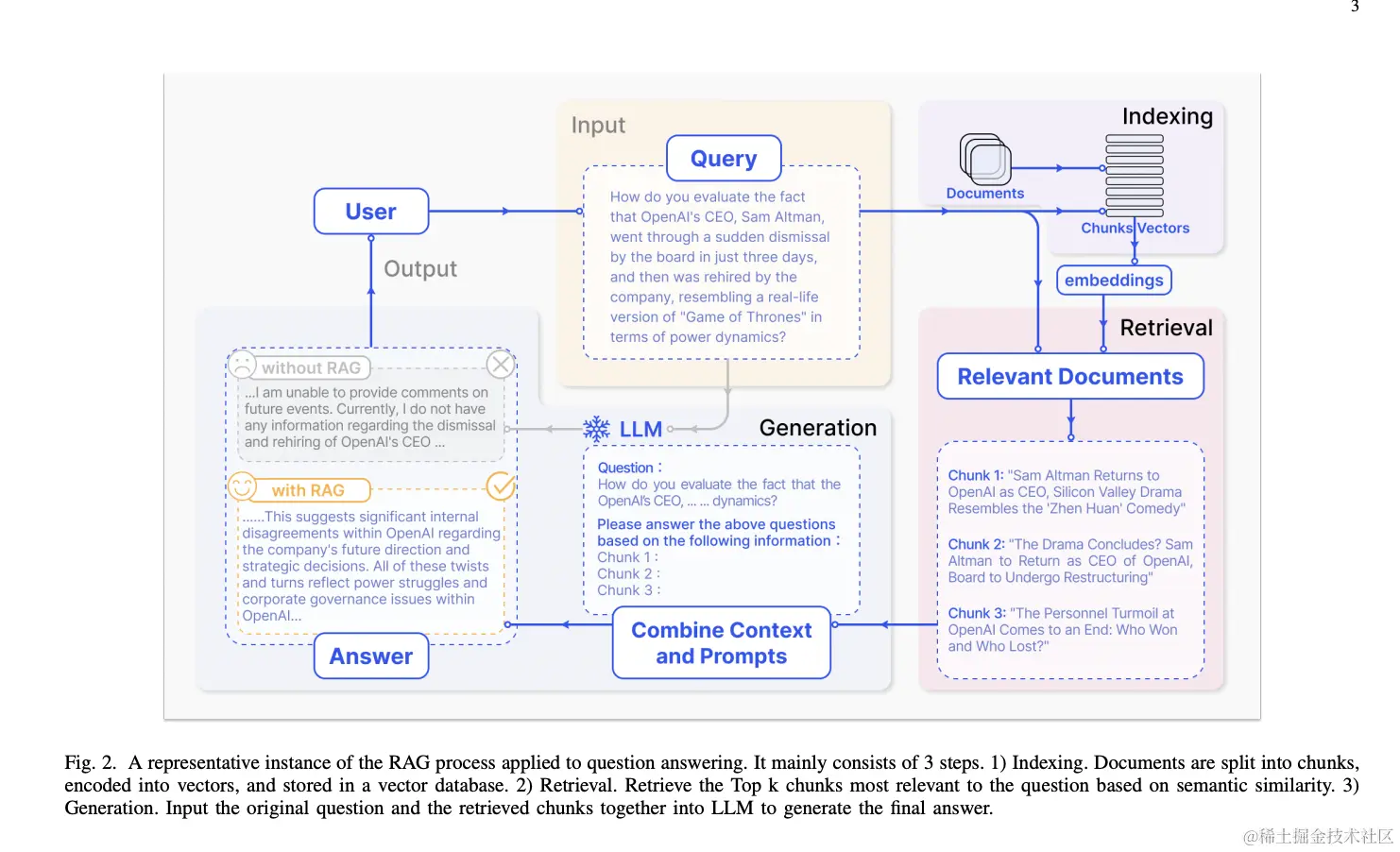
大型语言模型(LLMs)通过在自然语言任务及其它领域的成功应用,如 ChatGPT、Bard、Claude 等所示,已经彻底改变了 AI 领域。这些 LLMs 能够生成从创意写作到复杂代码的文本。然而,LLMs 面临着幻觉、过时知识和不透明、无法追溯的推理过程等挑战。检索增强生成(RAG)作为一种将外部数据库的知识整合进来的有前景的解决方案而出现。这提高了生成内容的准确性和可信度,特别是对于知识密集型任务,并允许持续的知识更新和领域特定信息的整合。
RAG 通过从外部知识库检索相关文档块的语义相似性计算,增强了 LLMs。通过引用外部知识,RAG 有效减少了生成事实不正确内容的问题。其整合到 LLMs 中的应用已经广泛采用,使 RAG 成为推进聊天机器人和增强 LLMs 适用于现实世界应用的关键技术。当用户向 LLM 提问时,AI 模型将查询发送给另一个模型,该模型将其转换为机器可读的数字格式。查询的数字版本有时称为嵌入或向量。RAG 将 LLMs 与嵌入模型和向量数据库结合起来。然后,嵌入模型将这些数字值与可用知识库的机器可读索引中的向量进行比较。当它找到一个或多个匹配项时,它检索相关数据,将其转换为人类可读的文字,并将其传回给 LLM。最后,LLM 将检索到的词语和对查询的响应组合成最终用户看到的答案,可能会引用嵌入模型找到的来源。
初级 RAG
初级 RAG 研究范式代表了最早的方法论,它在 ChatGPT 广泛采用后不久获得了突出地位。初级 RAG 遵循一个传统的过程,包括索引、检索和生成,也被称为'检索 - 阅读'框架。
- 索引阶段:从清理和提取 PDF、HTML、Word 和 Markdown 等多种格式的原始数据开始,然后将其转换为统一的纯文本格式。这一步通常涉及分块(Chunking),即将长文档切分为固定大小或基于语义的段落,以便后续处理。
- 检索阶段:收到用户查询后,RAG 系统使用在索引阶段期间使用的相同编码模型将查询转换为向量表示。然后,它计算查询向量与索引语料库中的块向量之间的相似性分数(如余弦相似度)。系统优先检索与查询最相似的前 K 个块。这些块随后被用作提示中的扩展上下文。
- 生成阶段:提出的查询和选定的文档被综合成一个连贯的提示,LLM 被任务化以形成响应。
然而,初级 RAG 遇到了显著的缺点:
- 检索挑战:检索阶段经常在精确度和召回率上挣扎,导致选择不对齐或不相关的块并丢失关键信息。简单的向量相似度可能无法捕捉复杂的语义关系。
- 生成困难:在生成响应时,模型可能面临幻觉问题,产生与检索上下文不支持的内容。如果检索到的上下文包含噪声,模型容易受到误导。
- 增强障碍:将检索到的信息与不同任务整合可能具有挑战性,有时会导致输出不连贯或不一致。此外,还有一个担忧是生成模型可能过度依赖增强信息,导致输出仅仅是复述检索内容而没有添加有洞察力或综合信息。
高级 RAG
高级 RAG 引入了特定的改进,以克服初级 RAG 的限制。它专注于提高检索质量,采用了预检索和后检索策略。为了解决索引问题,高级 RAG 通过滑动窗口方法、细粒度分割和元数据的整合,改进了其索引技术。此外,它还采用了几种优化方法来简化检索过程。
预检索优化
在这个阶段,主要关注是优化索引结构和原始查询。优化索引旨在提高被索引内容的质量。这涉及到策略:提高数据粒度、优化索引结构、添加元数据、对齐优化和混合检索。查询优化的目标是使用户的原始问题更清晰、更适合检索。常见方法包括查询重写、查询转换、查询扩展和其他技术。例如,HyDE(Hypothetical Document Embeddings)通过让模型先生成假设答案再检索,可以提高检索的相关性。
后检索优化
检索完成后,可以通过重排序(Re-ranking)来进一步优化结果。Cross-Encoder 模型可以对候选文档进行更精细的评分,从而提升 Top-K 结果的准确性。混合检索结合关键词搜索(BM25)和向量搜索,能够兼顾语义匹配和精确术语匹配。
模块化 RAG
模块化 RAG 架构超越了前两个 RAG 范式,提供了增强的适应性和多样性。它整合了多种策略来改进其组件,例如添加搜索模块进行相似性搜索和通过微调来精炼检索器。为了应对特定挑战,引入了重构的 RAG 模块和重新排列的 RAG 流程的创新。向模块化 RAG 方法的转变正在变得普遍,支持顺序处理和跨其组件的集成端到端训练。尽管具有独特性,模块化 RAG 仍然建立在高级和初级 RAG 的基本原则之上,展示了 RAG 家族内的进步和精炼。
新模块
模块化 RAG 框架引入了额外的专门组件,以增强检索和处理能力。
- 搜索模块:适应特定场景,使得可以直接跨各种数据源(如搜索引擎、数据库和知识图谱)进行搜索,使用 LLM 生成的代码和查询语言。
- RAG-Fusion:通过采用多查询策略,将用户查询扩展到不同视角,利用并行向量搜索和智能重新排序来揭示显式和变革性知识,解决了传统搜索的限制。
- :利用 LLM 的记忆来指导检索,通过迭代自我增强创建一个与数据分布更紧密对齐的无界记忆池。
