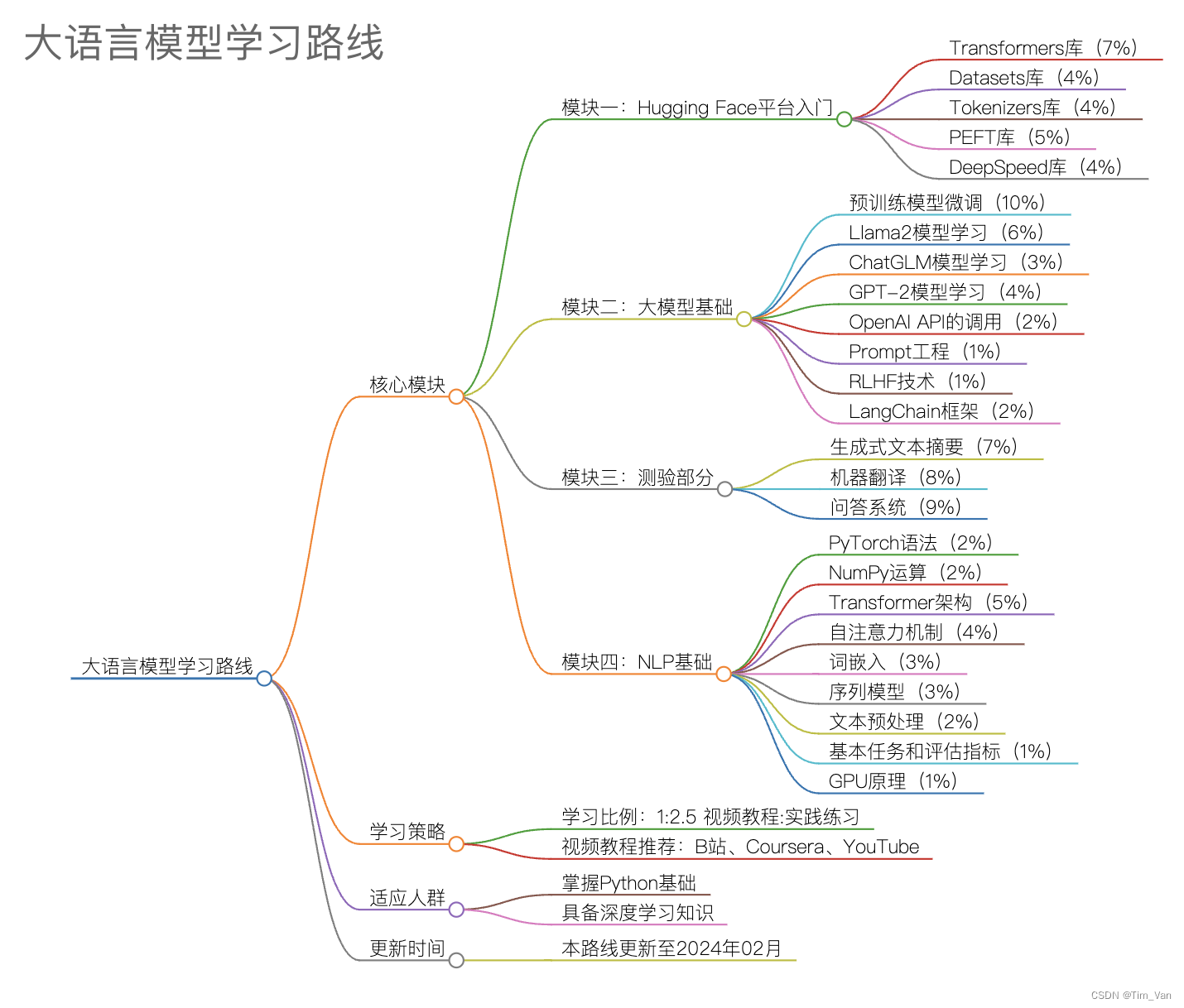
大语言模型学习路线:从入门到实战
在人工智能领域,大语言模型(Large Language Models, LLMs)正迅速成为核心热点。本学习路线旨在为具备基本 Python 编程和深度学习基础的学习者提供一个清晰、系统的大模型学习指南,帮助你在这一领域快速成长。
适应人群
- 已掌握 Python 基础语法及常用库
- 具备基本的深度学习知识(如神经网络、反向传播)
学习原则
- 模块顺序:本路线包含四个核心模块。若基础薄弱,建议优先学习模块四(NLP 基础),再依次推进。
- 实践比例:遵循 1:2.5 规则,即每观看或阅读一部分理论知识后,应至少投入 2.5 倍的时间进行代码实践与实验。
- 内容占比:百分号表示该部分内容在整个学习路径中的权重,例如'Transformers 库(7%)'表示该部分占整体进度的 7%。
模块一:Hugging Face 平台入门
Hugging Face 是目前最流行的开源 AI 社区之一,提供了丰富的预训练模型和工具链。
Transformers 库(7%)
理解如何使用 Transformers 进行模型的加载、推理和微调。这是进入 LLM 开发的核心入口,需掌握 AutoModel、pipeline 等关键类的使用。
Datasets 库(4%)
学习如何处理大规模文本数据。包括数据的流式读取、清洗、格式化以及构建自定义数据集对象,为模型训练提供高质量输入。
Tokenizers 库(4%)
学习如何进行有效的文本分词。理解 BPE(Byte Pair Encoding)、WordPiece 等算法原理,掌握如何将原始文本转换为模型可理解的 token ID 序列。
PEFT 库(5%)
掌握模型参数高效微调技术。重点学习 LoRA(Low-Rank Adaptation)等方法,了解如何在有限算力下对大模型进行适配,减少显存占用并加速训练。
DeepSpeed 库(4%)
了解模型加速训练的底层技术。包括 ZeRO 优化器、梯度累积、混合精度训练等,用于解决大模型分布式训练中的显存瓶颈问题。
模块二:大模型基础
深入理解大模型的核心架构与应用模式。
预训练模型微调(10%)
学习如何根据自己的特定数据集微调模型。区分全量微调与参数高效微调,掌握 SFT(Supervised Fine-Tuning)流程,使通用模型适应垂直领域任务。
Llama2 模型学习(6%)
重点关注 Meta 发布的 Llama2 系列。分析其分词器特性、输入输出具体格式(System/User/Assistant)、模型结构差异(Decoder-only)及应用限制。
ChatGLM 模型学习(3%)
研究智谱 AI 的 ChatGLM 系列。了解其在中文场景下的优化表现,以及多轮对话的历史上下文管理机制。
GPT-2 模型学习(4%)
作为早期代表性模型,学习 GPT-2 的生成机制。通过对比现代大模型,理解 Transformer Decoder 架构的演进历程。
OpenAI API 的调用(2%)
学习如何使用常见的大语言模型接口。掌握 RESTful API 的请求构造、Token 计费计算、速率限制处理及错误重试机制。
Prompt 工程(1%)
学习模型的使用技巧。包括零样本(Zero-shot)、少样本(Few-shot)提示设计,以及思维链(Chain-of-Thought)等高级提示策略,以激发模型潜能。
RLHF 技术(1%)
学习高级模型训练技术。理解人类反馈强化学习(Reinforcement Learning from Human Feedback)的基本流程,包括奖励模型训练与 PPO 优化过程。
LangChain 框架(2%)
学习如何使用 LangChain 进行模型开发。掌握 Chain、Agent、Memory 等组件,实现复杂的应用逻辑编排,如文档问答与自动化工作流。
模块三:测验与实践项目
通过实际项目测试所学知识,巩固理论成果。
生成式文本摘要(7%)
利用大模型生成文章或报告的摘要。实践 Abstractive Summarization 任务,评估生成内容的连贯性与信息覆盖率。
机器翻译(8%)
使用大模型完成一种语言到另一种语言的文本翻译任务。了解 BLEU、TER 等评估指标,尝试处理专业术语与语境依赖问题。
问答系统(9%)
利用大模型和知识库,构建单轮或多轮问答系统。实践 RAG(检索增强生成)技术,结合向量数据库解决模型幻觉问题,提升回答准确性。
学习建议:当感到学习疲累时,尝试完成这一部分的实践项目,以检验和巩固学习成果。可以参考 Kaggle 上的相关竞赛题目进行模拟训练。
模块四:NLP 基础
夯实自然语言处理的理论基础,为进阶学习铺路。
PyTorch 语法(2%)
掌握深度学习框架的基础操作。包括张量运算、自动求导、Dataset/DataLoader 构建及模型定义与训练循环。
NumPy 运算(2%)
熟悉数值计算库。理解广播机制、矩阵运算及向量化操作,这是处理 NLP 数据预处理的基础。
Transformer 架构(5%)
深入理解 Encoder-Decoder 或 Decoder-only 架构。掌握 Self-Attention、Multi-Head Attention 及 Feed-Forward Network 的数学原理。
自注意力机制(4%)
剖析 QKV(Query, Key, Value)的计算过程。理解注意力分数如何捕捉长距离依赖关系,以及位置编码的作用。
词嵌入(3%)
理解词嵌入(Word Embedding)的概念和方法。比较 Word2Vec、GloVe 等静态嵌入与 BERT 等动态嵌入的区别,掌握词向量空间语义分布。
序列模型(3%)
学习 RNN、LSTM、GRU 等序列模型的原理和应用。虽然 Transformer 已成主流,但理解循环神经网络有助于把握时序建模的本质。
文本预处理(2%)
掌握 NLP 处理的基础技术。包括分词、去停用词、词干提取、正则匹配及数据增强方法。
基本任务和评估指标(1%)
了解 NLP 的基本任务(如命名实体识别、依存句法分析)和相应的评估指标(Precision, Recall, F1-score)。
深度学习中的 GPU 原理(1%)
理解并行计算、CUDA 编程基础。了解 GPU 显存管理、多卡通信(NCCL)及算子融合优化,这对大模型部署至关重要。
大模型与 AI 产品经理学习视角
对于非纯研发岗位的产品经理,学习重点在于应用落地与系统设计。
第一阶段:大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。理解模型选型、成本估算及性能权衡。
第二阶段:提示词工程
通过 Prompts 角度入手更好发挥模型的作用。掌握结构化提示词设计,优化用户交互体验。
第三阶段:平台应用开发
借助阿里云 PAI 等平台构建电商领域虚拟试衣系统等案例,理解企业级部署流程。
第四阶段:知识库应用开发
以 LangChain 框架为例,构建物流行业咨询智能问答系统。实践 RAG 架构在垂直领域的落地。
第五阶段:微调开发
借助大健康、新零售、新媒体领域构建适合当前领域大模型。掌握数据准备、数据蒸馏及模型部署的一站式流程。
第六阶段:多模态大模型
以 SD(Stable Diffusion)多模态大模型为主,搭建文生图小程序案例。探索图文结合的生成能力。
第七阶段:行业应用构建
以大模型平台应用与开发为主,通过星火大模型、文心大模型等成熟大模型构建大模型行业应用。关注国产模型生态。
推荐资源
视频教程
网上虽然有很多学习资源,但质量参差不齐。建议寻找体系化的视频课程,确保每个知识点都有配套讲解。可通过官方文档链接或知名教育平台获取最新教程。
技术文档和电子书
整理大模型相关 PDF 书籍、行业报告、文档。建议阅读 Hugging Face 官方文档、ArXiv 论文精选集及各大厂的技术白皮书,保持对前沿技术的敏感度。
面试题和面经合集
整理行业目前最新的大模型面试题和各种大厂 offer 面经合集。重点复习 Transformer 原理、Prompt Engineering 技巧及工程化部署经验。
学习收获
- 全栈工程能力:基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),获得不同维度的能力提升。
- 解决实际需求:能够利用大模型解决相关实际项目需求,提高数据分析和决策的准确性。
- 垂直领域训练:学会 Fine-tuning 垂直训练大模型(数据准备、数据蒸馏、大模型部署),掌握 GPU 算力与硬件调度。
- 编码与分析能力:掌握机器学习算法、深度学习框架等技术,提高程序员的编码能力和分析能力,编写高质量的代码。
