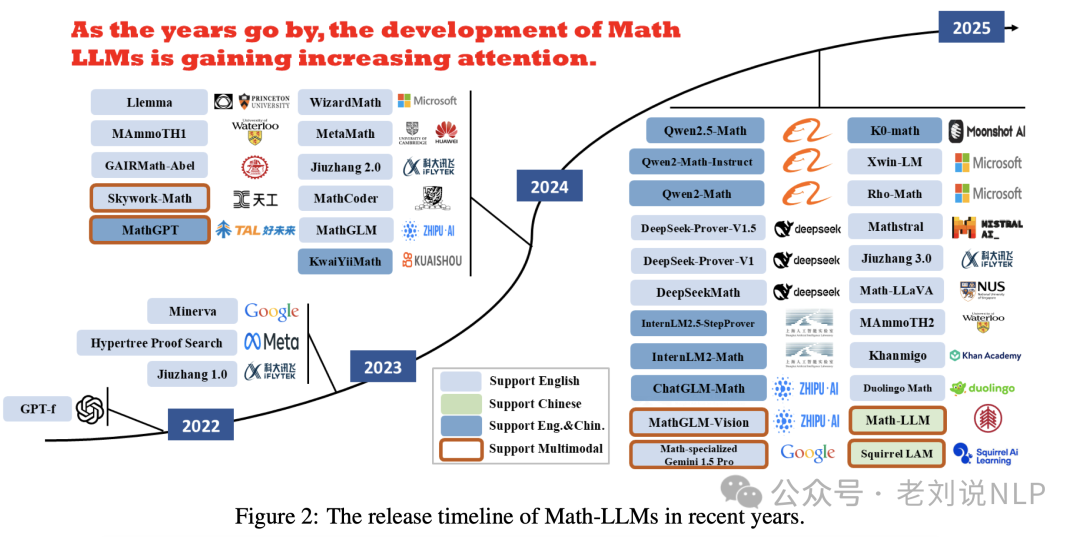
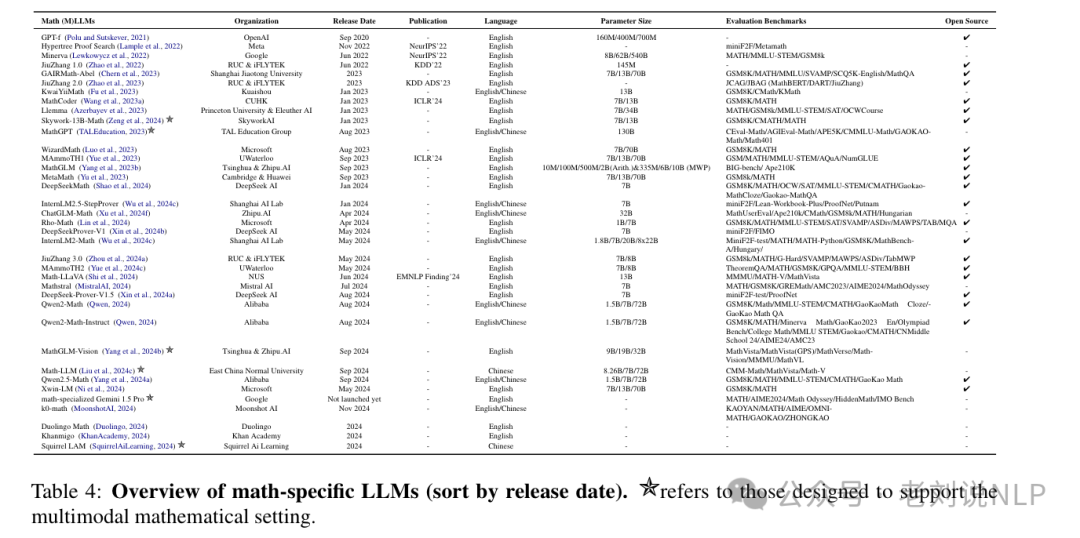
目前已有专门针对数学推理的大模型列表,涵盖了从基础模型到专用微调模型的各种尝试,展示了该领域的快速发展趋势。
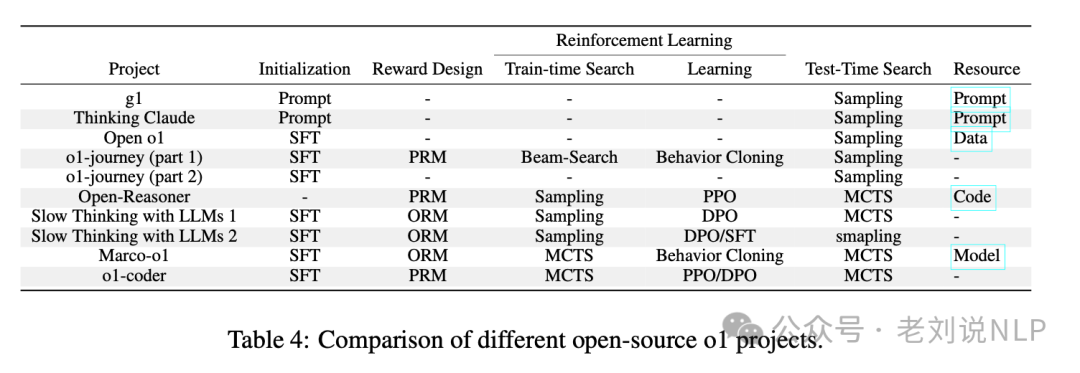
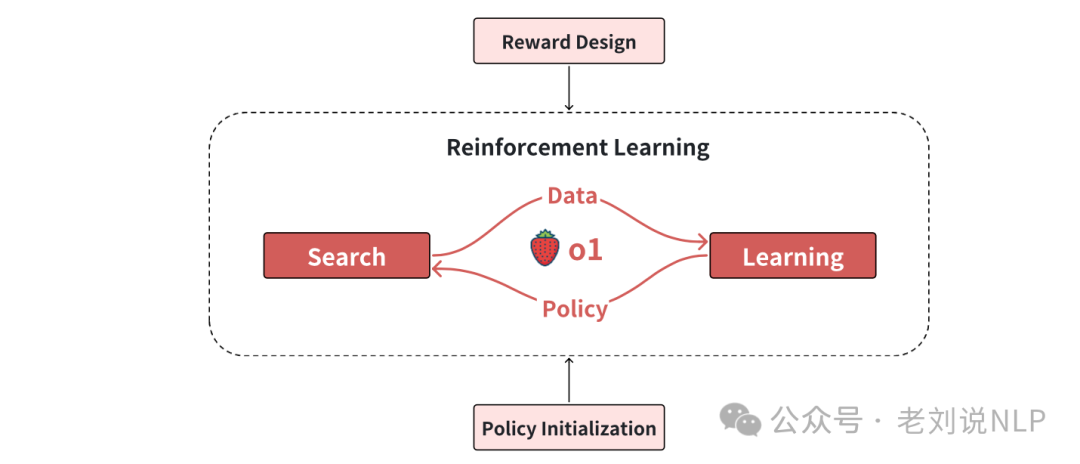
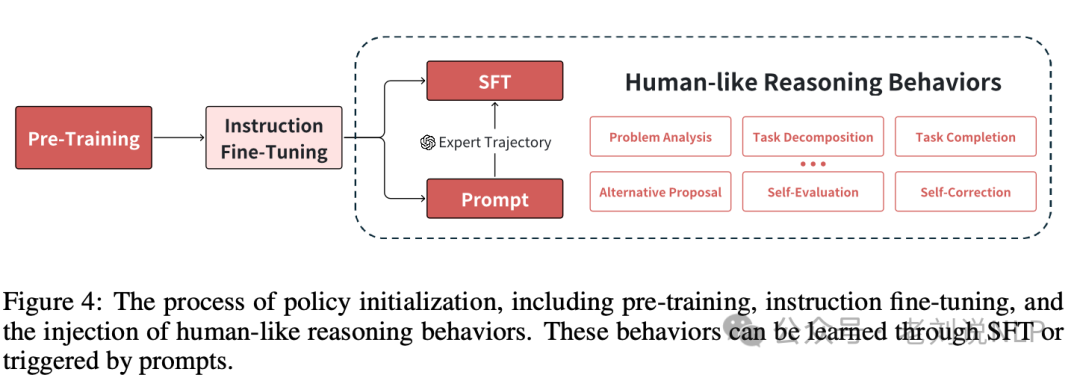
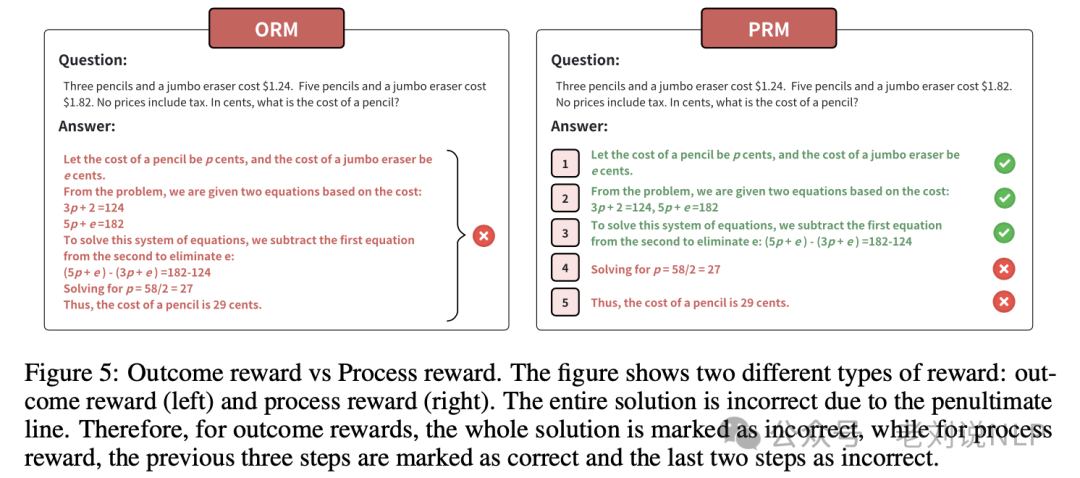
OpenAI o1 模型复现技术分析
关于 OpenAI o1 模型的跟进,目前已有多个技术方案。大多数现有方案采用知识蒸馏模仿 o1 的推理风格,但这些方法的效果受限于教师模型的能力上限及数据质量。