0 基础入门大模型,这些是要学的,但是你的第一口不一定从这里咬下去。
真的没有必要一上来就把时间精力全部投入到复杂的理论、各种晦涩的数学公式还有编程语言上,这样不仅容易让你气馁,而且特别容易磨光热情。
当我们认识复杂新事物时,最舒适的路径应当是:感性认识现象->理解本质和原理->将所学知识用于解释新现象并指导实践。
所以我给出的这条路径是:先学会如何使用大模型,然后了解其背后的原理,最后探索如何将其应用于实际问题。
作为一个普通人,把大模型用起来
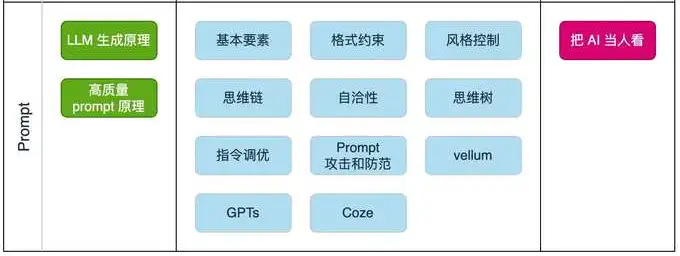
如果说大模型像一个矿藏,那么 prompt 就像是一把铲子,从哪个角度挖,如何挖,决定了你能开采出什么内容。
一个清晰有效的 prompt 包含角色、任务目标、上下文、输出要求、限定条件、理想示例等一系列内容,只有把 prompt 设计好了,大模型才有可能发挥出理想的效果。
推荐 Prompt 模板:
# Role
[设定角色]
# Profile
- author: [作者]
- version: [版本]
- language: [语言]
- description: [描述]
# Skills
- [技能 1]
- [技能 2]
# Goals
- [目标 1]
- [目标 2]
# Constraints
- [限制 1]
- [限制 2]
# Workflow
1. [步骤 1]
2. [步骤 2]
# Output Format
[期望的输出格式]
作为一个程序员,把大模型用起来
学会使用 Copilot、通义灵码之类的 AI 编程工具来提升编码效率。现阶段 AI 辅助编程在代码补全以及注释生成方面表现还不错,因此需要你来把架子搭好、把模块分好。这样无形中还能提高你的架构能力。
建议配置 IDE 插件,如 VS Code 的 GitHub Copilot 或 Cursor,利用 AI 进行单元测试生成、代码重构和遗留代码解释。
作为一个大模型套壳程序员,玩一下
掌握如何调用市面上常见的大模型 API,结合自己的想法实现具体的小任务,这对初学者来说是一个实际操作的好机会。
Python API 调用示例:
import requests
def call_llm(prompt):
url = "https://api.example.com/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type":
}
payload = {
: ,
: [{: , : prompt}],
:
}
response = requests.post(url, json=payload, headers=headers)
response.json()[][][][]
(call_llm())
