AI 大模型基础:LLM 核心概念与架构解析
1. 主流开源模型体系概述
目前主流的开源大型语言模型(LLM)体系主要包括以下几类,它们在架构设计和应用场景上各有侧重:
- GPT(Generative Pre-trained Transformer)系列:由 OpenAI 发布的一系列基于 Transformer 解码器架构的语言模型。包括 GPT、GPT-2、GPT-3 等。GPT 模型通过在大规模无标签文本上进行预训练,然后在特定任务上进行微调,具有很强的生成能力和语言理解能力。其核心特点是单向自回归生成。
- BERT(Bidirectional Encoder Representations from Transformers):由 Google 发布的一种基于 Transformer 编码器架构的双向预训练语言模型。BERT 模型通过在大规模无标签文本上进行掩码语言建模(MLM)预训练,然后在下游任务上进行微调,具有强大的语言理解能力和表征能力,适用于分类、抽取等判别式任务。
- XLNet:由 CMU 和 Google Brain 发布的一种基于 Transformer 架构的自回归预训练语言模型。XLNet 模型通过置换语言建模方式预训练,可以建模全局依赖关系,解决了 BERT 中 MLM 任务独立性假设的问题,具有更好的语言建模能力和生成能力。
- RoBERTa:由 Facebook 发布的一种基于 Transformer 架构的预训练语言模型。RoBERTa 模型在 BERT 的基础上进行了改进,去除了下一句预测任务,使用更大规模的数据和更长的训练时间,动态调整掩码策略,取得了更好的性能。
- T5(Text-to-Text Transfer Transformer):由 Google 发布的一种基于 Transformer 架构的多任务预训练语言模型。T5 模型将所有 NLP 任务统一为文本到文本的形式,通过在大规模数据集上进行预训练,可以用于多种自然语言处理任务,如文本分类、机器翻译、问答等。
- LLaMA 系列:由 Meta 发布的轻量级高效模型系列,包括 LLaMA、LLaMA2 等。采用 Decoder-only 架构,通过高质量语料训练,在推理效率和多语言能力上表现优异,是目前开源社区最活跃的模型之一。
这些模型在自然语言处理领域取得了显著的成果,并被广泛应用于各种任务和应用中。
2. Prefix LM 和 Causal LM 区别详解
Prefix LM(前缀语言模型)和 Causal LM(因果语言模型)是两种不同类型的语言模型,它们的区别在于生成文本的方式和训练目标。
2.1 Prefix LM(前缀语言模型)
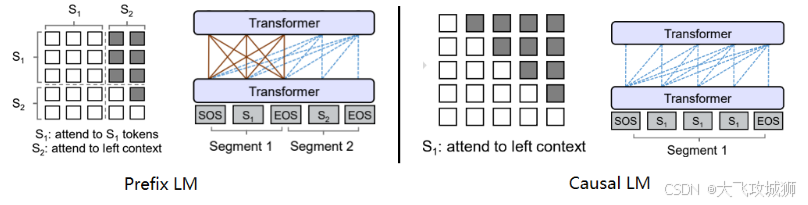
Prefix LM 其实是 Encoder-Decoder 模型的变体。在标准的 Encoder-Decoder 模型中,Encoder 和 Decoder 各自使用一个独立的 Transformer;而在 Prefix LM,Encoder 和 Decoder 则共享了同一个 Transformer 结构,在 Transformer 内部通过 Attention Mask 机制来实现。
与标准 Encoder-Decoder 类似,Prefix LM 在 Encoder 部分采用 Auto Encoding (AE-自编码) 模式,即前缀序列中任意两个 token 都相互可见,而 Decoder 部分采用 Auto Regressive (AR-自回归) 模式,即待生成的 token 可以看到 Encoder 侧所有 token(包括上下文) 和 Decoder 侧已经生成的 token,但不能看未来尚未产生的 token。
Prefix LM 的代表模型有 UniLM、GLM。这种架构允许模型在生成时利用左侧的前缀信息和右侧的上下文信息,适合需要双向理解的生成任务。
2.2 Causal LM(因果语言模型)
Causal LM 是因果语言模型,目前流行的大多数模型都是这种结构。因为 GPT 系列模型内部结构就是它,还有开源界的 LLaMa 也是。
Causal LM 只涉及到 Encoder-Decoder 中的 Decoder 部分,采用 Auto Regressive 模式。直白地说,就是根据历史的 token 来预测下一个 token,也是在 Attention Mask 这里做的手脚。在 Causal LM 中,每个 token 只能看到它之前的 token,无法看到未来的信息,这保证了生成过程的因果性。
2.3 总结对比
- Prefix LM:前缀语言模型是一种生成模型,它在生成每个词时都可以考虑之前的上下文信息以及部分后续信息。在生成时,前缀语言模型会根据给定的前缀(即部分文本序列)预测下一个可能的词。这种模型可以用于文本生成、机器翻译等任务,兼顾了理解与生成。
- Causal LM:因果语言模型是一种自回归模型,它只能根据之前的文本生成后续的文本,而不能根据后续的文本生成之前的文本。在训练时,因果语言模型的目标是预测下一个词的概率,给定之前的所有词作为上下文。这种模型可以用于文本生成、语言建模等任务,更适合纯生成场景。
