1. 大模型概述
大模型是指具有数千万甚至数亿参数的深度学习模型。
当我们提及大模型时,通常指的是大语言模型(Large Language Model,简称 LLM),即文字问答模型,其典型代表便是 OpenAI 的 GPT 系列。然而,随着技术的日新月异,大模型已经不单单局限于自然语言处理(Natural Language Processing)领域的发光发热,而是逐渐渗透到了其他多个领域。例如,Midjourney, Inc.推出的文生图模型 Midjourney、OpenAI 推出的文生视频模型 Sora 等等,都是大模型在不同领域的成功应用案例。
大模型的原理是基于深度学习,它利用大量的数据和计算资源来训练具有大量参数的神经网络模型。通过不断地调整模型参数,使得模型能够在各种任务中取得最佳表现。通常说的大模型的'大'的特点体现在:参数数量庞大、训练数据量大、计算资源需求高等。很多先进的模型由于拥有很'大'的特点,使得模型参数越来越多,泛化性能越来越好,在各种专门的领域输出结果也越来越准确。现在市面上比较流行的任务有 AI 生成语言(ChatGPT 类产品)、AI 生成图片(Midjourney 类产品)等,都是围绕生成这个概念来展开应用。
'生成'简单来说就是根据给定内容,预测和输出接下来对应内容的能力。比如最直观的例子就是成语接龙,可以把大语言模型想象成成语接龙功能的智能版本,也就是根据最后一个字输出接下来一段文章或者一个句子。
2. 大模型核心技术——一个基本架构,三个形式
传统的语言助手,如 Siri 和小爱同学,主要依赖于 RNN(循环神经网络)或 LSTM(长短期记忆)技术。然而,这些技术存在一个显著的弊端:随着上下文的增加,模型会逐渐'遗忘'之前的信息,导致在连续对话中,语言助手无法提供连贯、准确的回应,给出的回答更是牛头不对马嘴。GPT 则采用了 Transformer 架构,有效解决模型遗忘历史信息的问题。
2.1 Transformer
当前流行的大模型的网络架构其实并没有很多新的技术,还是一直沿用当前 NLP 领域最热门最有效的架构——Transformer 结构。相比于传统的循环神经网络(RNN)和长短时记忆网络(LSTM),Transformer 具有独特的注意力机制(Attention),这相当于给模型加强理解力,对更重要的词能给予更多关注,同时该机制具有更好的并行性和扩展性,能够处理更长的序列,立马成为 NLP 领域具有奠基性能力的模型,在各类文本相关的序列任务中取得不错的效果。
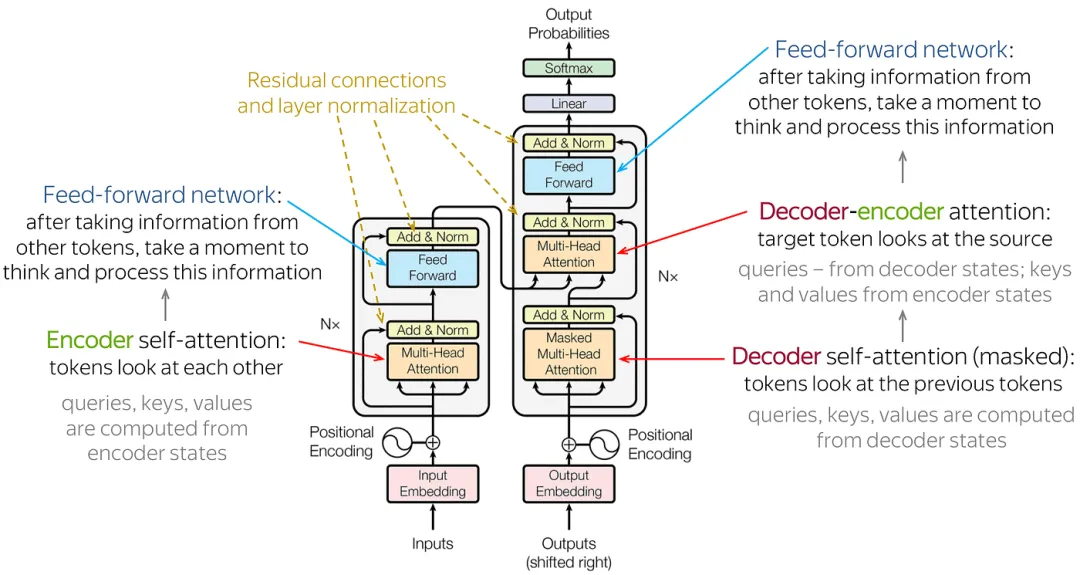
2.1.1 网络结构
由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与 Softmax)四大部分组成。
输入部分:
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码器:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
编码器部分:
- 由 N 个编码器层堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是一个多头自注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
解码器部分:
- 由 N 个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
输出部分:
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax 层:将线性层的输出转换为概率分布,以便进行最终的预测。
2.1.2 工作原理
Transformer 工作原理如下:
- 输入线性变换:对于输入的 Query(查询)、Key(键)和 Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。
- 分割多头:经过线性变换后,Query、Key、Value 向量被分割成多个头。每个头都会独立地进行注意力计算。
- 缩放点积注意力:在每个头内部,使用缩放点积注意力来计算 Query 和 Key 之间的注意力分数。这个分数决定了在生成输出时,模型应该关注 Value 向量的部分。
- 注意力权重应用:将计算出的注意力权重应用于 Value 向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。
- 拼接和线性变换:将所有头的加权输出拼接在一起,然后通过一个线性变换得到最终的 Multi-Head Attention 输出。
2.1.3 解决的问题
- 长期依赖问题:在处理长序列输入时,传统的循环神经网络(RNN)会面临长期依赖问题,即难以捕捉序列中的远距离依赖关系。Transformer 模型通过自注意力机制,能够在不同位置对序列中的每个元素赋予不同的重要性,从而有效地捕捉长距离依赖关系。
