RAG 知识库调优方案深度解析:学术界检索前优化实践
背景介绍
在构建基于大语言模型(LLM)的检索增强生成(Retrieval-Augmented Generation, RAG)系统时,检索质量直接决定了最终回答的准确性和可靠性。工业界常见的开源方案如 QAnything 和 RagFlow 已经提供了基础架构,但学术界针对特定场景的优化研究层出不穷。
本文重点梳理来自学术界的一系列 RAG 优化方案,特别是检索前(Pre-Retrieval)的优化手段。主要关注优化方案对应的设计思想、实现细节以及实际效果评估,旨在为开发者提升 RAG 服务效果提供理论依据和实践参考。所有的实现代码均基于 LangChain 框架完成。
基础架构与分类
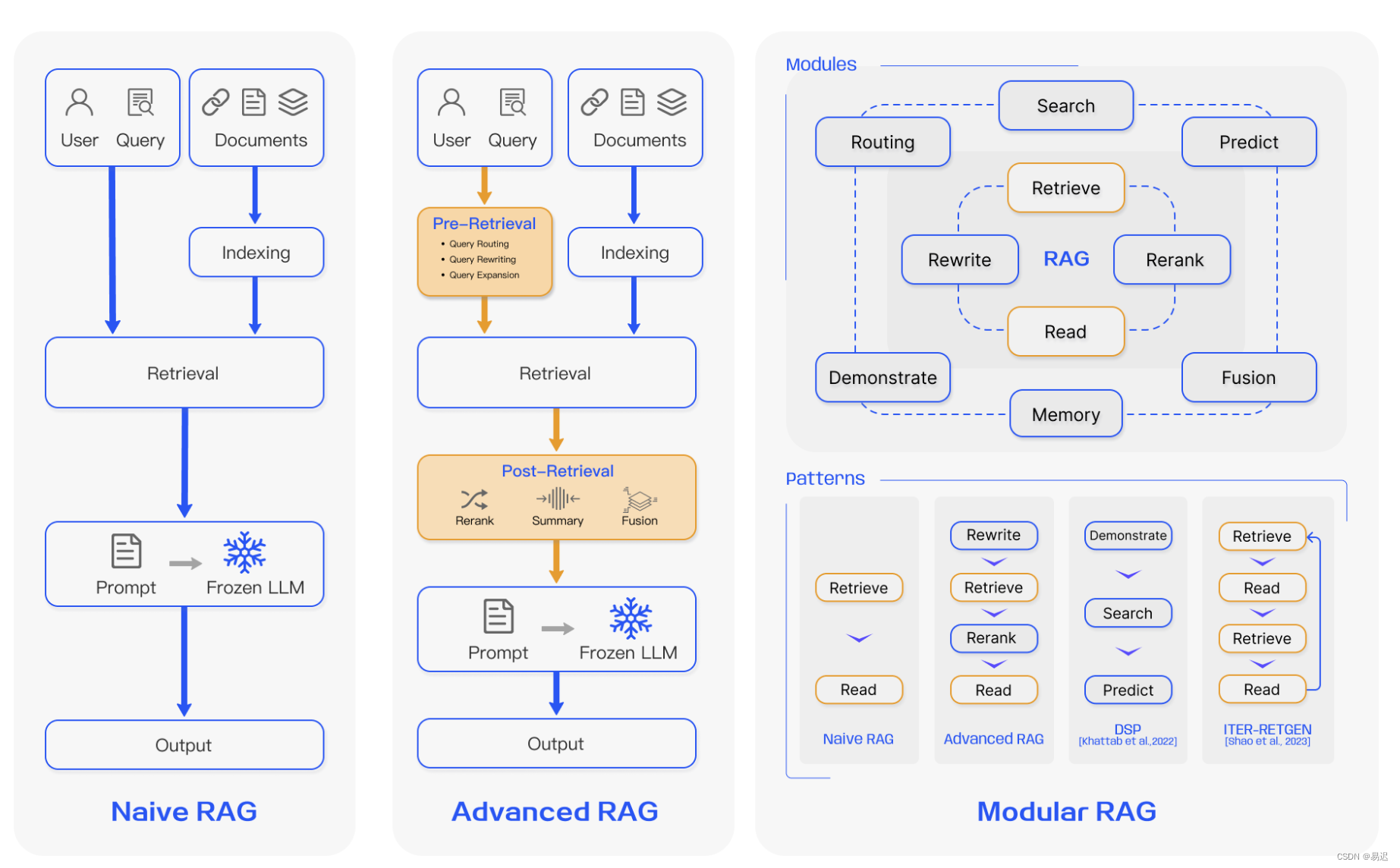
在综述论文《Retrieval-Augmented Generation for Large Language Models: A Survey》中,介绍了三种不同的 RAG 架构:
- Native RAG:原始 RAG 架构,对应最基础的 RAG 流程。即用户提问 -> 向量数据库检索 -> 拼接上下文 -> LLM 生成。这与搭建离线私有大模型知识库的标准流程基本一致。
- Advanced RAG:高级 RAG 架构,在原始 RAG 基础上增加了优化手段。例如之前实践过的 RAG Rerank(重排序)优化手段就属于高级 RAG 中的 Post-Retrieval(检索后优化)阶段。
- Modular RAG:模块化 RAG 架构,通过模块化的架构设计,提供灵活的功能组合,方便实现功能强大的 RAG 服务,允许动态调整检索策略。
本篇文章主要实践的是高级 RAG 架构中的 Pre-Retrieval(检索前优化)手段。目前学术界有大量相关论文研究,本文选择其中几种有代表性的方案进行深度解析和实践。
优化方案详解
1. HyDE (Hypothetical Document Embeddings)
原理分析
HyDE 的优化手段来自于论文《Precise Zero-Shot Dense Retrieval without Relevance Labels》。其核心痛点在于:用户原始的问题通常较短且抽象,与需要检索的文档片段在向量空间中的相似度不接近,导致向量检索效果不佳。
HyDE 的设计思想如下:
- 假设文档生成:根据原始问题使用大模型生成一个假设性的文档(Hypothetical Document)。可以理解为让大模型先'假装'给出答案,此答案中可能存在幻觉,但语义上更接近真实文档的风格。
- 向量检索:基于生成的假设文档进行向量检索,而不是直接使用原始问题。
为什么有效? 直观理解,与大模型生成的答案语义上接近的更有可能是所需的答案。大模型是通过大量原始文档训练出来的,因此生成的假设文档在语言风格和词汇分布上与原始文档更为接近,从而更容易被向量检索模型匹配到。
实现方案
LangChain 已经原生支持了 HyDE,可以通过 from langchain.chains import hyde 进行使用。它提供了一个向量化查询的转换支持。
核心方法逻辑如下:
def embed_query(self, text: str) -> List[float]:
"""
Generate a hypothetical document and embedded it.
1. 通过大模型生成文本对应的响应
2. 将生成的响应向量化
3. 返回用于检索的向量
"""
# 通过大模型生成文本对应的响应
var_name = self.llm_chain.input_keys[0]
result = self.llm_chain.generate([{var_name: text}])
documents = [generation.text generation result.generations[]]
embeddings = .embed_documents(documents)
.combine_embeddings(embeddings)
