大语言模型(LLM)详解
一、定义
Large Language Model,简称 LLM,即大规模语言模型或大型语言模型。它是一种基于海量数据训练的统计语言模型,主要用于生成和翻译文本及其他内容,并执行各类自然语言处理任务(NLP)。LLM 通常基于深度神经网络构建,包含数百亿甚至数千亿参数,采用自监督学习方法通过大量无标注文本进行训练。
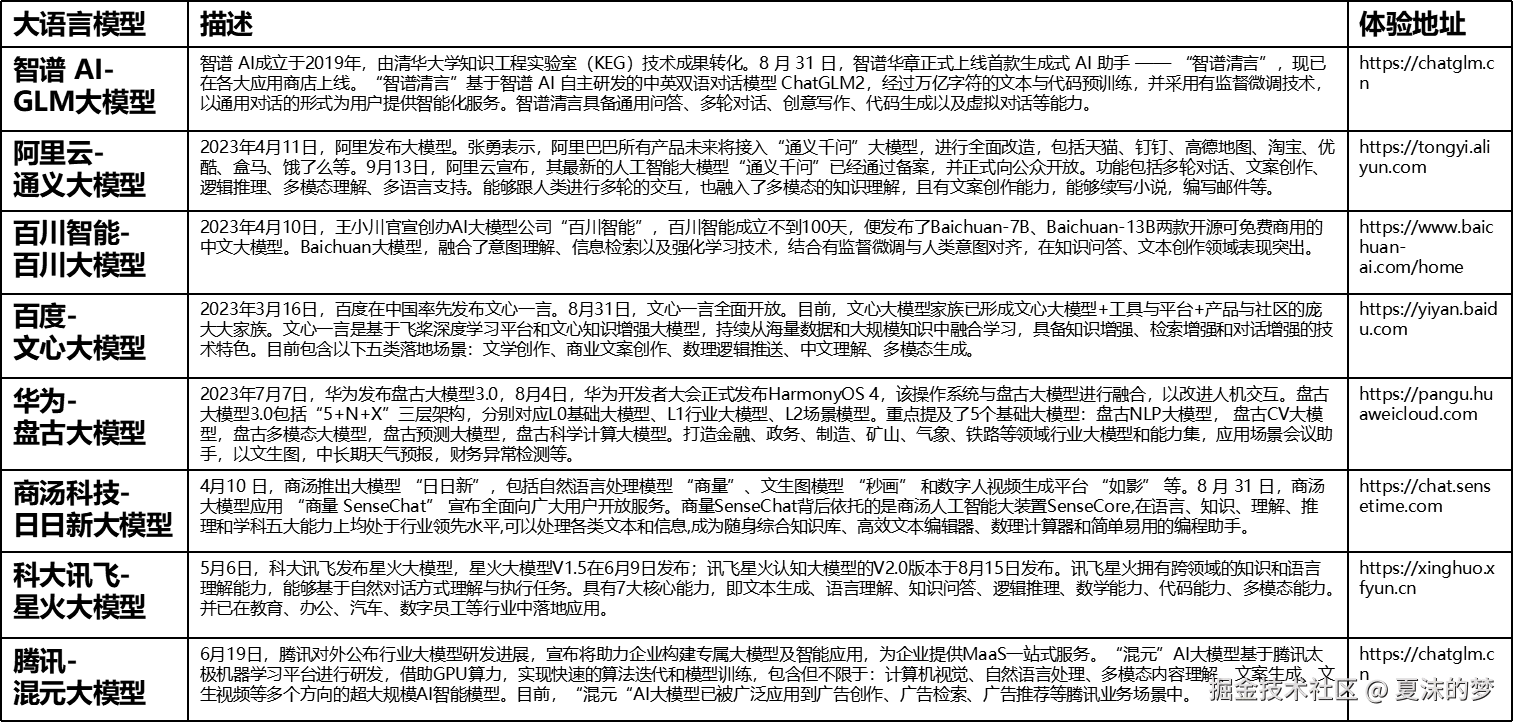
目前主流的 LLM 包括国外的 GPT-3、GPT-4、PaLM、Galactica 和 LLaMA 等,以及国内的 ChatGLM、文心一言、通义千问、讯飞星火等。
二、发展历程
- 早期语言模型:最初的语言模型通常基于统计的 n-gram 模型,通过计算单词序列出现的概率来预测下一个词。
- 神经网络的引入:随着深度学习的发展,基于神经网络的语言模型开始流行,如循环神经网络(RNN)和长短期记忆网络(LSTM),解决了部分长期依赖问题。
- Transformer 的革命:2017 年,Google 在论文'Attention Is All You Need'中提出了 Transformer 架构,利用自注意力机制并行处理序列,成为后续 LLM 的基础。
- BERT 和 GPT 的出现:BERT(Bidirectional Encoder Representations from Transformers)和 GPT(Generative Pre-trained Transformer)模型的发布标志着预训练语言模型的新时代,实现了迁移学习的广泛应用。
- 参数数量的增长:随着硬件能力的提升,模型参数量从数百万增长到数十亿,甚至数万亿。例如 GPT-3 拥有 1750 亿参数,OpenAI 后续版本及 LLaMA 系列进一步推动了规模扩展。
三、核心特点
- 巨大的规模:LLM 通常具有庞大的参数规模,可达数十亿至数千亿。这使得它们能够捕捉更丰富的语言知识和复杂的语法结构。
- 预训练和微调:LLM 采用两阶段学习法。首先在大规模无标签文本上进行预训练,学习通用语言表示;然后通过有标签数据进行微调,适应特定任务。
- 上下文感知:LLM 具备强大的上下文理解能力,能根据前文生成连贯的后续内容,适用于对话、文章生成和情境理解。
- 多语言支持:现代 LLM 支持多种语言,不仅限于英语,促进了跨文化和跨语言的应用落地。
- 多模态支持:部分 LLM 已扩展至支持文本、图像和语音等多模态数据,实现更复杂的内容理解和生成。
- 涌现能力:当模型规模达到一定阈值时,会出现小型模型不具备的能力,如逻辑推理、代码生成等,体现了量变引起质变。
- 多领域应用:广泛应用于文本生成、机器翻译、信息检索、摘要生成、聊天机器人等领域。
- 伦理和风险:LLM 也面临生成有害内容、隐私泄露、认知偏差等风险,需审慎研究和应用。
四、大语言模型文件结构解析
一个典型的开源 LLM 项目通常包含以下关键文件:
- gitignore:纯文本文件,指定 Git 忽略的文件和文件夹列表。
- MODEL_LICENSE:模型商用许可文件,规定使用权限。
- README.md:项目说明文档,介绍安装和使用方法。
- config.json:模型配置文件,包含层数、隐藏层大小、注意力头数、Transformers API 调用关系等参数,用于加载和配置预训练模型。
- configuration_*.py:模型配置的 Python 类文件,定义了配置类(如
ChatGLMConfig)。 - modeling_*.py:源码文件,定义模型结构和前向传播过程(如
ChatGLMForConditionalGeneration类)。 - model-XXXXX-of-XXXXX.safetensors:安全张量文件,保存模型权重。常用于 PyTorch/HuggingFace 生态,比传统 bin 文件更安全高效。
- model.safetensors.index.json:模型权重索引文件,提供 safetensors 文件的索引信息。
