基于知识图谱的 GraphRAG 非结构化数据处理:LlamaIndex 与 Neo4j
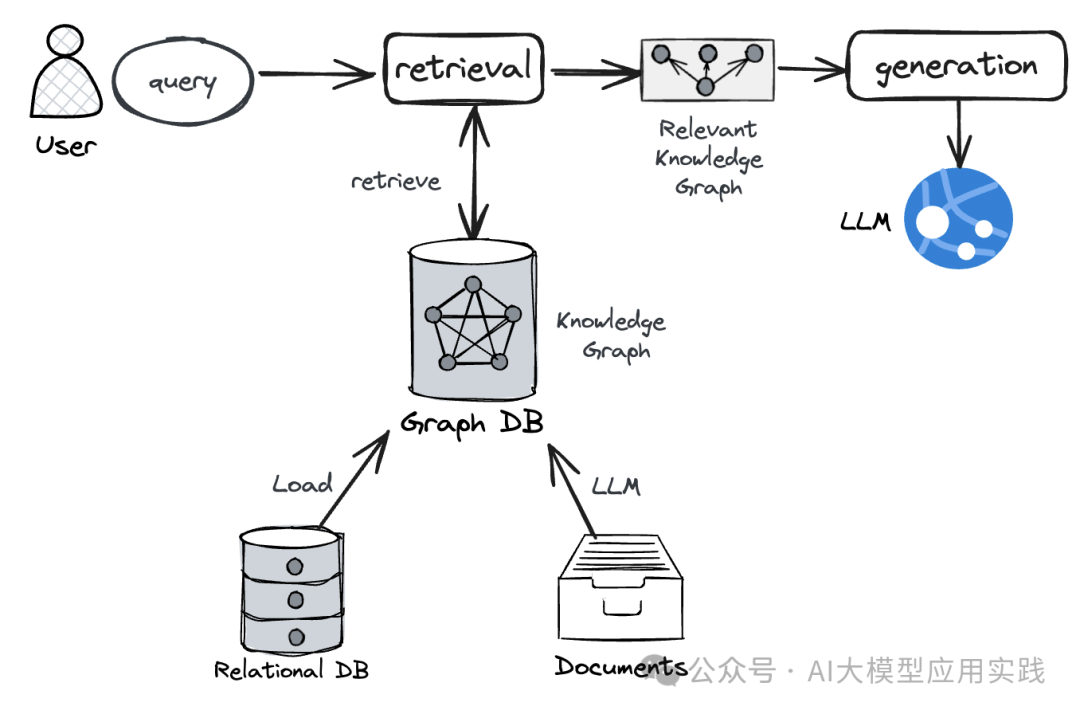
上篇简单介绍了构建 GraphRAG 的动机与架构。GraphRAG 的基础架构源自基于向量的经典 RAG 的转换。我们已经演示了如何把传统关系型数据库中的结构化知识转为知识图谱并用于 RAG 查询。本篇我们将关注非结构化数据,以一个简单的自然语言文本为例,了解如何借助 LLM 的开发框架来构建 GraphRAG 应用。
生成基于 Graph 的知识图谱
构建一个非结构化数据的 GraphRAG 应用,首要任务是把非结构化数据转换成以图结构表示的知识图谱,并存储到 GraphDB 如 Neo4j,用来提供后续检索与生成的基础。从非结构化文本到知识图谱,借助 LLM 是一种常见的也是最高效的方法:利用 LLM 强大的语义理解与推理能力,从非结构化文本中抽取大量的类似实体 - 关系 - 实体的三元组,并借助必要的接口(如 GraphDB 支持的查询语言)导入到 GraphDB 中创建对应的实体、关系与属性,形成知识图谱。
这里的核心是基于 LLM 而实现的 Extractor,即 Graph 结构的抽取组件。在不同的框架中有不同的组件实现,这里我们以 LlamaIndex 框架为例,其实现的核心组件为 LLMPathExtractor,一般用最简单的 SimpleLLMPathExtractor 进行代码实现即可(如果你熟悉 LangChain,可以研究类似的 LLMGraphTransformer 组件)。
为了更好的测试效果,我们用 LLM 生成了一个架空世界的城市故事作为构建知识图谱的非结构化数据来源。
from llama_index.core import SimpleDirectoryReader, PropertyGraphIndex, StorageContext, load_index_from_storage
from llama_index.graph_stores.neo4j import Neo4jPropertyGraphStore
from llama_index.core.indices.property_graph import SimpleLLMPathExtractor
from openai import OpenAI
import os
llm = OpenAI(model="gpt-4o")
embed_model = OpenAIEmbedding(model_name="text-embedding-3-small")
# 加载数据
documents = SimpleDirectoryReader(input_files=['./dreamcity.txt']).load_data()
# 图数据库
graph_store = Neo4jPropertyGraphStore(
username="neo4j",
password="Unycp123!!",
url="bolt://localhost:7687",
)
# 知识抽取的提示词
prompt = '''
下面提供了一些文本。根据文本,提取最多 {max_knowledge_triplets} 个知识三元组,形式为(实体,关系,实体或属性)。避免使用停用词。仅输出三元组,不要有多余解释和说明。
---------------------
示例:
文本:Alice 是 Bob 的母亲。
三元组:Alice,母亲,Bob
文本:Philz 是 1982 年在伯克利创立的咖啡店。
三元组:
Philz,是,咖啡店
Philz,创立于,伯克利
Philz,创立于,1982 年
--------------------
文本:{text}
三元组:
'''
# 抽取结果的解析
def () -> [[, , ]]:
lines = response_str.split()
triples = [line.split() line lines]
triples
kg_extractor = SimpleLLMPathExtractor(
llm=llm,
extract_prompt=prompt,
max_paths_per_chunk=,
parse_fn=parse_fn,
)
os.path.exists():
index = PropertyGraphIndex.from_documents(
documents,
embed_model=embed_model,
kg_extractors=[kg_extractor],
property_graph_store=graph_store,
show_progress=,
)
index.storage_context.persist()
:
()
storage_context = StorageContext.from_defaults(persist_dir=,property_graph_store=graph_store)
index = load_index_from_storage(storage_context=storage_context)
