阿里巴巴通义千问团队发布了Qwen2系列开源模型,该系列模型包括 5 个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的Llama3-70B等大模型。
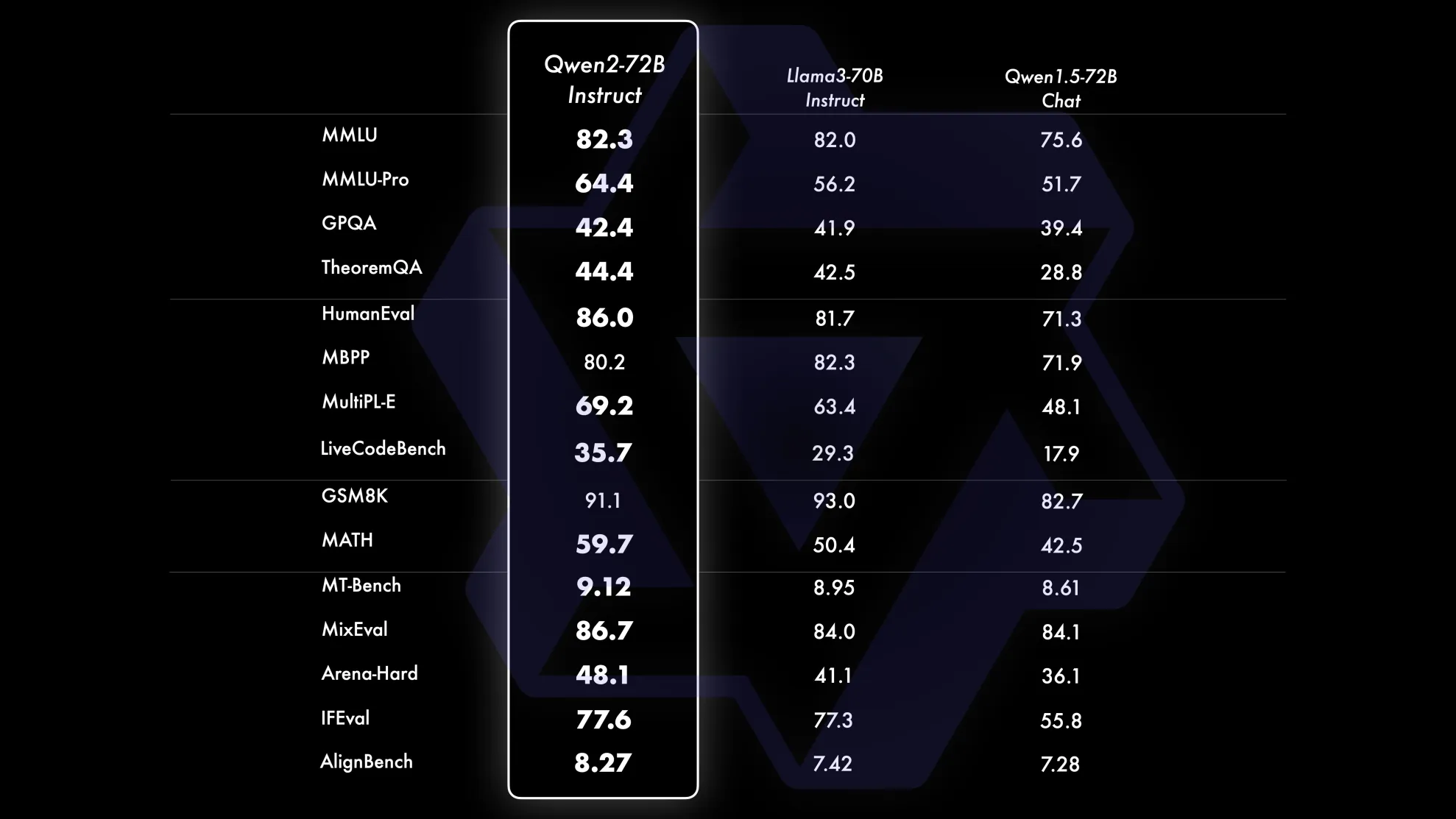
本文将部署和体验Qwen2-7B-Instruct指令微调的中等尺寸模型,相比近期推出同等规模的开源最好的Llama3-8B、GLM4-9B等模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。

特别注意: 虽然Qwen2开源了,但仍然需要遵循其模型许可,除Qwen2-72B依旧使用此前的Qianwen License外,其余系列版本模型,包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B以及Qwen2-57B-A14B等在内,均采用Apache 2.0许可协议。
下载 Qwen2-7B-instruct 模型文件
为了简化模型的部署过程,我们直接下载 GGUF 文件。
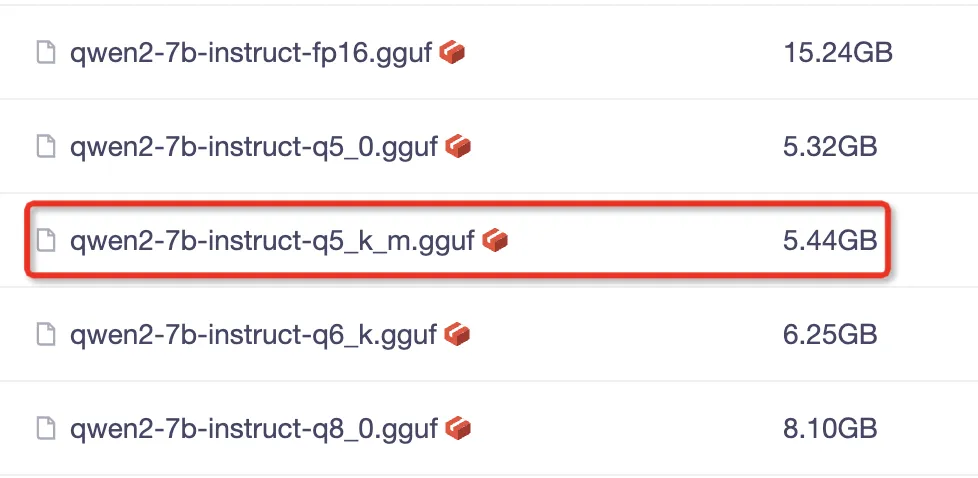
我们可以根据自己需要,选择下载其它版本的模型文件!
启动 Qwen2-7B-Instruct 大模型
GGUF 模型量化文件下载完成后,我们就可以来运行Qwen2-7B大模型了。
在启动Qwen2-7B大模型之前,我们首先需要安装 Python 依赖包列表:
pip install llama-cpp-python
pip install openai
pip install uvicorn
pip install starlette
pip install fastapi
pip install sse_starlette
pip install starlette_context
pip install pydantic_settings
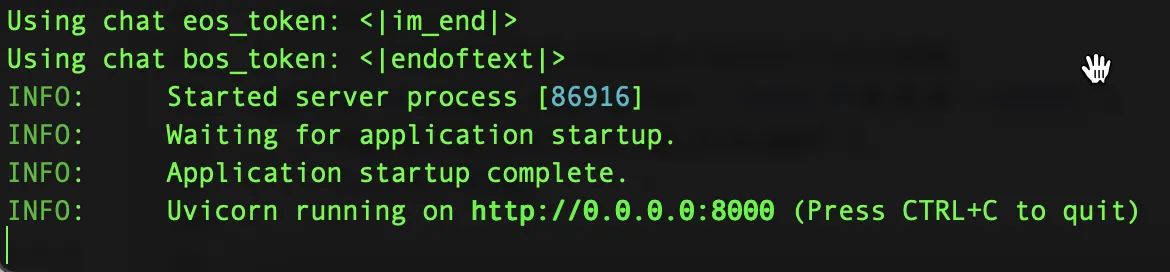
然后打开一个 Terminal 终端窗口,切换到 GGUF 模型文件目录,启动Qwen2-7B大模型(./qwen2-7b-instruct-q5_k_m.gguf即为上一步下载的模型文件路径):
# 启动 Qwen2 大模型
python -m llama_cpp.server \
--host 0.0.0.0 \
--model ./qwen2-7b-instruct-q5_k_m.gguf \
--n_ctx 20480