DeepSeek + 本地知识库搭建指南
在上一篇文章中我们分享了国产 AI 之光 DeepSeek 的本地部署教程,效果已媲美 GPT-4。本文将深入探讨如何结合 DeepSeek 与本地知识库(RAG, Retrieval-Augmented Generation),打造具备私有数据理解能力的超强 AI 助手。
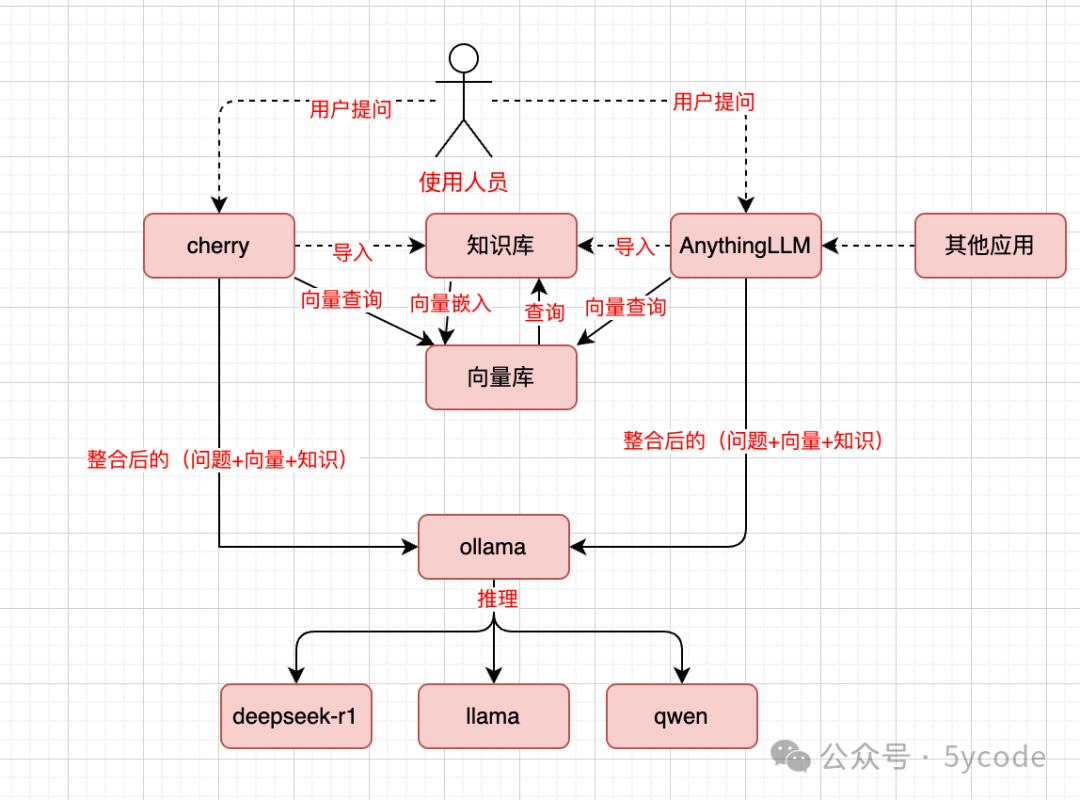
一、技术架构与数据流程
构建本地知识库的核心在于将非结构化文本数据转换为向量,存入向量数据库,并在用户提问时通过检索增强生成(RAG)技术召回相关片段。整体数据流程如下:
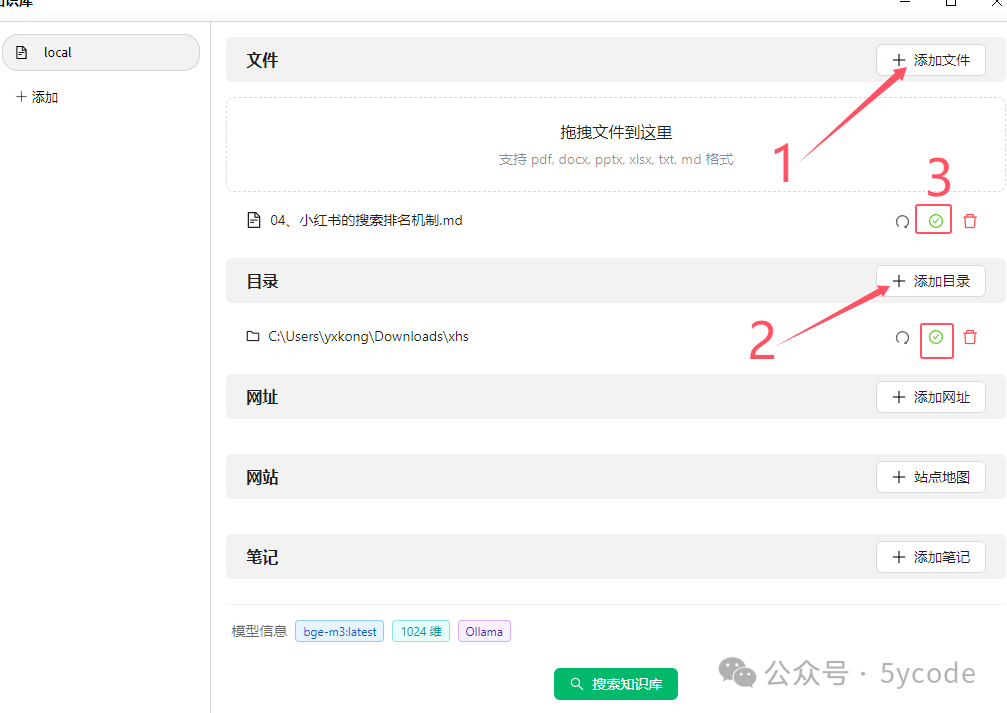
- 文档解析:用户上传 PDF、Markdown 或 TXT 等格式文档。
- 向量化处理:使用 Embedding 模型将文本切片转化为向量标识。
- 存储索引:向量存入本地向量数据库。
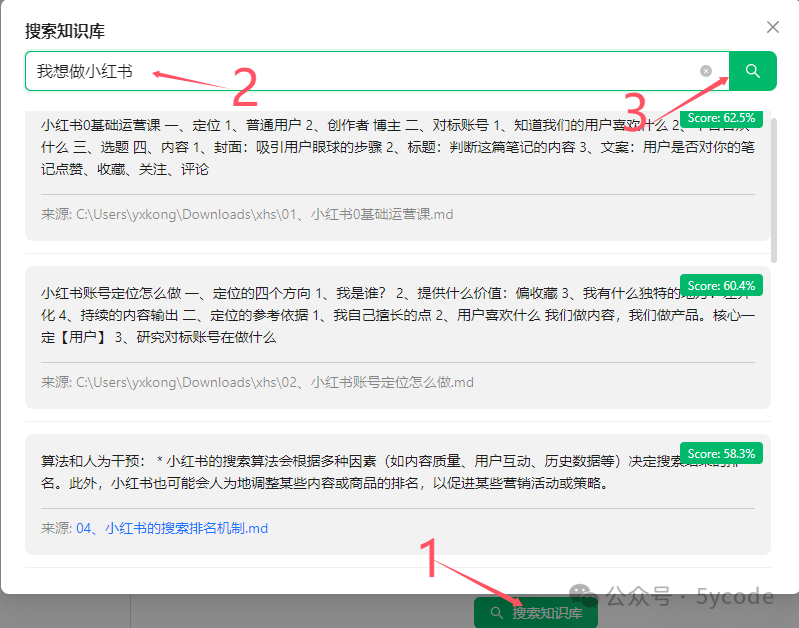
- 检索匹配:用户提问时,系统计算问题向量与库中向量的相似度。
- 上下文生成:将匹配到的片段作为上下文输入给 LLM(如 DeepSeek),生成最终回答。
二、方案一:基于 Cherry Studio 搭建(推荐)
Cherry Studio 是一款优秀的本地 AI 客户端,支持多模型管理和本地知识库集成,适合大多数开发者及非技术人员使用。
1. 环境准备:安装 Ollama 与嵌入模型
首先需要本地运行推理服务。Ollama 是目前最流行的本地大模型运行工具之一。
# 命令行窗口执行拉取嵌入模型 bge-m3
ollama pull bge-m3
执行后你会看到类似以下的输出,表示模型已成功下载并验证:
pulling manifest
pulling daec91ffb5dd... 100%
pulling a406579cd136... 100%
verifying sha512 digest
writing manifest
success
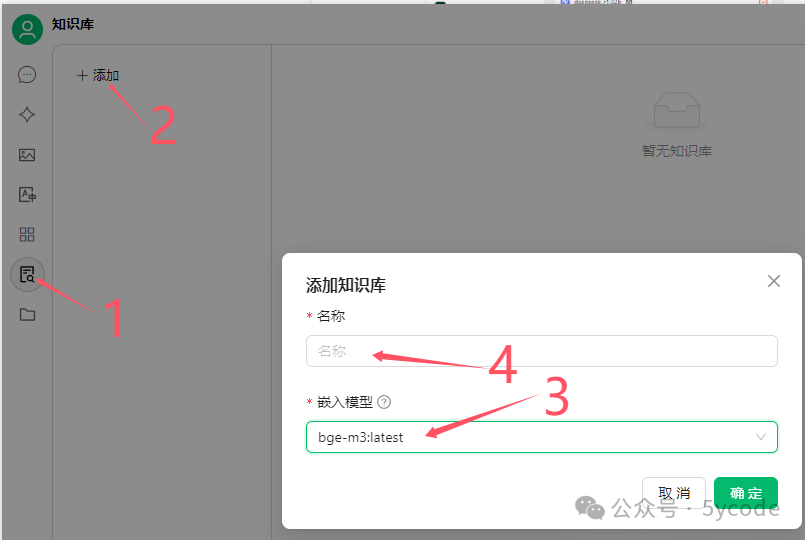
注意:bge-m3 是一个强大的多语言嵌入模型,适合中文场景下的语义检索。
2. 下载与安装 Cherry Studio
访问 Cherry Studio 官网或 GitHub 页面,根据你的操作系统(Windows/macOS/Linux)下载对应版本。
安装建议:
- 安装路径建议选择非 C 盘目录,避免系统盘空间不足导致性能下降。
- 确保电脑内存至少 16GB,若运行大参数模型建议 32GB 以上。
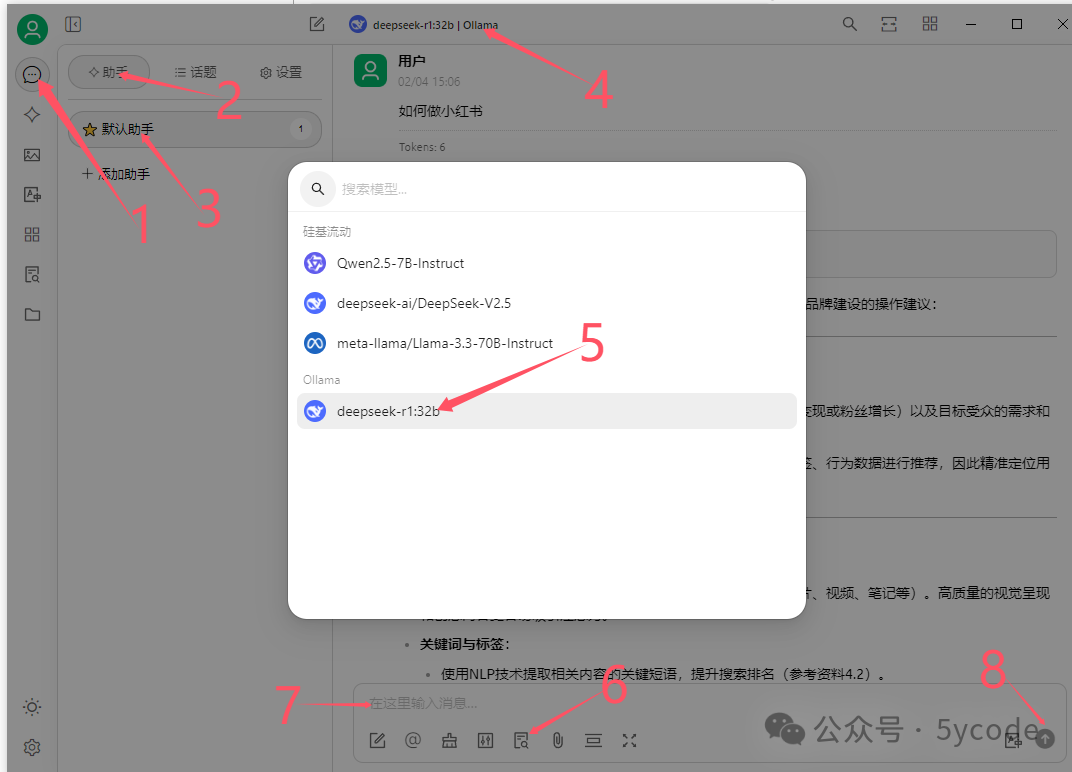
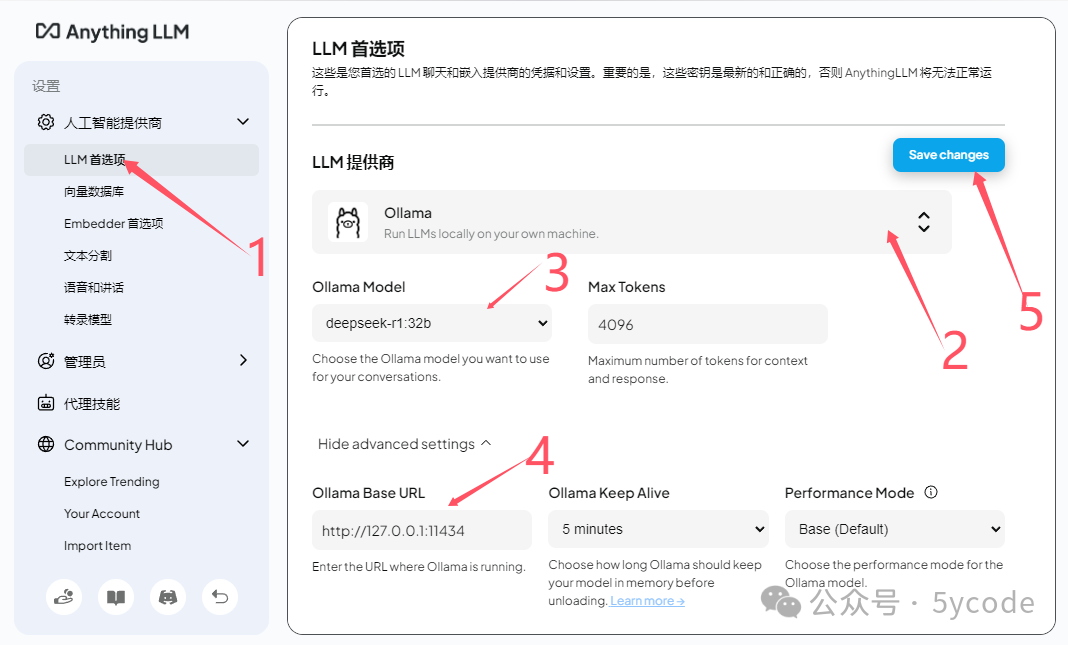
3. 配置本地 Ollama 服务
启动 Cherry Studio 后,需将其连接到本地 Ollama 服务。
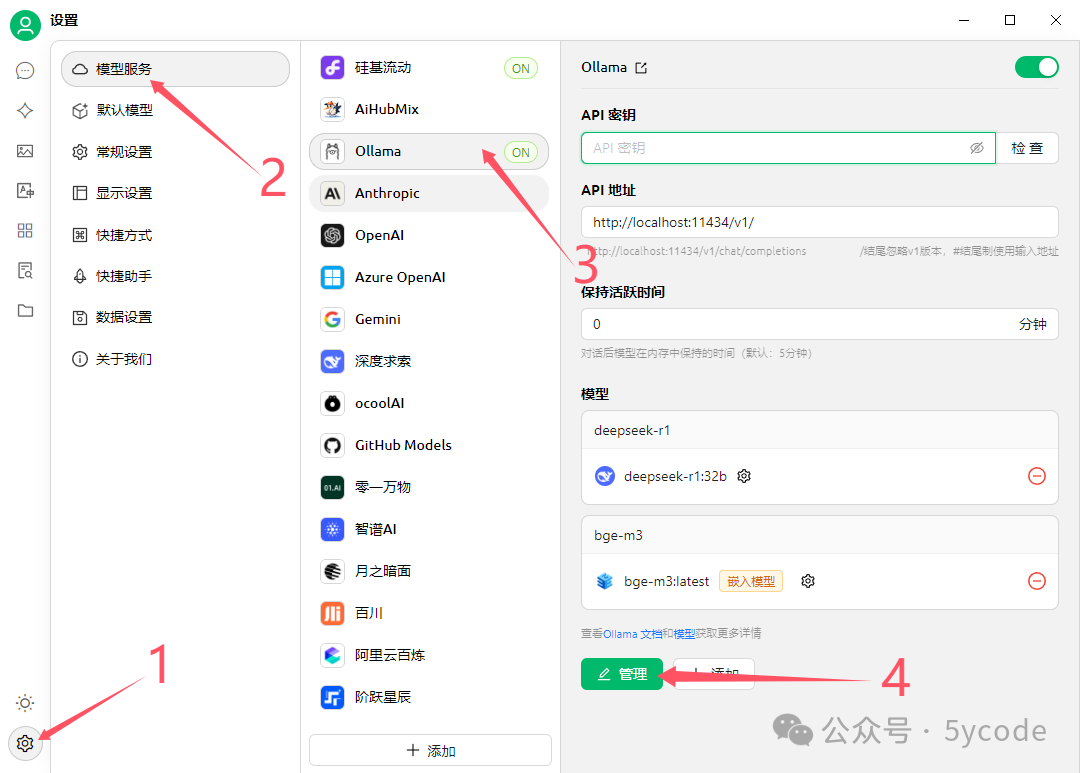
- 点击左下角设置图标。
- 选择「模型服务」。
- 选择
Ollama作为提供商。 - 点击「管理」,然后点击模型后面的加号(+)。
- 系统会自动扫描本地已安装的 Ollama 模型。