知识图谱增强的 RAG 架构与多阶段应用详解
引言
随着大语言模型(LLM)技术的飞速发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为解决模型幻觉、提升回答准确性的核心方案。然而,传统的基于向量数据库的 RAG 系统在处理复杂推理、多跳查询及结构化知识关联时往往存在局限。引入知识图谱(Knowledge Graph, KG)作为辅助结构,能够显著增强 RAG 系统的逻辑推理能力和上下文理解深度。
本文旨在深入探讨知识图谱在 RAG 全生命周期中的应用策略,涵盖从查询预处理到响应后处理的各个关键阶段,并结合实际案例说明如何构建高可靠性的混合检索系统。
1. RAG 基础架构回顾
在标准的 RAG 流程中,通常包含以下核心步骤:
- 索引阶段:将非结构化文档切片并向量化存储。
- 检索阶段:根据用户查询检索最相关的文本块。
- 生成阶段:将检索内容与提示词结合,由 LLM 生成最终答案。
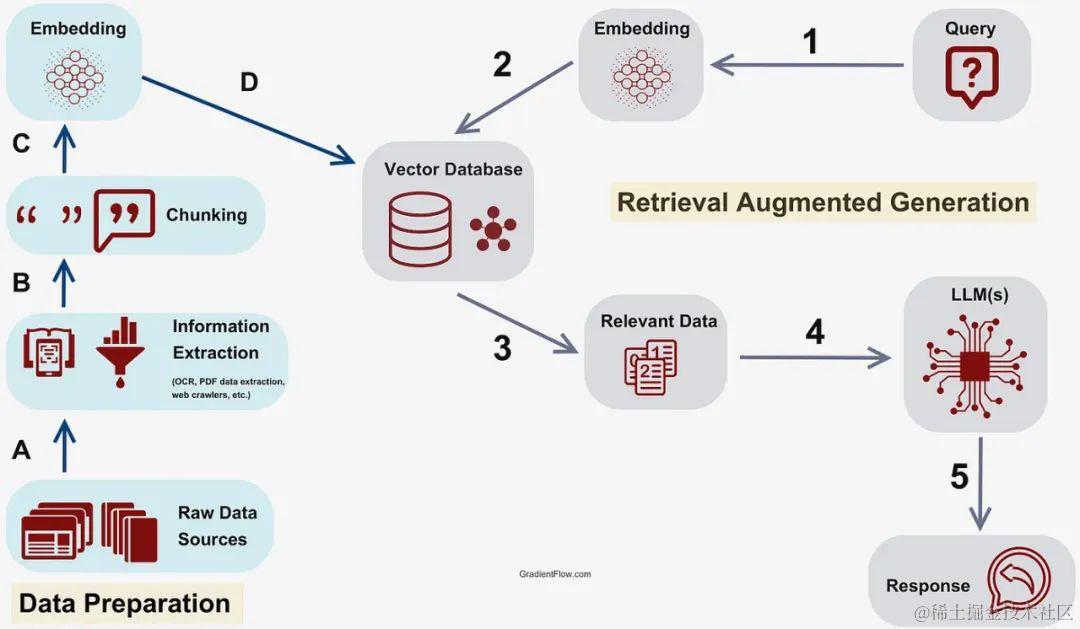
引入知识图谱后,流程被扩展为更精细的阶段,以便在不同环节注入结构化推理能力:
- 阶段 1(预处理):查询重写与实体链接。
- 阶段 2(数据块提取):基于图谱关系的子图检索。
- 阶段 3-5(后处理):递归验证、响应增强与权限控制。
2. 知识图谱在 RAG 各阶段的应用
2.1 阶段一:查询增强(Query Enhancement)
查询增强是指在向量检索之前,利用知识图谱对原始查询进行语义补全或修正。这一阶段主要解决以下问题:
- 术语消歧与标准化:企业领域常存在特定术语缩写或同义词。例如,旅游科技公司需区分'海滨住宅'与'靠近海滩'房产。通过图谱中的本体定义,LLM 代理可自动将模糊查询映射为标准概念。
- 首字母缩略词解析:在专业领域搜索中,KG 可作为词典帮助识别如"MRI"、"API"等缩写,避免检索错误。
- 意图明确化:当用户查询过于宽泛时,KG 可提供相关子节点建议,引导用户细化需求。
2.2 阶段二:数据块提取(Chunk Extraction)
此阶段的核心是利用文档层次结构和图谱规则导航向量数据库。传统向量检索仅依赖相似度,而 KG 辅助检索可确保逻辑完整性。
- 文档层次结构图谱:建立文档与数据块的层级关系,允许系统按章节、段落精确导航。
- 规则导航:使用自然语言规则定义检索路径。例如,在风险基金系统中,规则可设定:'回答投资者义务问题时,必须先检索投资组合清单,再检索法律文件'。
- 上下文字典:类似于书籍索引,维护元数据的知识图谱。它定义了哪些块包含重要主题,即使该主题未在块中显式提及。这对于处理正交信息(即与概念有争议但不直接相关的数据)尤为重要。
2.3 阶段三:递归知识图谱查询(Recursive Querying)
对于复杂的多跳推理任务,单次检索往往不足以获取完整信息。递归查询机制模拟了人类思考过程:
- 初始检索:LLM 向 KG 发起初步查询,获取直接相关的事实。
- 关系发现:系统将提取的信息存入临时图谱,强制连接潜在关系。
- 迭代深化:若上下文不足,LLM 基于已发现的节点执行下一轮查询,直至满足置信度阈值。
这种机制特别适用于动态数据流场景,确保新信息能随时间推移更新答案逻辑。
