大模型核心任务类型与主要应用场景
随着生成式人工智能技术的飞速发展,大语言模型(LLM)及其多模态变体已展现出强大的通用能力。理解大模型能解决哪些问题,以及如何将其应用于具体场景,是技术选型的关键。以下从多个维度梳理大模型的主要任务类型及应用。
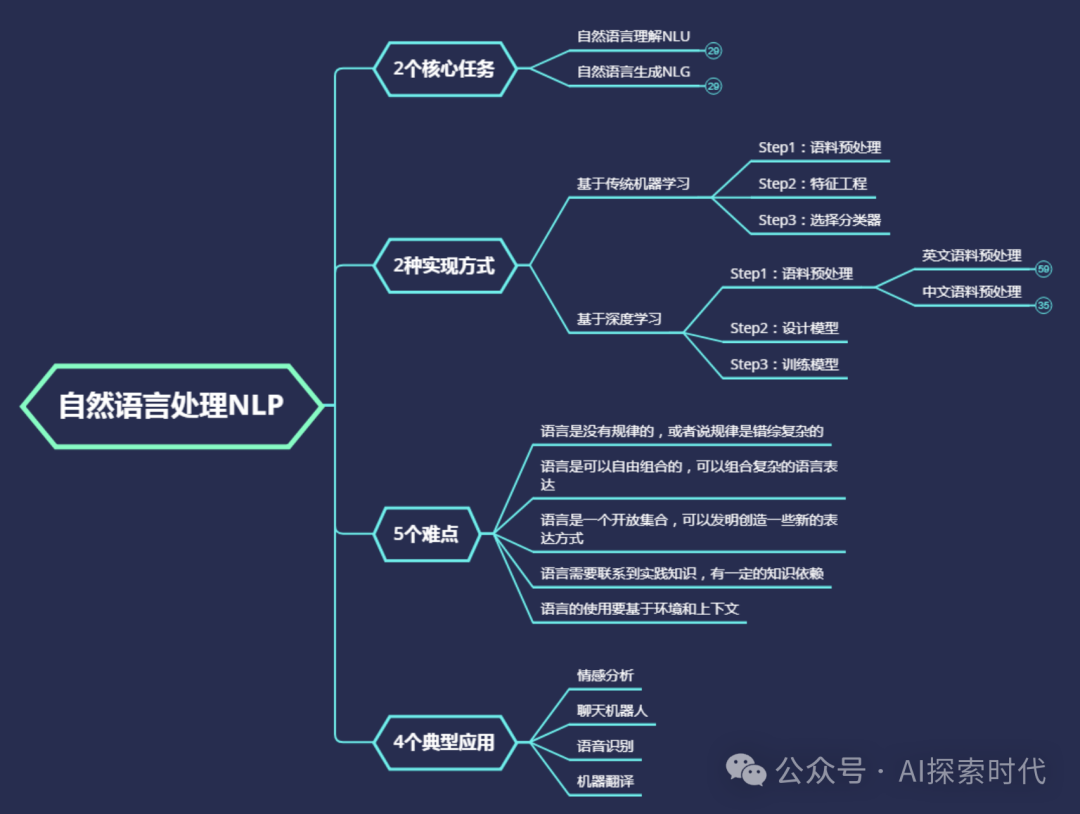
自然语言处理 (NLP)
作为大模型最基础的能力领域,NLP 涵盖理解与生成两个重要子任务。
- 文本生成:生成高质量的文本内容,如文章、诗歌、故事等,广泛应用于内容创作辅助。
- 对话系统:实现智能聊天机器人,与用户进行自然语言对话,常见于客服与虚拟助手。
- 机器翻译:自动翻译不同语言的文本,打破语言障碍,提升跨文化交流效率。
- 文本摘要:提取和生成文本的简要摘要,帮助快速阅读长文档或新闻。
- 情感分析:分析文本中的情感倾向,如正面、负面、中性,用于舆情监控。
- 信息抽取:从文本中提取出有用的信息,如人名、地名、时间等实体及关系。
计算机视觉 (CV)
结合深度学习,大模型在图像领域表现卓越,实现了从感知到生成的跨越。
- 图像分类:对图像内容进行分类,如物体识别、场景分类等。
- 图像生成:生成新图像,如通过扩散模型生成高逼真的人脸或艺术作品。
- 图像分割:将图像中的不同部分进行分割,识别边界,常用于医疗影像分析。
- 图像识别:识别和标注图像中的特定对象或特征,支持安防与检索。
- 图像修复与去噪:修复损坏的图像或去除图像中的噪点,恢复历史照片质量。
语音处理
语音处理连接物理世界与数字世界,是大模型交互的重要入口。
- 语音识别:将语音转换为文本,如语音转写服务,提升办公效率。
- 语音生成:将文本转化为语音,如智能助理的语音输出,增强交互体验。
- 语音增强:改善音频质量,如去除背景噪音,保证通话清晰。
- 语音分离:从混合音频中分离出不同的声源,用于会议记录或音乐制作。
- 语音合成:合成多种声音效果,生成拟真度高的语音内容,降低配音成本。
多模态学习
多模态学习融合文本、图像、视频等多种数据形式,模拟人类综合感知能力。
- 文本 - 图像生成:根据文本描述生成对应的图像,或根据图像生成描述文本。
- 视频理解:对视频内容进行分析,生成描述或进行场景识别,适用于监控与媒体索引。
- 跨模态检索:通过图像查找相关文本,或通过文本查找相关图像,提升搜索精度。
其他关键应用领域
除了基础感知任务,大模型还在复杂决策与专业领域发挥重要作用。
- 推荐系统:个性化推荐根据用户的历史行为推荐商品、电影、音乐等;内容推荐为用户推荐相关文章或视频。
- 数据分析与预测:时间序列预测对股票价格、气象数据等进行趋势预判;分类与回归分析用于客户分类与销售预测;异常检测可发现金融欺诈等行为。
- 强化学习:游戏 AI 训练智能体在游戏中进行自主决策和操作;自动化决策在动态环境中进行最优决策,如机器人导航。
- 代码生成:自动代码补全在编写代码时自动补全代码段;根据自然语言描述生成代码片段;提供代码优化建议并帮助定位和修复错误。
- 知识图谱:从文本中提取实体和关系构建知识图谱;基于知识图谱进行复杂的信息检索与问答。
- 个性化教育:智能辅导根据学生的学习进度提供个性化建议;自动评分对学生的作业或考试进行反馈。
