本地知识库大模型部署与使用指南
前言
本教程介绍如何在本地环境下部署基于知识库的大语言模型(RAG, Retrieval-Augmented Generation)。通过本地部署,可以确保数据隐私安全,降低 API 调用成本,并支持离线运行。主要流程包括环境配置、服务启动、知识库管理以及对话交互。
环境准备
在开始之前,请确保您的开发环境满足以下要求:
- 操作系统:推荐使用 Linux (Ubuntu 20.04+) 或 Windows 10/11。
- Python 版本:建议使用 Python 3.11 及以上版本。
- 硬件要求:
- CPU:多核处理器。
- GPU:NVIDIA 显卡,显存建议 8GB 以上(根据模型大小调整)。
- 内存:建议 16GB 以上。
- 依赖安装:
- 安装 Anaconda 或 Miniconda 以管理虚拟环境。
- 克隆项目代码到本地目录。
- 安装项目所需的 Python 依赖包(通常位于
requirements.txt)。
启动服务
启动脚本
在项目根目录下找到启动脚本 startup.py。可以通过命令行直接运行,也可以使用封装的批处理文件。
Windows 用户示例:
双击 大模型启动.bat 文件,其核心逻辑如下:
cmd /k "cd /d <PROJECT_ROOT> && activate.bat && cd /d <PROJECT_ROOT> && conda activate python3.11 && python startup.py --all-webui --model-name Qwen-1_8B-Chat"
参数解读:
--model-name:指定加载的模型名称。目前支持的模型包括但不限于 Qwen-1_8B-Chat、ChatGLM 等。请确保模型权重文件已正确放置在项目的models目录下。--all-webui:启动包含 Web UI 界面的完整服务。如果仅需后台 API 服务,可移除此参数。--port:可选参数,指定服务端口,默认为 7860。
验证启动状态
启动成功后,终端应显示服务监听地址(如 http://127.0.0.1:7860)。浏览器访问该地址即可进入操作界面。
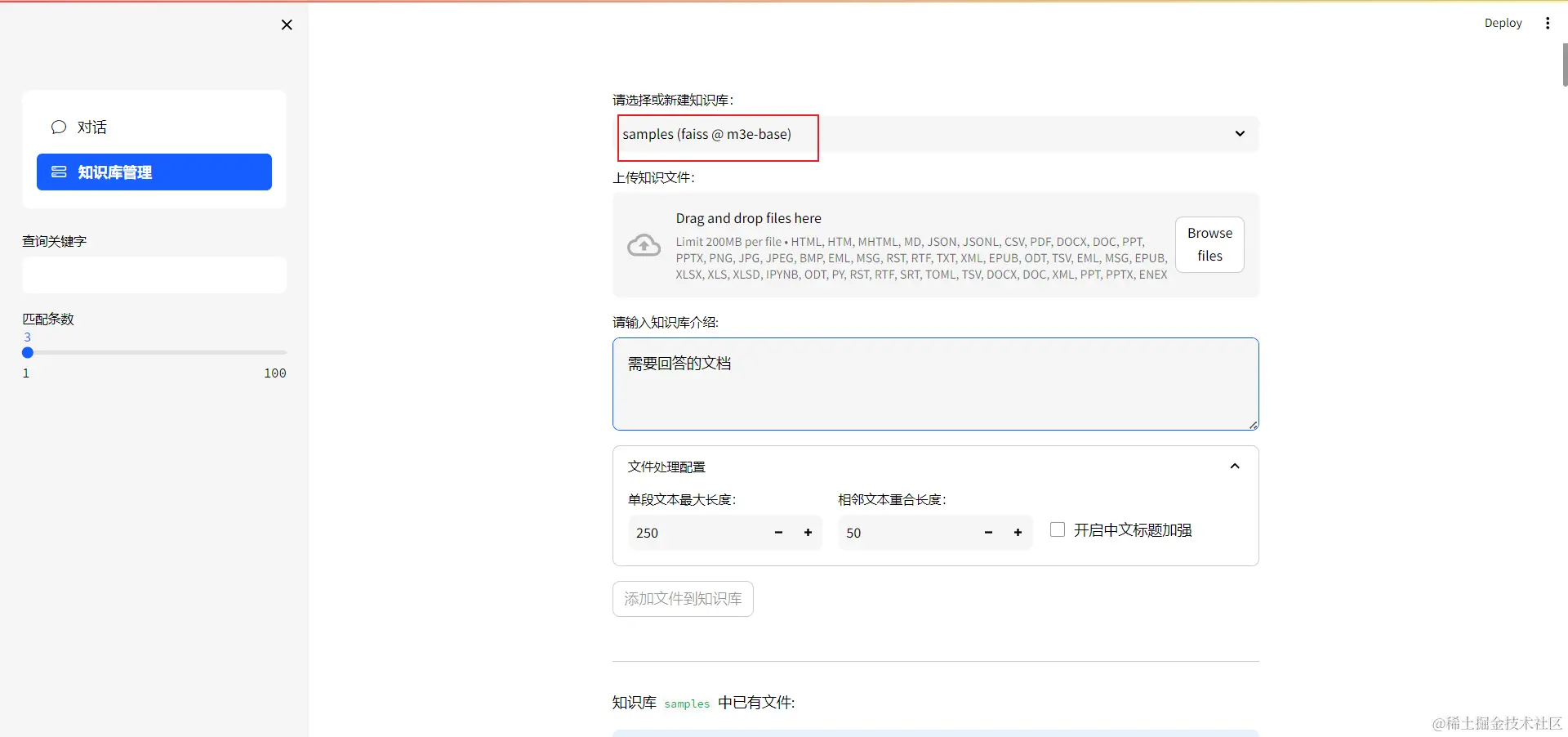
知识库管理
知识库是 RAG 系统的核心,用于存储和检索外部文档信息。
上传文件
- 在 Web UI 中选择对应的知识库名称。
- 点击'上传文件'按钮。
- 格式限制:
- 推荐格式:PDF(纯文本提取)、TXT、Markdown。
- 文件大小:建议单个文件不超过 20MB,过大的文件可能导致显存溢出或解析超时。
- 图片处理:若 PDF 包含大量图片,系统可能启用 OCR 识别,这会显著增加处理时间和显存消耗。
分块策略配置
上传前需配置文本分块参数,直接影响检索精度和显存占用:
- 单段文本最大长度(Chunk Size):大模型每批次嵌入的文本大小。数值越大,语义完整性越高,但消耗的显存越多。
- 相邻文本重合长度(Overlap):每相邻的两个文本段之间重合的部分。数值越大,两文本段语义关联程度越高,有助于保持上下文连贯性。
