AI 提示词工程实战:从模糊指令到精准输出的进阶指南
引言
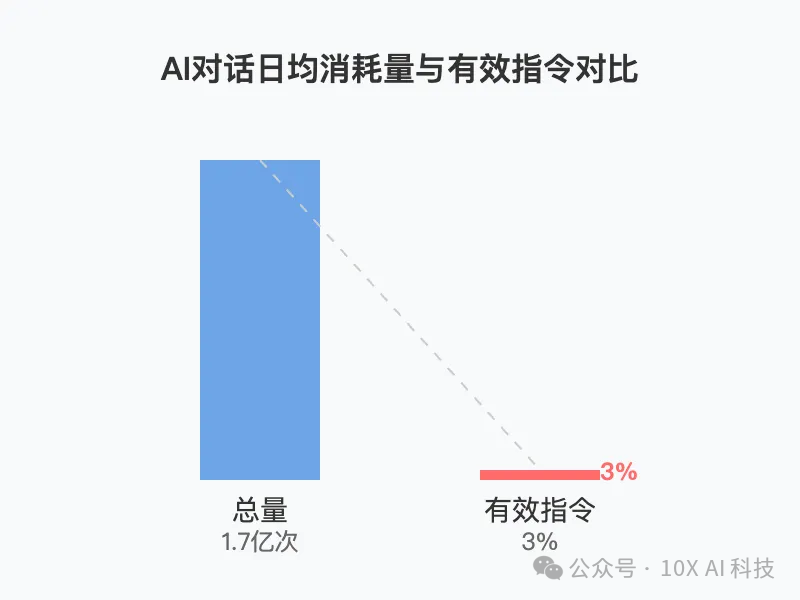
在人工智能技术飞速发展的今天,大语言模型(LLM)已成为提升工作效率的重要工具。然而,许多用户在使用 AI 时仍停留在简单的对话层面,未能充分发挥其潜力。数据显示,大量企业产生的 AI 交互中,有效指令比例不足 3%,大部分效率损耗源于提问方式的不当。
这并非单纯的技术使用差异,而是一场认知能力的竞争。掌握提示词工程(Prompt Engineering),意味着能够更精准地引导模型输出高质量结果,从而在商业决策、内容创作及代码开发中获得显著优势。
一、核心概念:什么是提示词工程?
提示词工程是指通过设计、优化输入给大模型的文本指令,以获取预期输出的过程。它不仅仅是写一句话,而是涉及对模型理解能力、上下文窗口、参数配置的综合运用。
1.1 为什么需要结构化提示词?
大模型基于概率预测下一个 token,缺乏真正的逻辑推理能力。模糊的指令会导致模型产生幻觉或偏离主题。结构化的提示词通过明确角色、任务、约束和格式,降低了不确定性。
对比示例:
- 低效指令:帮我写个营销方案。
- 高效指令:你是一名拥有 10 年经验的数字营销专家。请为一款面向 Z 世代的智能手表撰写一份抖音推广方案。要求包含目标受众分析、核心卖点提炼、三个创意脚本大纲及预算分配建议。输出格式为 Markdown 表格。
1.2 提示词的四大要素
一个高质量的提示词通常包含以下四个维度:
- 角色设定 (Role):定义 AI 的身份,如'资深 Python 工程师'、'医疗领域顾问'。
- 任务描述 (Task):清晰说明需要完成的具体工作。
- 约束条件 (Constraints):限制输出范围、风格、长度或禁止事项。
- 输出格式 (Format):指定结果的呈现方式,如 JSON、Markdown、列表等。
二、进阶技巧:提升输出质量的方法论
2.1 思维链 (Chain of Thought)
对于复杂问题,直接要求答案往往效果不佳。引导模型分步思考可以显著提升准确性。
示例: 不要只问:'这个数学题的答案是多少?' 改为:'请先列出解题步骤,分析已知条件,逐步推导,最后给出结论。'
2.2 少样本学习 (Few-Shot Prompting)
提供几个输入输出的示例,能让模型快速模仿特定模式。
用户:将这句话翻译成英文。
助手:Hello, world!
用户:你好,世界。
助手:Hello, world!
用户:早上好。
助手:Good morning.
2.3 参数调优
在实际 API 调用中,调整模型参数能改变输出特性:
- Temperature:控制随机性。0.0 最确定,1.0 最多样。创意写作可设为 0.7,代码生成建议 0.2。
- Top_P:核采样阈值,限制候选词范围。
- Max Tokens:限制生成长度,防止截断。
三、实战案例:Python 集成与自动化
在实际开发中,我们常需将提示词工程集成到工作流中。以下是一个使用 Python 调用大模型 API 的基础示例,展示了如何动态构建提示词并处理响应。
3.1 环境准备
确保已安装必要的库:
pip install requests python-dotenv
3.2 代码实现
import os
requests
json
dotenv load_dotenv
load_dotenv()
API_KEY = os.getenv()
BASE_URL =
():
prompt =
prompt.strip()
():
headers = {
: ,
:
}
payload = {
: ,
: [{: , : prompt}],
: temperature,
:
}
response = requests.post(BASE_URL, headers=headers, json=payload)
response.status_code == :
data = response.json()
data[][][][]
:
Exception()
__name__ == :
role =
task =
constraints =
user_input =
full_prompt = generate_prompt(role, task + + user_input, constraints)
:
result = call_llm(full_prompt)
(result)
Exception e:
()
