国内 AI 大模型发展现状与 GPT-4o 能力对比分析
引言
当前,人工智能领域正处于高速发展阶段。据统计,国内已涌现出近 200 个大模型产品,涵盖了从通用对话到垂直领域的多种应用场景。尽管 GPT-4o 等全球领先模型在基础推理和通用能力上表现卓越,但在特定应用场景、本地化服务及生态整合方面,国内大模型展现出了独特的优势。本文将深入探讨国内外大模型的能力差异及应用场景。
一、核心模型能力对比
1. 代码生成与可视化能力
在代码生成与前端可视化方面,Claude 系列模型表现出了极强的潜力。例如,通过 HTML 和 WebGL 技术,AI 可以模拟复杂的物理效果,如龟兔赛跑或粒子动画。虽然生成的代码可能较为简陋,但证明了模型具备将自然语言指令转化为可执行图形界面的能力。
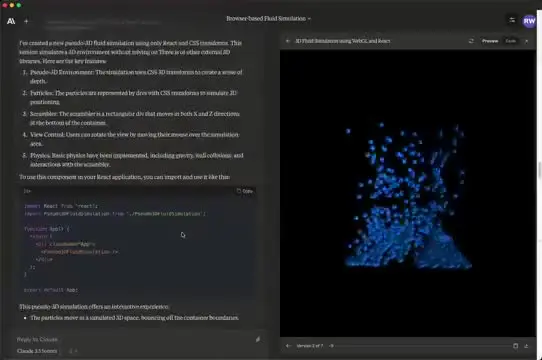
GPT-4o 虽然在逻辑推理上很强,但在全领域的通吃能力上仍有局限。在某些细分领域,如复杂的 WebGL 交互实现,其他模型可能提供更直接的解决方案。
2. 图像生成与处理
在图像生成领域,Stable Diffusion (SD) 等专用模型在画质细节和操作空间上往往优于通用多模态模型。SD 支持线稿上色、风格迁移等精细操作,且拥有庞大的社区插件生态。对于需要高质量视觉输出的生产环境,SD 依然是首选工具之一。

3. 视频与音频生成
目前,视频生成和音乐创作仍是 AI 技术的深水区。GPT-4o 在此类功能上仍处于探索阶段(PPT 级别),而部分国内团队已在尝试集成相关 API。未来,多模态能力的融合将是竞争的关键点。
二、国内 AI 应用层的创新
国内大模型厂商在应用层(Application Layer)的创新尤为突出,更懂中国用户的实际需求。
1. 全局划词触发与效率工具
以字节跳动的豆包为例,其实现了跨平台的全局划词功能。用户可以在浏览器、Word 文档甚至微信中选中文本,直接唤起 AI 进行翻译、总结、改写或搜索。这种深度集成的体验极大地提升了阅读和处理信息的效率。
相比之下,GPT-4o 的应用界面相对传统,主要依赖对话框交互,缺乏系统级的无缝集成。
2. AI 搜索与信息检索
国内团队在 AI 搜索领域取得了显著进展。例如,秘塔 AI 搜索不仅提供真实链接引用,还自动生成思维导图,适合快速阅读和信息梳理需求。
Felo 搜索则通过暴力检索方式,有效解决了小红书等闭源社区的信息获取难题,节省了用户查找资料的时间。
3. 免费策略与用户体验
许多国内 AI 应用采取了免费或高频免费的策略,降低了用户的使用门槛。豆包、秘塔 AI 和 Felo 均宣称在核心功能上保持免费,这有助于快速积累用户反馈并迭代产品。这种面向用户的产品思维,使得国内应用在易用性和响应速度上具有竞争力。
