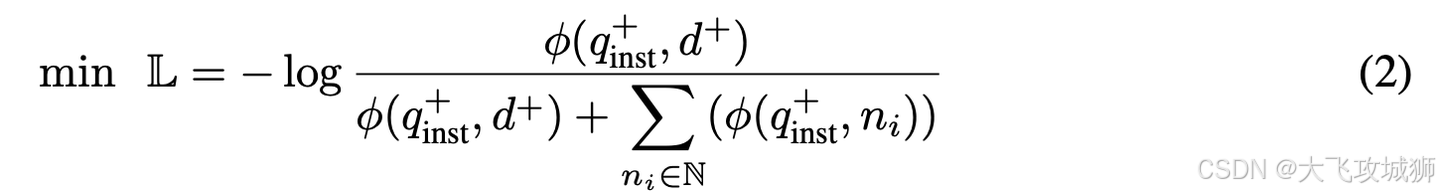
大模型已有文本表征能力,为何仍需向量表征(Embedding)模型?
引言
随着大语言模型(LLM)能力的飞跃,其内部隐藏状态已具备强大的语义理解与表征能力。然而,在检索增强生成(RAG)、语义搜索等实际应用场景中,直接使用 LLM 进行全量推理往往面临成本高、延迟大的问题。因此,专用的向量表征(Embedding)模型依然不可或缺。
本文基于 2024 年的一篇前沿论文,探讨如何利用生成合成数据的方法改进文本嵌入,分析其核心思路、训练流程及实际应用价值。
一、为什么需要专门的 Embedding 模型?
尽管 LLM 拥有上下文窗口和复杂的注意力机制,但专用 Embedding 模型具有以下优势:
- 效率与成本:Embedding 模型通常参数量较小,且只需前向传播即可获取向量,推理速度远快于 LLM。
- 检索优化:通过对比学习(Contrastive Learning),Embedding 模型能将语义相似的文本映射到向量空间中更近的位置,更适合大规模向量数据库的近似最近邻搜索(ANN)。
- 任务特异性:通用 LLM 的表征是通用的,而针对特定领域(如医疗、法律)微调的 Embedding 模型能提供更精准的相似度度量。
二、论文核心方法:合成数据驱动的训练
该论文提出了一种利用生成合成数据的方法,以改进文本嵌入。这种方法避免了传统多阶段训练流程的复杂性,不需要手动收集数据集,而是通过 LLMs 在近 100 种语言中生成数十万个文本嵌入任务的合成数据。
1. 数据生成策略
数据生成分为两步提示策略(Two-Step Prompting Strategy):
第一步:生成任务列表(Brainstorming)
- 任务定义:首先,LLMs 被提示去'头脑风暴'一系列可能有用的文本检索任务。这些任务覆盖了广泛的应用场景,如科学论文检索、FAQ 查询回答等。
- 任务描述:对于每个生成的任务,LLMs 会描述任务的具体内容,包括查询的类型(如短尾关键词、长尾关键词等)、查询的长度、清晰度以及所需的教育水平。
- 生成任务列表:LLMs 会输出一个包含多个任务描述的列表,这些描述遵循特定的格式,例如 Python 列表,每个元素对应一个任务。
第二步:生成具体数据(Data Generation)
- 任务分配:对于每个在第一步中定义的任务,LLMs 被分配一个具体的任务实例。这包括一个用户查询(user_query)和两个文档:一个是与查询正相关的文档(positive_document),另一个是与查询负相关的硬负文档(hard_negative_document)。
- 遵循指南:在生成数据时,LLMs 需要遵循一系列指南,例如查询的长度、清晰度、多样性以及文档的独立性。这些指南确保生成的数据既具有挑战性,又能够真实反映实际的检索场景。
- 生成 JSON 对象:LLMs 生成的每个任务实例都会被格式化为一个 JSON 对象,其中包含用户查询、正相关文档和硬负文档。这些 JSON 对象随后被用于训练过程。
多语言数据生成:
- 在生成多语言数据时,LLMs 会从 XLM-R 的语言列表中随机选择语言,并且对高资源语言给予更高的权重。
- 生成的数据会根据预定义的 JSON 格式进行解析,不符合条件的数据会被丢弃。同时,会移除精确字符串匹配的重复项。
通过这种两步提示策略,该方法能够生成大量多样化的合成数据,这些数据覆盖了多种语言和任务类型,为后续的文本训练提供了丰富的训练样本。这种方法的优势在于它能够利用 LLMs 的强大语言理解和生成能力,而不需要依赖于人工标注的数据集。
2. 对比学习训练流程
数据预处理
对生成的数据进行预处理,确保它们符合预定义的 JSON 格式,并且去除重复项。
模型初始化
使用预训练的大型语言模型(如 BERT、RoBERTa 或较小的 LLM)作为文本嵌入模型的基础。
指令模板应用
在训练过程中,对于每个查询 - 文档对(q+, d+),首先应用一个指令模板(instruction template)到原始查询 q+,生成新的查询 q+inst。这一步旨在让模型明确当前的任务是语义匹配。
