
PythonAI算法
LangChain 构建代理:工具调用与内存管理
如何使用 LangChain 构建智能代理。通过结合语言模型的工具调用能力,代理可以执行搜索、检索本地知识库及自定义函数等操作。教程涵盖了环境安装、工具定义(如 Tavily 搜索和 FAISS 向量检索)、LLM 绑定、代理创建、流式响应处理以及基于检查点的内存持久化。最终实现了一个能够自主决策并记忆上下文的多工具交互系统。
发布于 2025/2/741 浏览0 点赞
博客作者
自由如风
348
已发布文章
11K
博客获赞
797K
博客浏览
第 17 页
如何使用 LangChain 构建智能代理。通过结合语言模型的工具调用能力,代理可以执行搜索、检索本地知识库及自定义函数等操作。教程涵盖了环境安装、工具定义(如 Tavily 搜索和 FAISS 向量检索)、LLM 绑定、代理创建、流式响应处理以及基于检查点的内存持久化。最终实现了一个能够自主决策并记忆上下文的多工具交互系统。

深入解析了大模型(Large Model/Foundation Model)的核心概念、技术原理及发展趋势。文章首先定义了大模型及其与小模型的区别,重点阐述了涌现能力、巨大规模和泛化性能等特点。接着详细介绍了基于Transformer架构的大模型基本原理,包括Encoder-Decoder、Encoder-Only和Decoder-Only三种主流框架。在训…

详细阐述了 AI Agent 框架中 Runtime 模块的核心设计与实现方案。内容涵盖 Workflow 与 Multi-agent 的典型场景分析,提出了基于 Service、Plan、Context 和 Scheduler 的四层架构模型。重点介绍了 Rust 语言下的 Trait 抽象、异步执行流程、JSON 序列化封装以及异常处理与性能优化策略。此…

详细讲解如何从零开始预训练一个大语言模型,涵盖环境配置、数据清洗、分词器训练、模型训练及推理测试全流程。通过基于《三国演义》文本的实战案例,演示如何使用 Python 生态中的 Transformers 和 Tokenizers 库构建自定义模型,帮助开发者深入理解大模型底层原理与训练细节。内容包括依赖安装、BPE 分词器构建、GPT2 架构模型训练循环编写…

详细解析了 AI 产品经理与通用型产品经理的异同,明确了两者在思考框架上的共性以及在技术思维上的差异。文章阐述了 AI 产品经理所需的核心技能,包括对 AI 应用场景、算法原理、数据质量及评价指标的理解。提供了从全局认知、Python 基础、机器学习理论到大模型应用开发的完整学习路径,并给出了新晋从业者在提问、实践、倾听及轮岗方面的具体建议。最后总结了大模型…

大文本分块是构建 LLM 应用的关键步骤,旨在将长文档分解为语义连贯的片段以优化向量检索效果。详细阐述了分块的核心原理,对比了固定大小、递归、语义等多种分块方法的优缺点及适用场景。通过介绍基于 LangChain 的代码实现示例,指导开发者根据内容性质、嵌入模型特性及查询复杂度选择合适的分块策略。此外,文章还探讨了如何评估不同块大小的性能,并提供了预处理数据…

探讨了大模型训练中流水线并行(PP)的性能评价指标与分析方法。核心指标包括端到端耗时、正反向耗时及 Bubble Ratio(气泡率)。文章详细解析了 Native、GPipe、1F1B、PipeDream 及 Virtual Pipe 五种主流算法的优缺点,指出 1F1B 在显存与效率间的平衡优势。同时强调了张量并行(TP)与流水并行(PP)的配置原则,建…

Reflexion 框架通过引入自我反思机制改进 LLM Agent 的推理能力。文章分析了 ReactReflectAgent 的工作流程,包括 Prompt 设计、迭代逻辑及反思策略实现。重点探讨了如何在 ReAct 基础上增加记忆层防止循环推理,并讨论了 is_correct() 判断在不同任务场景下的适用性。此外,还补充了工程化落地中的 Token…

大型语言模型(LLM)的基本概念及其在自然语言处理中的应用。详细阐述了基于魔搭社区平台的开发环境搭建方法,并通过情感分析案例演示了模型推理的具体代码实现。文章进一步探讨了预训练模型的局限性,提出了微调(Fine-tuning)的必要性及标准流程,包括数据准备、LoRA 适配及评估部署。最后分析了端侧模型、多模态融合等技术趋势,以及 LLM 对开发者工作模式和…

本书通过问答与图解形式,梳理自然语言处理技术发展脉络,涵盖从 N-Gram、Word2Vec 到 Transformer 及 GPT 的核心原理。作者黄佳结合实战项目,指导读者从零搭建语言模型,适合初学者及从业者深入理解大模型构建逻辑与技术细节。

Python 集合与字典是两种重要的内置数据结构。集合用于存储无序且唯一的元素,支持去重及数学集合运算;字典用于存储键值对,通过键快速查找值,适用于配置管理或对象映射。详细讲解了它们的创建方式、常用操作方法(增删改查)、遍历技巧以及性能特点,帮助开发者高效利用这两种结构处理数据。

系统介绍大模型技术的核心概念、学习路径及实战方法。涵盖 Transformer 架构原理、预训练与微调策略、分布式训练方案(如 DeepSpeed)、指令数据构建及行业应用开发。内容包含从数学基础到 LangChain 框架应用的全栈知识,旨在帮助读者掌握大模型全链路开发能力,提升在人工智能领域的竞争力。
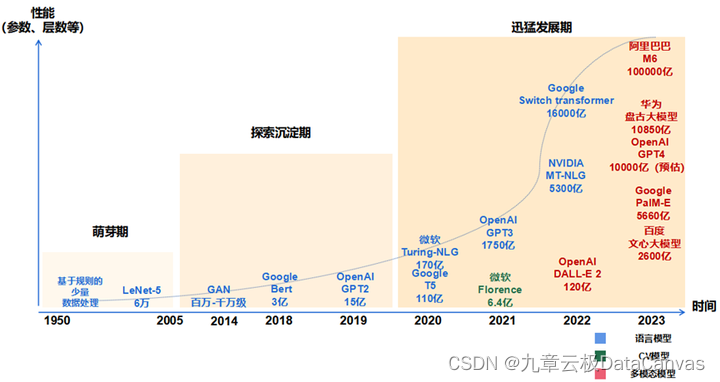
大模型是具有大规模参数和复杂计算结构的机器学习模型。文章阐述了其与小模型的区别,梳理了从 CNN 到 Transformer 再到预训练大模型的发展历程。介绍了语言、视觉及多模态大模型的分类,以及通用、行业、垂直大模型的层级。重点解析了泛化能力与微调技术,包括全量微调与参数高效微调(PEFT),为理解人工智能核心技术提供基础参考。

网络安全入门所需的核心工具安装流程,涵盖 Kali Linux 虚拟机部署、phpStudy 本地环境搭建、Pikachu 漏洞靶场配置以及 BurpSuite 抓包工具的 JDK 环境设置与激活步骤,旨在帮助初学者快速构建安全的渗透测试学习环境。内容包含具体的参数配置、常见问题排查及操作注意事项,适合零基础用户参考。

渗透测试是通过模拟攻击评估系统安全性的方法。涵盖渗透测试标准流程、常用工具(如 Nmap、Burp Suite)、接口与前后端测试方法,以及 SQL 注入、XSS、CSRF、SSRF 等常见漏洞的原理、实例与修复方案。内容包含代码示例、防御最佳实践及伦理规范,旨在帮助技术人员理解安全测试核心概念及应对面试常见问题。

大模型 NLP 开发行业的现状,指出人工智能领域人才紧缺,薪资水平高且对年龄包容度较好。文章详细阐述了该岗位所需的核心技能,包括 Transformer 架构、预训练模型、提示词工程及微调技术。同时提供了从系统设计到行业应用落地的七阶段学习路线,并给出了基于 HuggingFace 和 LangChain 的代码示例,旨在帮助开发者系统掌握大模型开发能力,应…

InternLM2 是新一代开源大语言模型,支持 20 万字超长上下文和工具调用。介绍 InternLM2-Chat-7B 模型的本地化部署流程,涵盖环境准备、Gradio 与 Streamlit 页面交互部署方式,以及基于 Transformers、ModelScope 和 LMDeploy 的代码调用方法。内容包含显存需求分析、启动参数说明及常见错误排查…

如何使用 LLaMA-Factory 框架对大语言模型进行 LoRA 微调。内容涵盖 Base、Chat、Instruct 模型的区别,环境配置步骤,模型下载方法,以及基于 identity.json 数据集的自定义微调流程。文章提供了完整的命令行操作示例,包括推理测试、训练参数详解及结果验证,并补充了显存优化与常见问题排查方案,适合希望掌握大模型微调技术的…

英文大语言模型进行中文指令微调的完整流程。首先阐述了数据构造规范,包括指令、输入和输出的拼接方式,以及 input_ids 和 labels 的构建逻辑,特别解释了 IGNORE_INDEX 的作用。接着分析了 Tokenization 的关键点,如特殊标记的处理和编码解码测试。在模型加载部分,说明了 AutoModel 的使用及 trust_remote_…

Kerberos 协议是一种用于不可信网络上可信主机的身份验证协议,旨在解决开放网络中的安全通信问题。核心目标包括防止密码在网络传输、实现单点登录、支持双向认证及集中管理认证信息。主要组件包括领域、主体、票据、KDC(含 AS 和 TGS)、会话密钥及认证符。流程涉及 AS_REQ、AS_REP、TGS_REQ、TGS_REP 及 AP_REQ 等交互步骤。…