Spring AI 集成 Ollama 与 LLaVA 实现多模态大模型应用实战
前言
在人工智能领域,单一数据格式的输入处理已经非常成熟,例如文本到文本的对话模型、文本到图像的图片生成模型等。然而,现实世界的应用往往需要同时处理多种类型的数据格式。多模态(Multimodal)技术正是为了解决这一问题而生,它允许模型同时理解和处理来自不同来源的信息,包括文本、图像、音频和视频。
本文旨在深入探讨如何利用 Spring AI 框架集成本地部署的大语言模型 Ollama,并结合 LLaVA:7b 模型,实现一个支持多模态输入(如图片 + 文本)的 Java 应用程序。我们将涵盖从环境搭建、依赖配置到代码实现的完整流程,并提供详细的调试指南。
什么是多模态大模型
多模态是指模型同时理解和处理来自各种来源的信息的能力。人类的学习方式本质上是多模态的,我们不仅通过视觉获取信息,还结合听觉和文本进行综合理解。现代教育之父约翰·阿莫斯·夸美纽斯曾提出:"所有自然联系的事物都应该结合起来教授"。
传统的机器学习方法通常专注于单一模式的专用模型,这与人类的学习行为相悖。随着技术的发展,新一代的多模态大型语言模型(Multimodal LLMs)开始涌现。这些模型具备与其他模态(如图像、音频或视频)一起处理和生成文本的能力,极大地扩展了 AI 的应用边界。
主流多模态模型支持情况
目前,各大云厂商和本地开源方案均提供了多模态支持:
- OpenAI: gpt-4-visual-preview, gpt-4o
- Google Vertex AI: Gemini Pro Vision
- Anthropic: Claude3
- Ollama (本地): LLaVA, baklava
由于部分云端 API 存在访问限制或成本问题,使用 Ollama 运行本地 LLaVA 模型是一个高性价比且隐私性强的替代方案。
Spring AI 多模态抽象架构
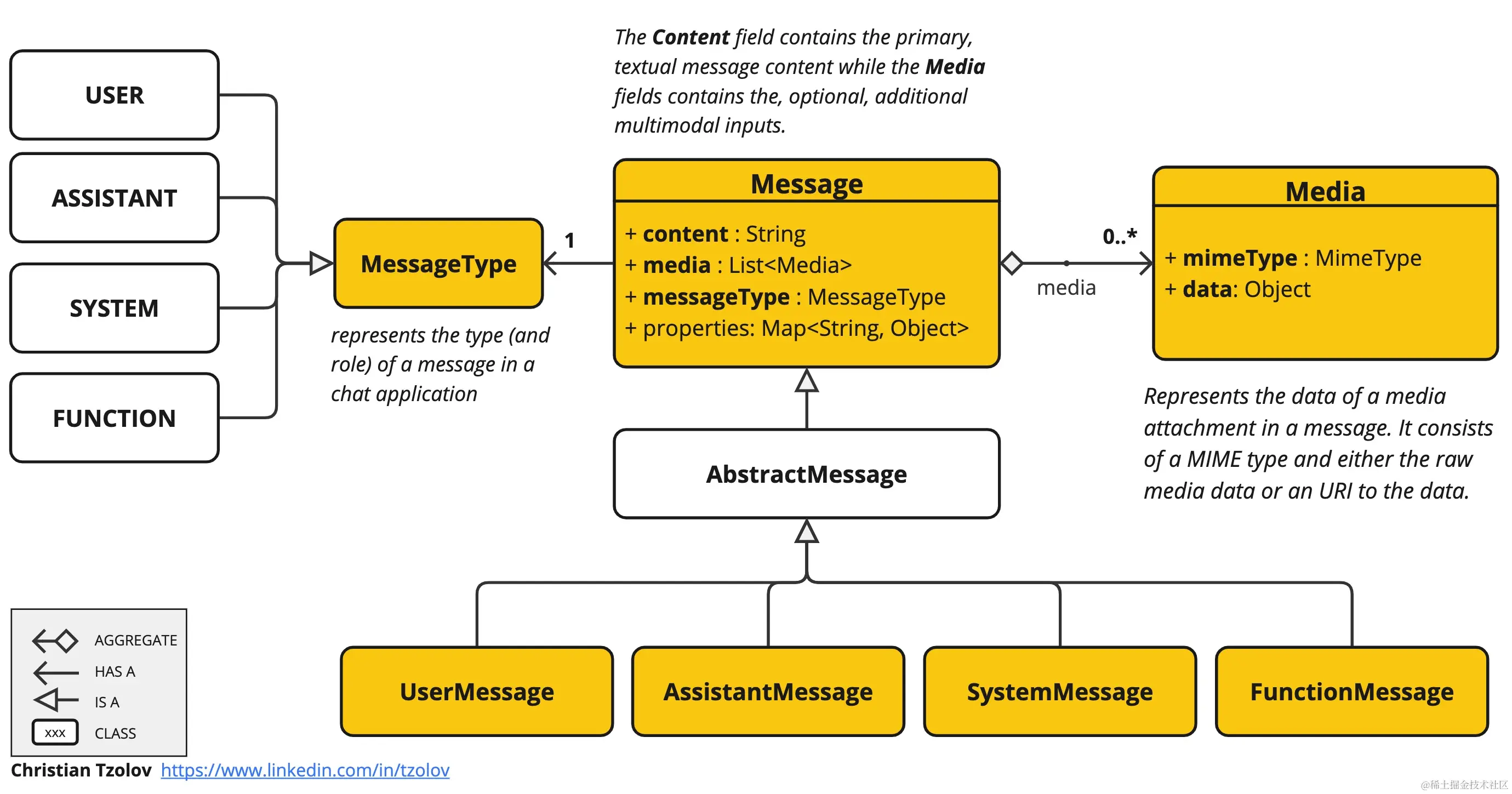
Spring AI Message API 提供了支持多模态的所有必要抽象。其核心在于 Message 对象的设计,使得开发者可以像操作纯文本一样操作包含多媒体内容的消息。
消息结构解析
在 Spring AI 中,消息的 content 字段主要用作文本输入,而可选的 media 字段允许添加一个或多个不同模式的附加内容,例如图像、音频和视频。指定 MimeType 模态类型后,媒体的数据字段可以是编码的原始媒体内容,也可以是内容的 URI。
注意:
media字段目前主要适用于用户输入消息(例如UserMessage),系统消息通常仅包含文本。
这种设计使得上层业务逻辑无需关心底层模型的具体实现细节,只需构建标准的 Prompt 即可调用不同的后端服务。
环境准备与 Ollama 部署
为了演示多模态功能,我们需要在本地部署 Ollama 并拉取 LLaVA 模型。相比云端 API,本地部署能更好地保护数据隐私,且无调用次数限制。
1. 安装 Ollama
请根据您的操作系统选择安装方式:
- macOS / Linux: 运行
curl -fsSL https://ollama.com/install.sh | sh - Windows: 下载官方安装包并运行
安装完成后,确保 Ollama 服务正在运行,默认监听端口为 11434。
2. 拉取 LLaVA 模型
在终端执行以下命令拉取 LLaVA:7b 模型:
ollama pull llava:7b
该模型专为视觉问答任务优化,能够准确描述图片内容并进行推理。
