LLM 架构解析:为何主流大模型偏好 Decoder-Only 设计
在人工智能领域,大语言模型(Large Language Model, LLM)的架构选择一直是学术界和工业界关注的焦点。许多开发者在接触 LLM 时会产生疑问:为什么大多数现代大模型(如 GPT 系列、Llama 系列)都采用了 Decoder-Only 结构,而不是传统的 Encoder-Decoder 或 Encoder-Only 结构?这背后涉及对 Transformer 机制、数学原理以及工程优化的深刻理解。
1. 语言模型结构概述
要理解这一趋势,首先需要明确三种主要的 Transformer 变体及其应用场景。
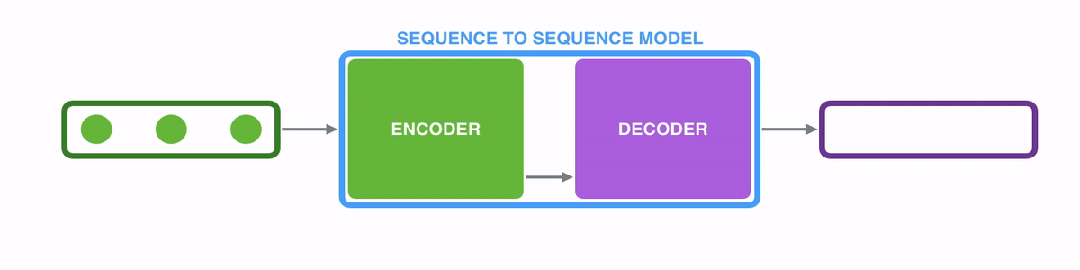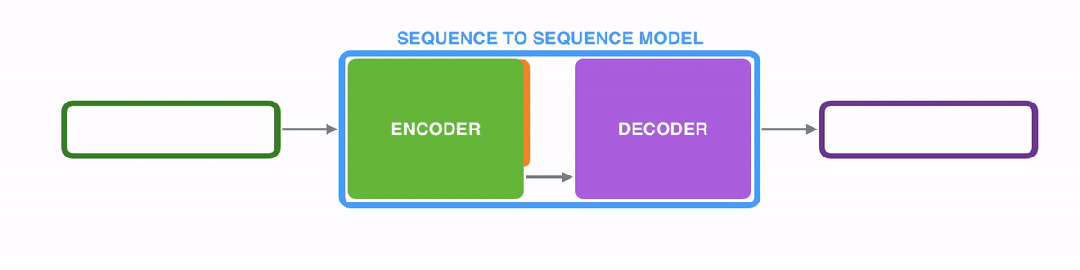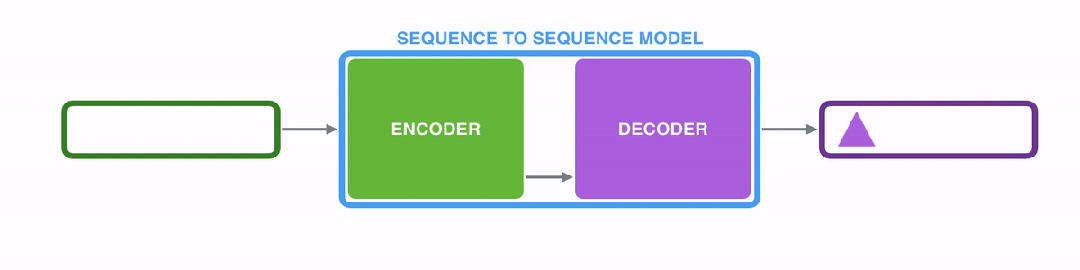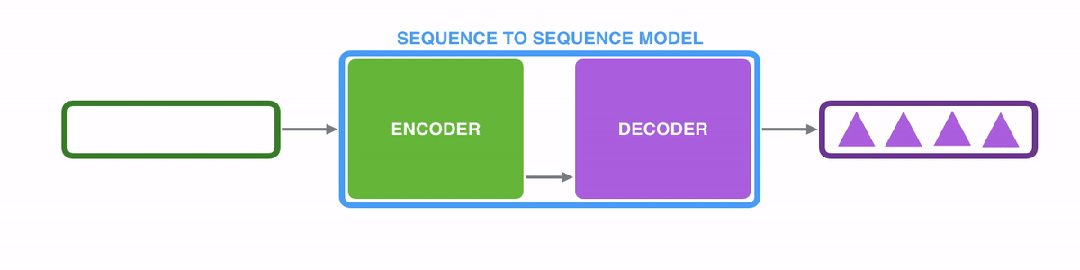
Encoder and Decoder 基础概念
- Encoder(编码器):负责处理输入数据并将其转换为压缩后的特征表示形式,旨在捕捉输入序列中的基本信息和上下文依赖。在机器翻译任务中,编码器将源语言句子(如英语)转换为代表其语言特点和含义的特征编码向量。
- Decoder(解码器):接收编码后的特征表示并生成输出序列,通常与输入形式不同。在上述翻译任务中,解码器接收英语句子的编码表示,逐步生成目标语言句子(如法语)。
三大模型架构对比
| 架构类型 | 典型代表 | 预训练方法 | 主要应用 |
|---|---|---|---|
| Encoder-Only | BERT, RoBERTa | Masked Language Modeling (MLM) | 文本分类、情感分析、信息抽取等需要深入理解输入的任务 |
| Decoder-Only | GPT, XLNet, Llama | Next Token Prediction (NTP) | 文本生成、对话系统、代码生成等自回归任务 |
| Encoder-Decoder | T5, BART, Gemini | Task-dependent / Seq2Seq | 翻译、摘要生成等同时涉及理解和生成的复杂任务 |
针对翻译等生成任务,我们可以首先排除 Encoder-Only 模型。这类模型通常使用 MLM 进行预训练,虽然擅长理解上下文,但不具备直接生成输出的能力。相反,Decoder-Only 模型专为生成输出设计,基于下一个 Token 预测任务进行预训练,这与大多数 LLM 的核心任务高度契合。
因此,问题的核心归结为:Decoder-Only 架构与 Encoder-Decoder 架构的对比。有了 Decoder 组件就有了生成能力,增加 Encoder 组件是否真的能带来显著的性能提升?
2. Causal-Decoder VS Encoder-Decoder 性能研究
关于纯解码器(Causal-Decoder)与 Encoder-Decoder 模型的性能对比,相关研究由来已久。Wang 等人在 ICML 2022 上发表的研究比较了各种架构和预训练方法的组合,得出了关键结论:
实验表明,在纯粹的自监督预训练后,根据自回归语言建模目标训练的纯因果解码器模型表现出最强的零样本泛化能力。
然而,对于具有非因果可见性的输入任务,先使用基于掩码语言建模目标训练,然后进行多任务微调的模型性能最好。
这意味着,如果目标是构建一个通用的、具备强大泛化能力的模型,Decoder-Only 是更优的选择。但如果任务特定且拥有大量标注数据,Encoder-Decoder 经过微调后可能表现更佳。
3. 训练成本与数据效率
实现 Encoder-Decoder 结构的最大潜力,通常需要大量的标注数据进行多任务微调(Instruction Tuning)。这对于大型模型而言成本极高,包括数据清洗、标注人力以及计算资源消耗。
