Ollama 本地 CPU 部署开源大模型实战
Ollama 是一个用于在本地运行大型语言模型的开源工具,支持在 CPU 环境下高效推理。它基于 llama.cpp 实现,兼容 OpenAI API 接口,使得开发者可以方便地在本地部署如 Llama3、Gemma、Phi3、Qwen2 等开源模型。
本文将详细介绍 Ollama 的安装、命令行交互、Python 接口调用以及 Jupyter Notebook 中的魔法命令集成,并提供最佳实践建议。
一、安装与配置
1. 系统支持
Ollama 支持 macOS、Linux 和 Windows 操作系统。用户可以直接从官网下载对应平台的安装包进行安装。
- macOS: 提供 dmg 或 zip 包,解压后拖入应用程序即可。
- Linux: 推荐使用官方脚本一键安装。
- Windows: 提供 MSI 安装包,按向导完成安装。
2. Docker 部署(可选)
对于容器化环境,也可以使用 Docker 运行:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
3. 验证安装
安装完成后,在终端输入以下命令检查版本:
ollama --version
二、基础命令操作
Ollama 提供了丰富的 CLI 命令来管理模型和服务。
| 命令 | 描述 |
|---|---|
ollama run <model> | 运行指定模型,若未下载则自动拉取 |
ollama pull <model> | 从仓库拉取模型到本地 |
ollama list | 查看已下载的模型列表 |
ollama rm <model> | 删除指定的模型 |
ollama serve | 启动服务进程(通常安装后自动后台运行) |
ollama help | 查看所有可用命令及参数 |
示例:
# 下载并运行 Qwen2 模型
ollama run qwen2
# 下载 Llama3 模型
ollama pull llama3
# 查看本地模型
ollama list
三、命令行交互体验
通过命令行直接运行模型,可以快速测试对话效果。Ollama 默认监听 11434 端口,并在后台提供服务。
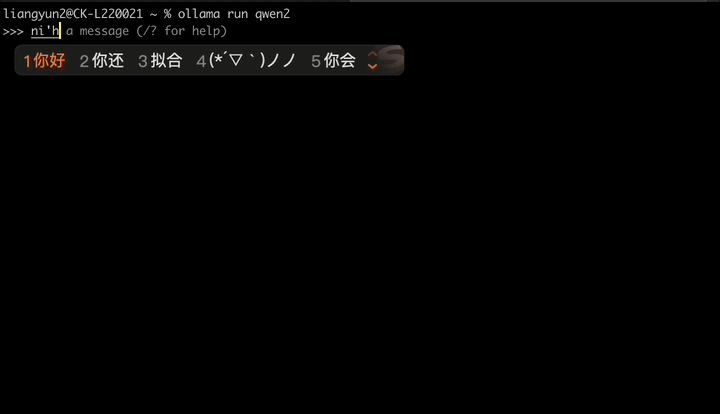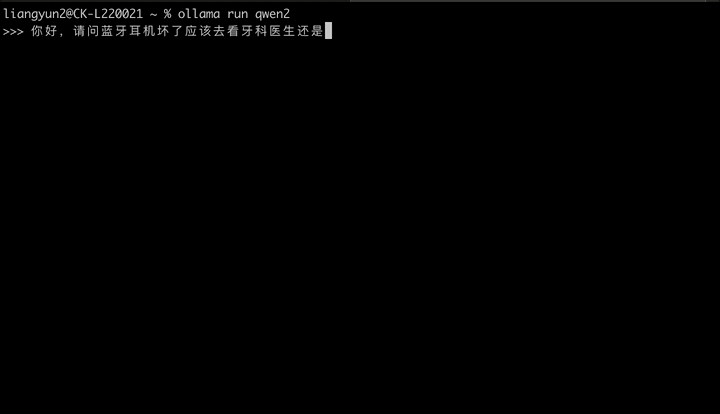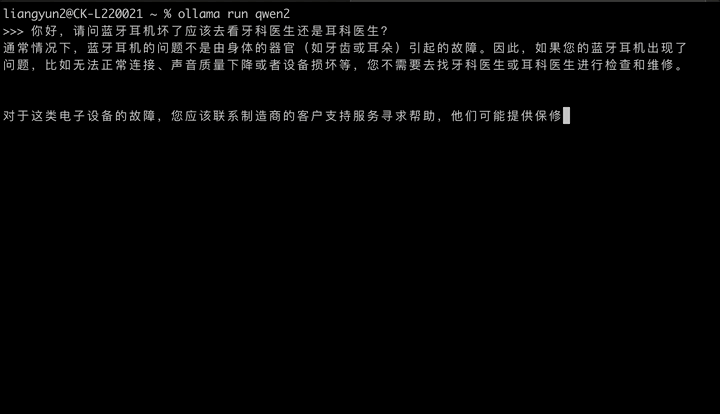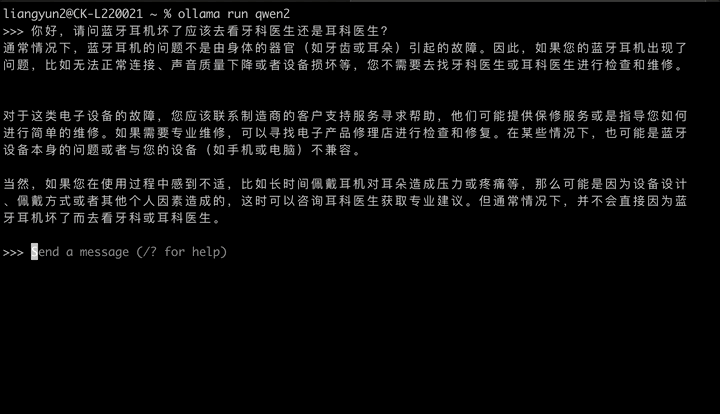
ollama run qwen2
> 你好,请介绍一下你自己。
> 我是一个人工智能助手...
此模式适合快速验证模型能力,但不适合程序化集成。
四、Python 接口交互
Ollama 支持两种 Python 交互方式:官方 SDK 和 OpenAI 兼容接口。这使得现有的 AI 应用可以轻松迁移到本地模型。
1. 使用官方 ollama-python 库
首先安装依赖:
