大语言模型(LLM)学习路线与初学者入门指南
前言
大语言模型(Large Language Model, LLM)代表了人工智能领域的最新进展,正在深刻改变软件开发、内容创作及数据分析的方式。对于希望进入这一领域的开发者而言,建立系统的知识体系至关重要。本文旨在为初学者提供一份全面的技术学习路线,涵盖基础要求、核心架构及进阶技术。
一、基础准备
要深入理解并开发基于 LLM 的应用,需要掌握以下基础知识:
1. 开发语言
- Python:目前 AI 领域的首选语言,拥有最丰富的生态库(如 PyTorch, Hugging Face Transformers)。
- C/C++:用于底层性能优化及推理引擎开发,适合对计算效率有极高要求的场景。
2. 数学基础
数学是理解模型原理的基石,重点包括:
- 线性代数:向量、矩阵运算、特征值分解是神经网络数据表示的基础。例如,注意力机制中的 QKV 矩阵乘法即源于此。
- 微积分:理解梯度下降等优化算法需要掌握导数与偏导数的概念,这是模型参数更新的核心。
- 概率论:贝叶斯定理、条件概率帮助理解模型的预测分布及不确定性量化。
- 凸优化:了解目标函数最小化过程,有助于理解训练过程中的收敛性分析。
3. 开发框架
- NumPy:处理多维数组与数值计算的基础工具。
- PyTorch / TensorFlow:主流深度学习框架,用于构建和训练神经网络模型。
- Onnx:模型格式标准,便于跨平台部署。
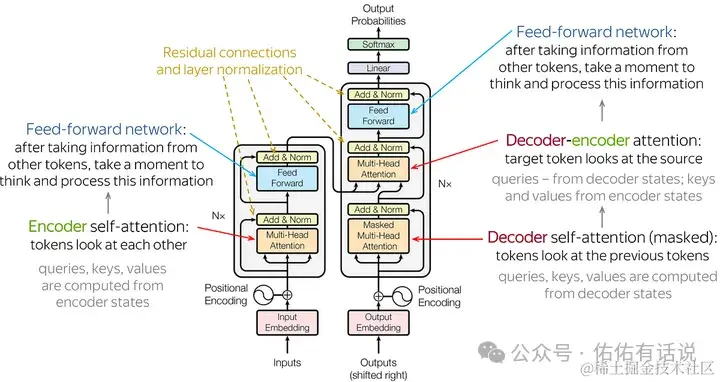
二、核心架构:Transformer
Transformer 是现代 LLM 的基石,其核心在于自注意力机制(Self-Attention),能够捕捉序列数据中的长距离依赖关系。
1. 基本结构
典型的 Transformer 包含 Encoder 和 Decoder 部分,但在 LLM 中通常采用 Decoder-only 架构。主要组件包括:
- Embedding Layer:将词元转换为稠密向量。
- Positional Encoding:注入位置信息,因为 Self-Attention 本身不具备顺序感知能力。
- Multi-Head Attention:并行计算多个注意力头,从不同子空间提取特征。
- Feed Forward Network:逐点前馈网络,增加非线性变换能力。
- Layer Normalization & Residual Connection:加速训练收敛并缓解梯度消失问题。
2. 缩放定律(Scaling Law)
研究表明,随着模型参数量、数据集大小和计算量的增加,模型性能呈现可预测的提升趋势。这解释了为何当前的大模型倾向于'更大'而非更复杂。
三、关键技术栈
在掌握基础后,需针对实际应用场景学习以下技术:
1. Prompt Engineering(提示工程)
通过设计高质量的输入指令引导模型生成预期输出。
- 零样本/少样本学习:无需微调即可利用上下文示例激发模型能力。
- 思维链(Chain of Thought):引导模型分步推理,提升复杂任务准确率。
- 约束控制:明确指定输出格式、长度或风格。
2. RAG(检索增强生成)
解决大模型幻觉及知识时效性问题。
