写在前面
2023 年 12 月 31 日,第十九届中国图象图形学学会青年科学家会议在广州举行。该会议旨在促进青年科学家之间的交流与合作,提升我国在图像图形领域的科研水平和创新能力。在垂直领域大模型论坛中,多位业内专家对大模型时代文档与图像识别领域的新探索进行了详细介绍。
一、技术难题与挑战
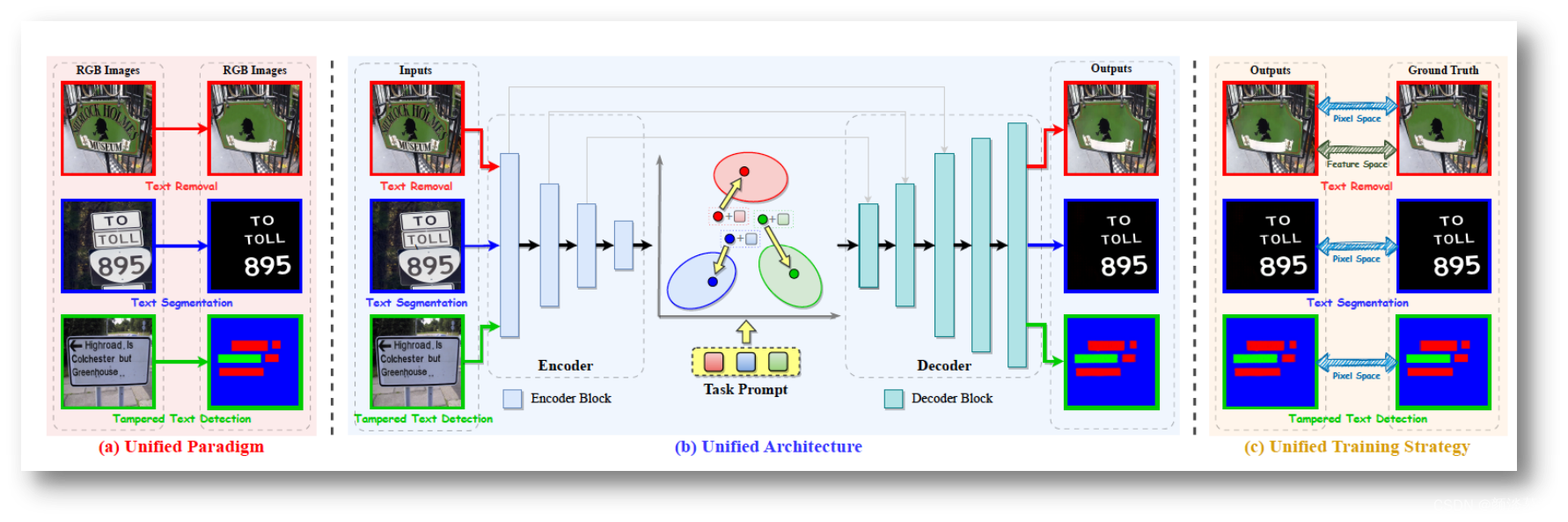
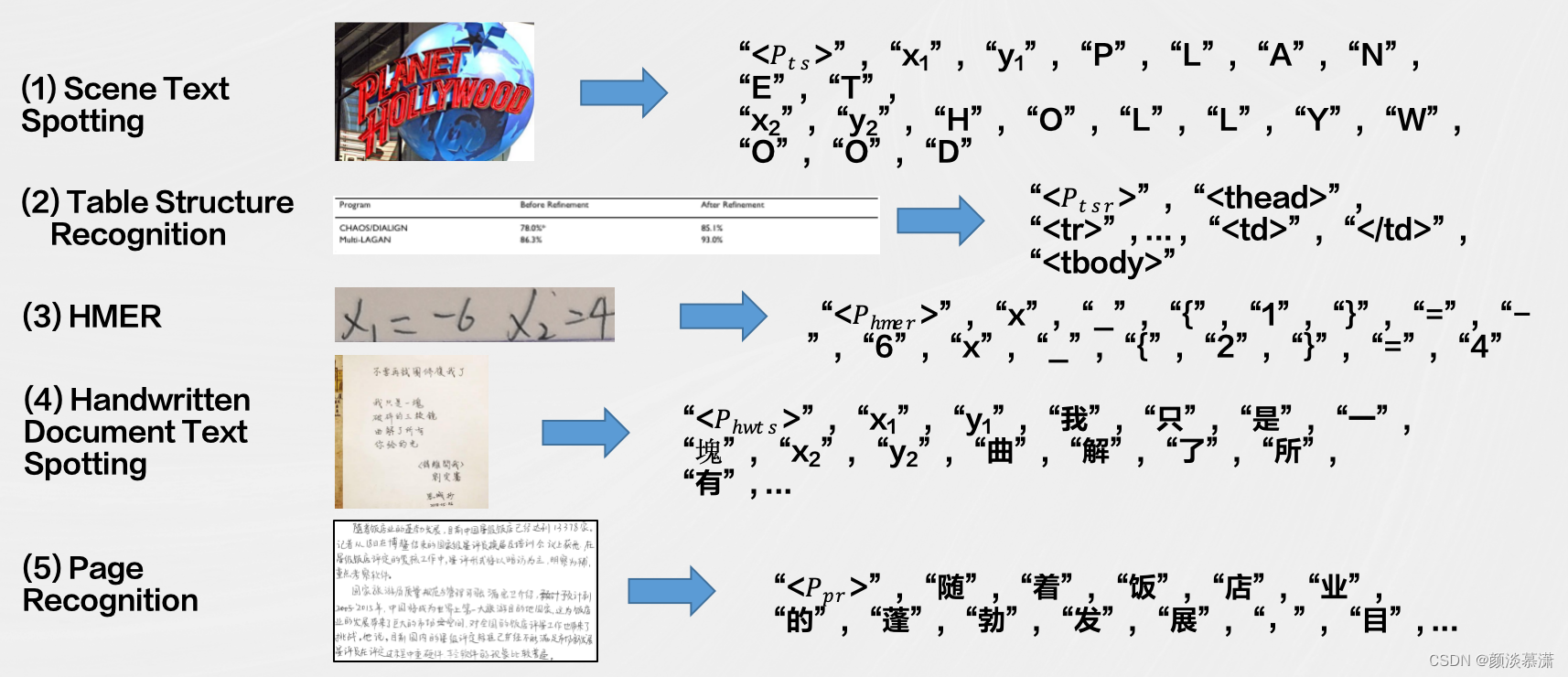
文档图像分析识别与理解是计算机视觉和自然语言处理领域的一个复杂问题,涉及到从图像中提取文本信息、理解文档结构、识别语义等多个层面。主要面临以下技术难题:
- 场景以及版式多样性:文档可能以不同的场景和版式出现,例如室内、室外、手写、打印等。每种场景和版式都可能导致不同的光照、视角、失真等问题,影响识别稳定性。
- 采集设备不稳定性:文档图像可能由不同的设备捕获,如摄像头、扫描仪等,这些设备的性能和参数存在差异,导致图像质量不稳定,噪声干扰较大。
- 用户需求多样性:用户的需求各不相同,有的用户关注文本内容的准确性,而另一些用户更注重图像的布局和格式还原。
- 文档图形质量退化严重性:文档图像可能因为老化、损坏、印刷质量差等原因而质量下降,导致文本和图像的清晰度减弱,增加识别难度。
- 文字检测及排版分析困难:文字可能以不同的字体、大小、方向等形式出现,且可能与其他图像元素重叠或相似,使得文字检测和排版分析变得复杂。
- 非限定条件文字识别率低:在非受限条件下,即不受特定规范或格式的限制,文字识别的难度增加,因为文本可能出现在任何位置、方向和形式。
- 结构化智能理解能力差:对文档结构进行深入理解,包括标题、段落、表格等,是一个复杂的任务,尤其是在处理非结构化文档时,难以自动提取层级关系。

二、ChatGPT-4 模型分析
最新的版本 GPT-4 已经在多项测试中超越了其前身,获得了更高的评分。它是一款高级的人工智能聊天机器人技术,被训练得对各种问题和场景有深入的理解,并且可以生成富有事实性的响应。
2.1 主要特点
- 大规模和高参数:GPT-4 拥有超过 1000 亿个参数,规模远超其他语言模型。这使其具备更强的上下文理解和逻辑推理能力。
- 数据丰富和覆盖广泛:训练数据集非常庞大,包含了大量的自然语言文本,涵盖了多种语言和领域,提升了泛化能力。
- 高精度和高准确性:在图像描述、翻译、生成代码和解答问题等方面的性能都有显著提高。
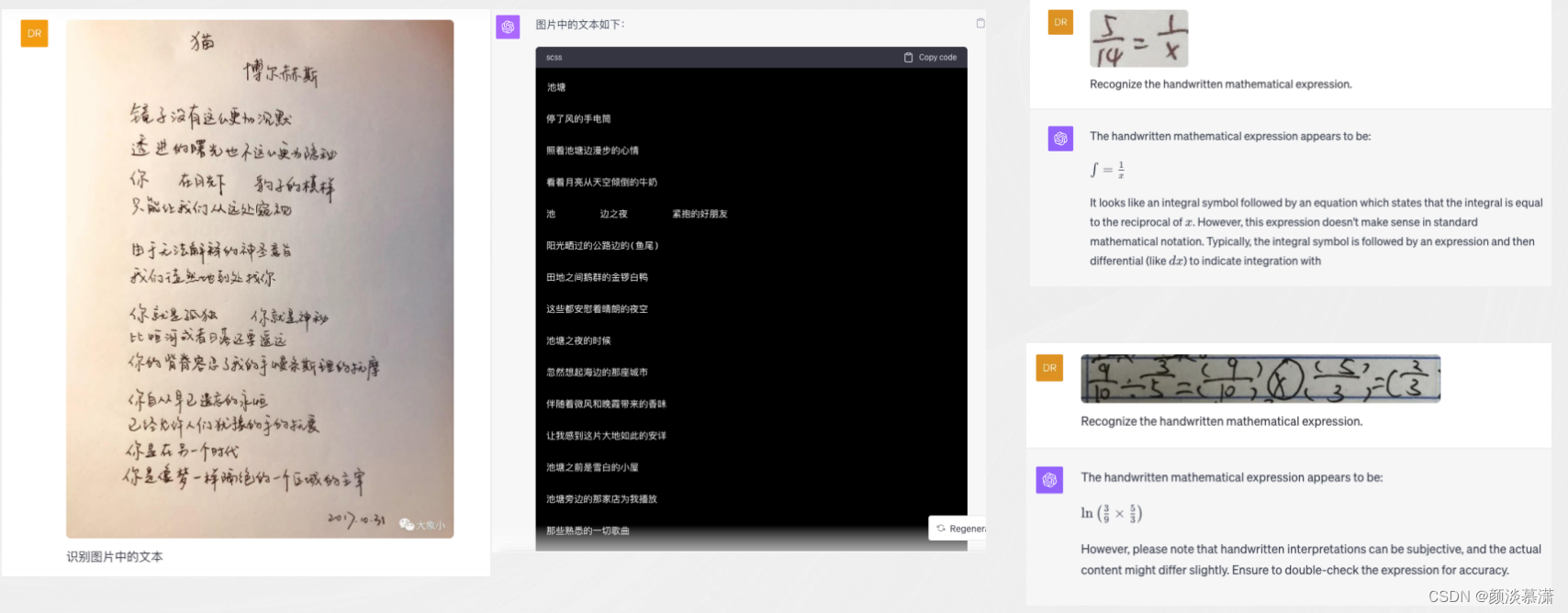
- 多模态能力:GPT-4 不仅可以处理文本信息,还可以处理图像内容。这使得 GPT-4 能够理解和解释图像内容,并将这些信息转化为自然语言。
2.2 在图像领域的优势
GPT-4 在图像识别领域的优势主要体现在以下几个方面:
- 强大的识图能力:拥有卓越的图像理解能力,可以接受图像和文本输入。这不仅使其在处理更复杂的任务时更具优势,也使其在理解和解释图像内容方面具有更高的精确度。
- 零样本效果突出:在多个场景下,GPT-4 的零样本效果超过了之前的 GPT 系列模型,证明了其在图像识别领域的优越性。
- 回答准确性显著提高:与前一代模型相比,GPT-4 在回答问题的准确性上有显著的提高,这对于图像识别任务来说是非常重要的。
- 更强的创造力和灵活性:当任务的复杂性达到一定的阈值时,GPT-4 表现出更可靠的性能,并且能够处理更细微的指令。
- 更高的输入文字限制:将文字输入限制提升至 2.5 万字,这意味着它可以处理更为复杂和详细的图像识别任务。