AI 产品经理需要熟悉 AI 基础知识,包括 AI 行业现状、数学统计学基础、AI 模型构建流程以及模型基本概念。之所以需要具备这些知识,是因为实现 AI 产品必然会涉及相应的 AI 技术。如果 AI 产品经理不了解相应技术基础,就不能很好地和研发人员沟通,也无法有效完成 AI 项目的管理。当然,AI 产品经理并不需要像 AI 算法工程师那样,懂很底层的技术细节或数学公式的逻辑推导,但其中涉及的基本概念和行业现状应有所了解。
AI 行业现状
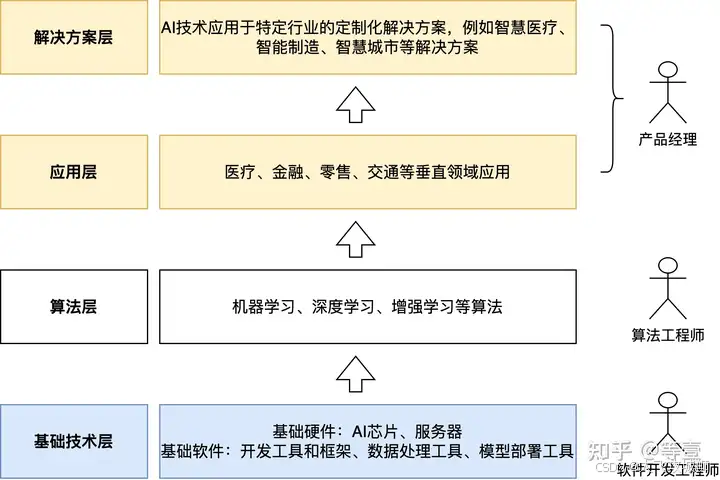
首先需要了解 AI 行业现状。AI 的产业架构通常可以分成基础技术层、算法层、应用层和解决方案层。
1)基础技术层
硬件设备:包括用于 AI 计算的芯片、服务器和设备。例如云计算资源、GPU 加速卡等。 基础软件:包括用于数据处理、模型训练和部署的开发工具和框架,例如 TensorFlow、PyTorch 等框架。
2)算法层
包括机器学习、深度学习、强化学习等核心算法。这是 AI 能力的核心来源。
3)应用层
主要是具体应用场景,包括人工智能在医疗、金融、零售、交通等行业的具体落地。例如金融风控识别系统、智能客服系统、推荐系统等。
4)解决方案层
包括 AI 技术在智能制造、智慧城市等场景的整体解决方案。主要关注如何将 AI 技术与特定行业的业务需求相结合,提供定制化的解决方案,以推动该行业的智能化发展。
其中基础技术层主要负责人员是软件开发团队,算法层负责人通常是算法工程师,而应用层和解决方案层则是 AI 产品经理主要的工作方向。
在 AI 应用层和解决方案层中,涉及到的最新技术就是大模型,目前也是各科技企业竞相追逐的风口。ChatGPT、Gemini、Sora、通义千问等大模型产品层出不穷。基于大模型的 AI 助手已经能实现独立开发任务,最新的 GPT-4o 已具有实时视频和语音功能。掌握大模型工具、紧跟 AI 应用前沿能帮助 AI 产品经理在竞争中脱颖而出。
数学统计学基本概念
数学统计学是人工智能的基础,AI 产品经理应了解并掌握概率论和统计学的基本概念,以便更好地理解数据特征和模型表现。
1)线性代数
线性代数是人工智能和机器学习中的基础数学概念,涉及向量、矩阵、线性方程组等内容。产品经理需要理解常量、向量、矩阵和张量的概念及其在数据表示中的作用。
常量(Scalar):常量是一个单独的数值,比如一个用户的年龄数据或某个特征的权重值。
向量(Vector):向量是一个有序的数值集合,具有大小和方向。比如多个用户的年龄数据集合,或者一张图片展开后的像素序列。
矩阵(Matrix):矩阵是一个二维的数值集合,由行和列组成。矩阵可以看作是向量的推广,其中每个元素都有一个行索引和列索引。在机器学习中,矩阵常用于表示数据集或模型的参数,例如多个用户的年龄和收入数据表、灰度图像的像素值均为二维矩阵。
张量(Tensor):张量是多维的数值集合,张量可以有任意数量的维度。在深度学习和神经网络中,张量是数据在神经网络中传播和处理的基本单位。常量是 0 阶张量,向量是 1 阶张量,矩阵是 2 阶张量,而彩色图片因为有 RGB 三通道,是 3 阶张量。理解张量有助于产品经理与工程师沟通数据输入输出的形状。
2)概率统计
需要重点掌握随机变量和概率分布,了解业务场景下的特征数据和模型结果概率分布情况,有助于产品经理对 AI 模型的验收。例如已知身高是正态分布,但模型输出的结果却不是正态分布的,则需要质疑模型效果。
随机变量(Random Variable):随机变量是描述随机现象结果的数学变量。它可以取多个值,分为离散和连续随机变量两类。 离散随机变量:只能取有限个或可数无限个值的随机变量,如抛硬币的结果(正面或反面)。 连续随机变量:可以取任意实数值的随机变量,如身高、体重、用户停留时长等。
概率分布(Probability Distribution):概率分布描述了随机变量可能取值的概率分布情况,分成离散和连续概率分布两类。
离散概率分布主要有: 二项分布:描述了在一系列独立重复的伯努利试验中成功的次数的概率分布。 泊松分布:用于描述单位时间或空间内随机事件发生次数的概率分布,如网站每秒的请求数。 超几何分布:描述了从有限总体中抽取不放回样本的概率分布。 贝努力分布:描述了只有两种可能结果的单次随机试验的概率分布。 多项式分布:描述了多项试验中每个类别出现次数的概率分布。
连续概率分布主要有: 正态分布:也称为高斯分布,是最常见的连续概率分布,具有钟形曲线。许多自然现象和业务指标都近似服从正态分布。 指数分布:描述了独立随机事件发生时间间隔的概率分布,如用户两次点击之间的时间间隔。 均匀分布:所有数值在一个区间内具有相同的概率密度。 t 分布:用于小样本情况下对总体均值的推断,常用于假设检验。
