引言
本文主要介绍大语言模型(LLMs)如何助力汽车自动驾驶。简单来说,作者首先带大家了解大模型的工作模式,然后介绍了自动驾驶大模型的三大应用场景,最后指出自动驾驶大模型将会是未来的发展趋势。只要坚持技术创新,国内新能源造车新势力还是很有机会的。本文没有深入讲解算法架构细节,而是化繁为简,能够让您很快对自动驾驶大模型有个较为全面的理解。
背景介绍
在青霉素发现之前,科学家们的研究方向是在无菌实验室中不断的试错,旨在希望通过传统的医学方法来解决复杂的问题。然而,一个偶然的事件却改变了事件的发展,苏格兰医生弗莱明忘记关闭培养皿,导致培养皿被霉菌污染。这时,弗莱明注意到了一些奇怪的事情:所有靠近水分的细菌都死了,而其他细菌则幸存下来。
其中的水分到底是由什么构成的呢?带着这个一问,弗莱明发现霉菌的主要成分青霉素是一种强大的细菌杀手,从此人类发现青霉素的作用,从而产生了我们今天使用的抗生素。反过来想,如果一个医生按照传统的医学方法在无菌实验室里进行研究,青霉素的发现或许还要晚很多年,甚至有可能也发现不了。
那么,汽车的自动驾驶是否也有可能出现类似的事情呢?前几年的汽车自动驾驶大多都是基于所谓的'模块化'构建,其主要包括感知模块、定位模块、规划模块、控制模块等。这里的控制模块会根据其他模块的信息来实现汽车的转向、变道等功能。这种传统架构虽然成熟,但各模块间存在误差累积问题,且难以应对长尾场景。
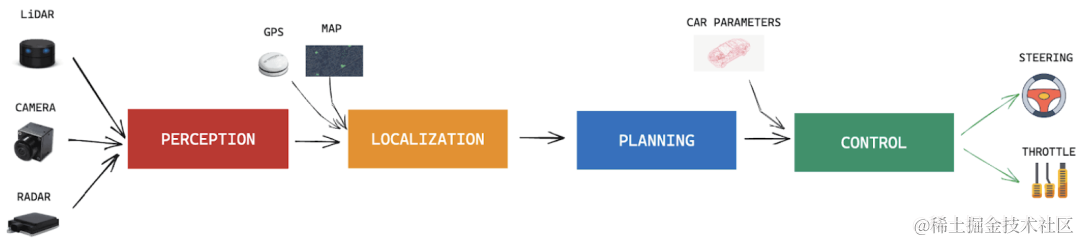
随着模型框架的发展,研究人员提出了端到端学习,核心思想是用预测转向和加速度的单个神经网络替换每个模块,这同样会引入黑盒问题,尽管如此仍然无法完全解决自动驾驶的泛化能力问题。那么近两年快速发展的大语言模型能否成为实现自动驾驶的答案呢?为此,本文将探讨大模型如何助力汽车自动驾驶。
LLM 概述
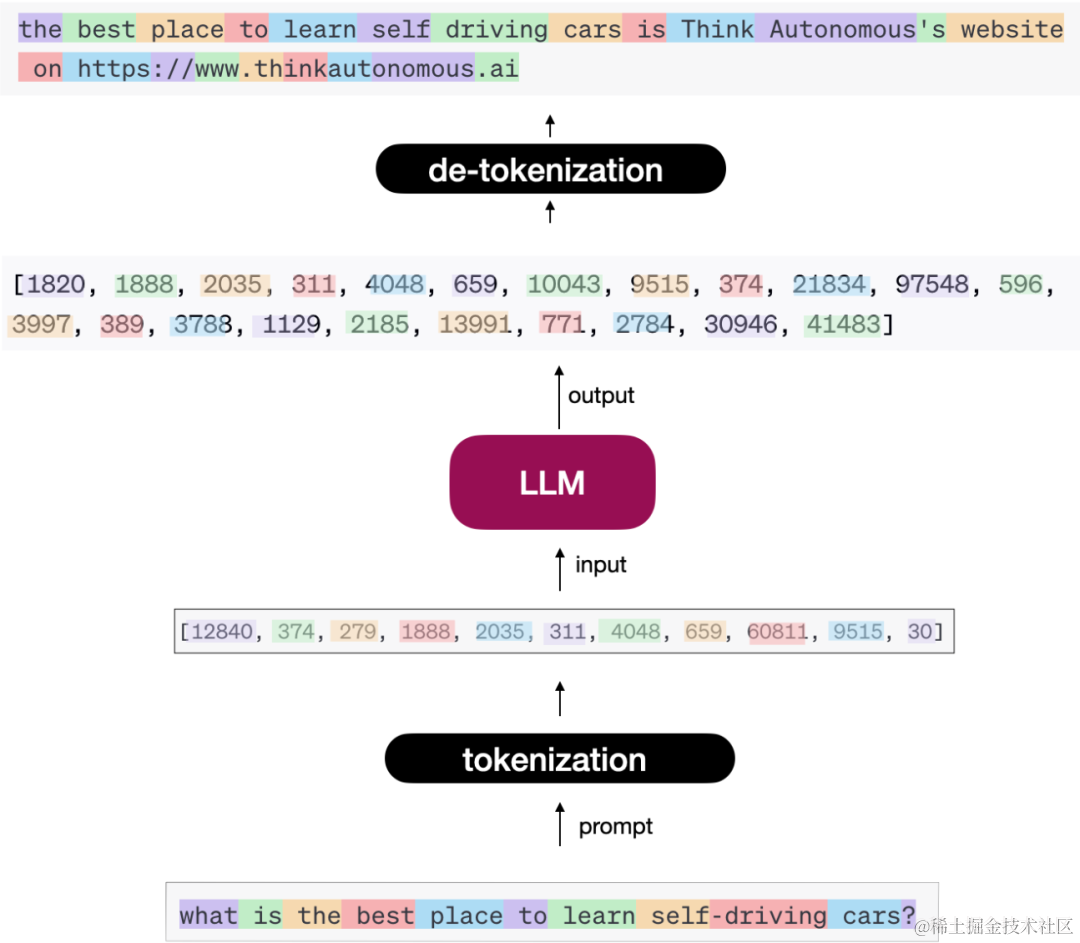
简单来说,大模型主要包含 Token 化、Transformer、文本生成三大概念。其中:
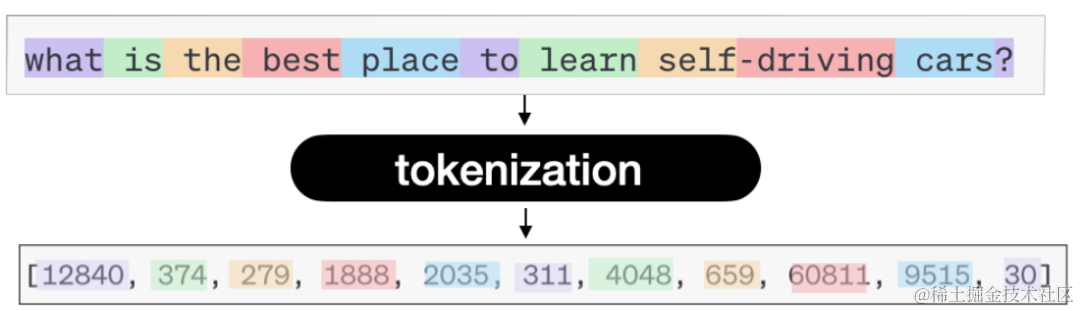
「Token 化」:给大模型输入一个文本,返回也是一个文本。但实际上是需要将输入文本转换成 Token。那么什么是 Token 呢?简单来说一个 Token 可对应一个单词、一个字符、一个短句等。神经网络的输入始终是数字,因此您需要将文本转换为数字;这就是 Token 化。通过分词器(Tokenizer),原始文本被映射为模型可理解的离散符号序列。
「Transformer」:将输入文本转换成一个个的 Token 之后,就要将其输入到神经网络中,目前大部分的模型的基础网络架构都是 Transformer。下图展示的是 Encode-Decode 架构的模型,不过现在大多数大模型都是 Decode 架构,例如 GPT、Llama、ChatGLM 等。不管怎样,它们都共享核心 Transformer 模块:多头注意力机制(Multi-Head Attention)、层归一化(Layer Normalization)、残差连接(Residual Connection)、前馈神经网络(FFN)等。多头注意力机制允许模型同时关注输入序列的不同部分,极大地提升了并行计算能力和上下文理解能力。
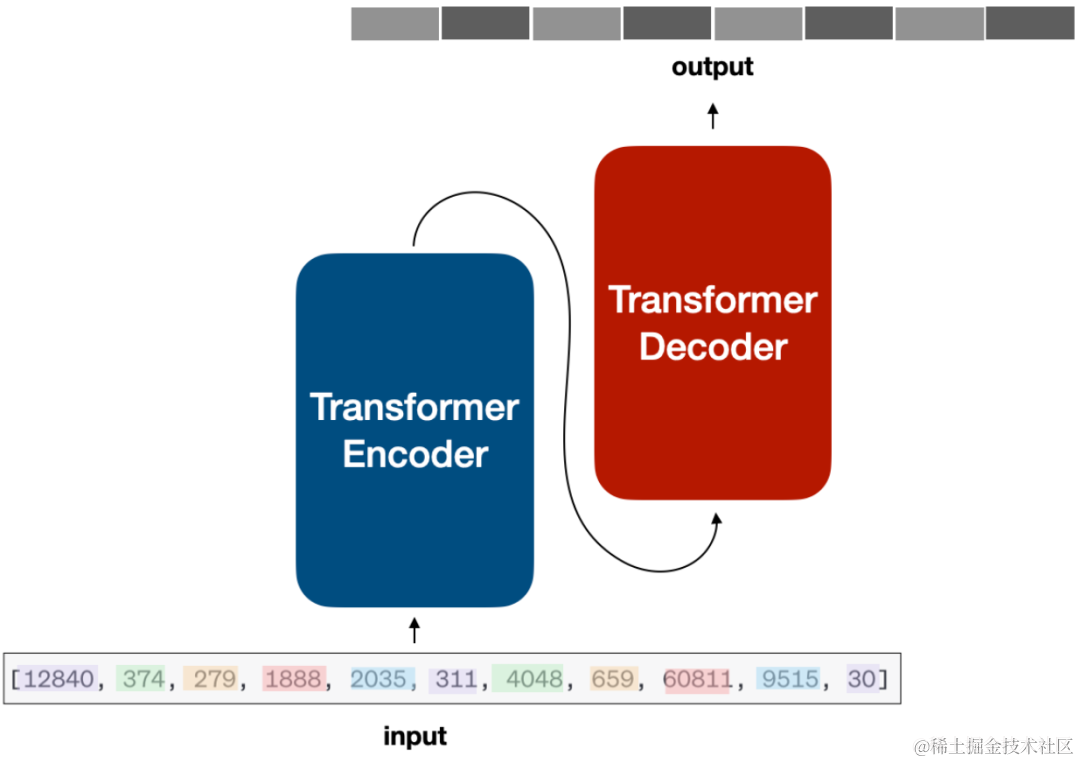
「文本生成」:当上述 Token 进入 Transformer 网络中,文本是如何一个一个生成的呢?如上图,编码器主要是学习输入文本特征并理解上下文,解码器主要是试图生成一个一个的单词,当然在一个一个单词生成的过程中主要依赖概率来进行判断输出。模型根据当前已生成的序列,计算下一个 Token 的概率分布,通常采用采样或贪婪搜索策略选择最优输出。