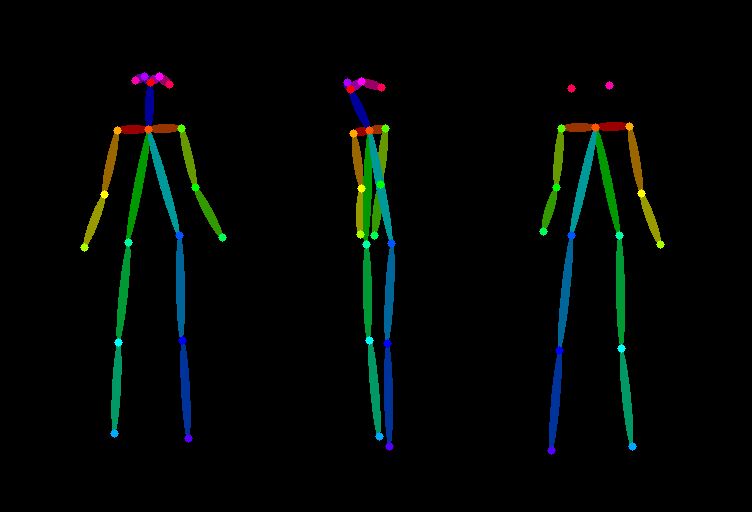
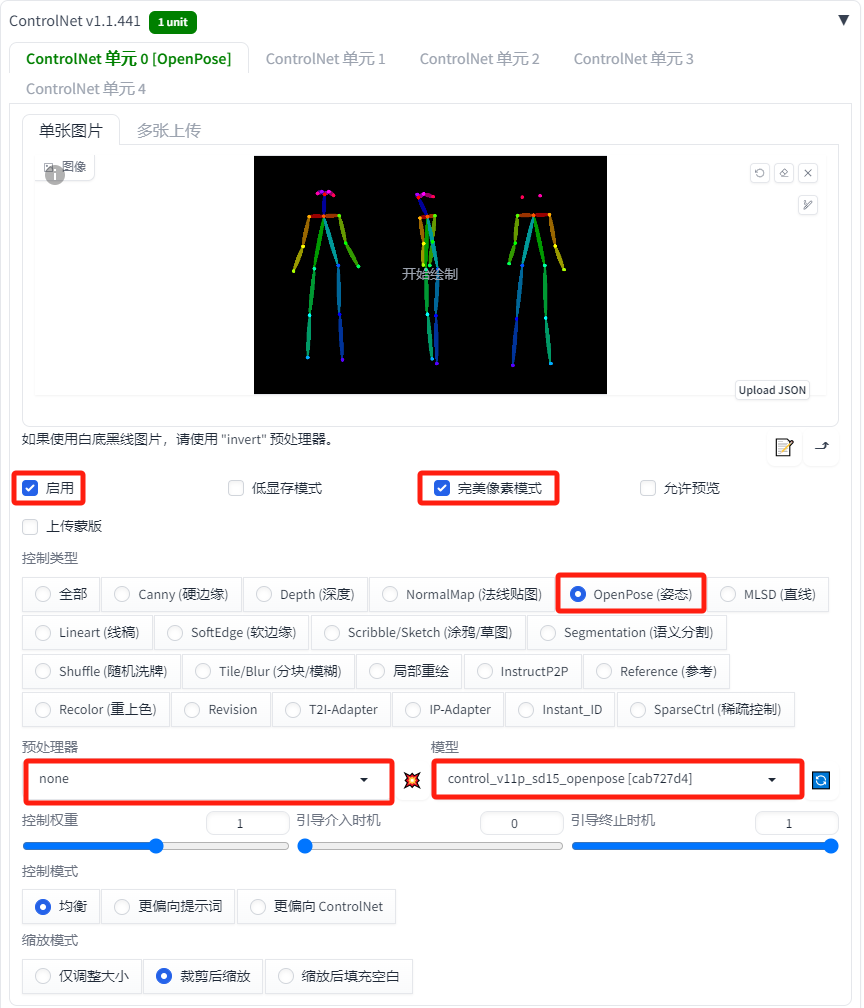
Stable Diffusion 人物三视图制作教程:三种主流实现方案详解
在角色设计、游戏开发及动画制作中,人物三视图(正面、侧面、背面)是基础且关键的需求。随着生成式 AI 技术的发展,Stable Diffusion (SD) 已成为实现这一需求的高效工具。本文将详细探讨三种主流的三视图制作方法,涵盖提示词工程、LoRA 模型应用以及 ControlNet 姿态控制,帮助创作者根据实际需求选择最佳方案。
一、实现方式一:通过提示词直接生成
这是最基础的方法,完全依赖文本提示词引导模型生成三视图。虽然操作简便,但对模型的语义理解能力要求较高。
1. 提示词格式规范
标准的三视图提示词通常包含视角描述、主体特征及质量修饰词。建议格式如下:
(three views of character:1.2), (three views of the same character in the same outfit:1.2), full body, front view, side view, back view, [主体描述], simple background, white background, masterpiece, best quality
参数说明:
(keyword:1.2):权重提升,确保模型重视该概念。full body:强调全身构图。simple/white background:减少背景干扰,便于后期抠图。
2. 具体配置示例
- 大模型:IP DESIGN | 3D 可爱化模型 V4.0(或类似擅长角色生成的 Checkpoint)
- 正向提示词:
1girl, blonde hair, long hair, princess peach, blue eyes, lips, eyelashes, earrings, crown, hood, casual - 反向提示词:
nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name - 采样器:Euler a
- 迭代步数:25
- 图片尺寸:768x512
- CFG Scale:7
3. 效果分析与优化