引言
随着人工智能浪潮的奔涌而来,企业间(B2B)的竞争日益激烈,企业不断寻求利用先进技术提升效率、降低成本并增强竞争优势。其中,Agent 技术以其灵活性和智能化成为 To B 市场的一大亮点。Agent 技术,尤其是数据分析 Agent(DataAgent),正在重新定义企业如何处理和分析大量数据,以便更好地理解市场动态、客户需求和业务运营。
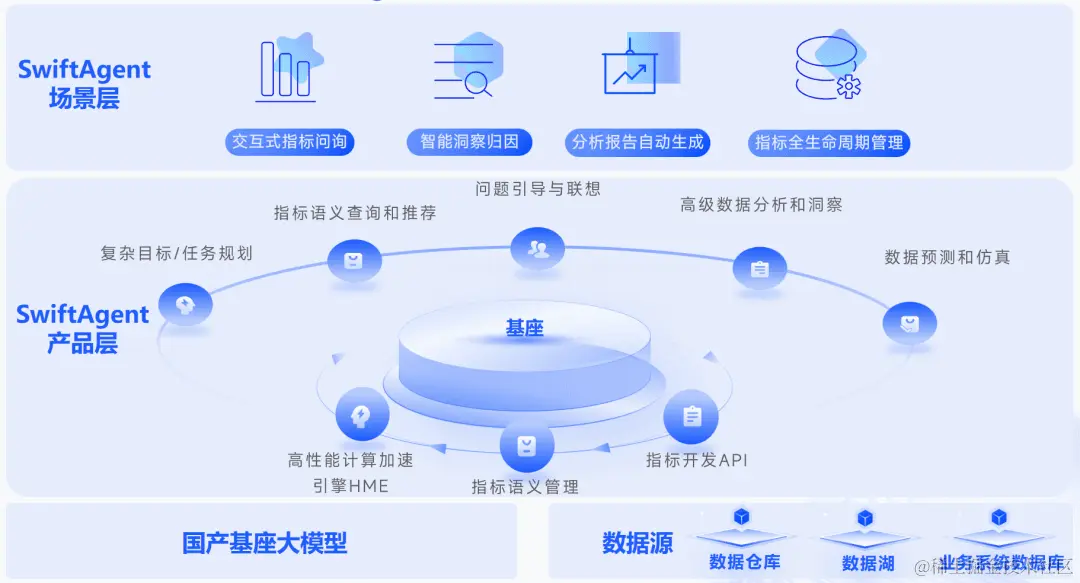
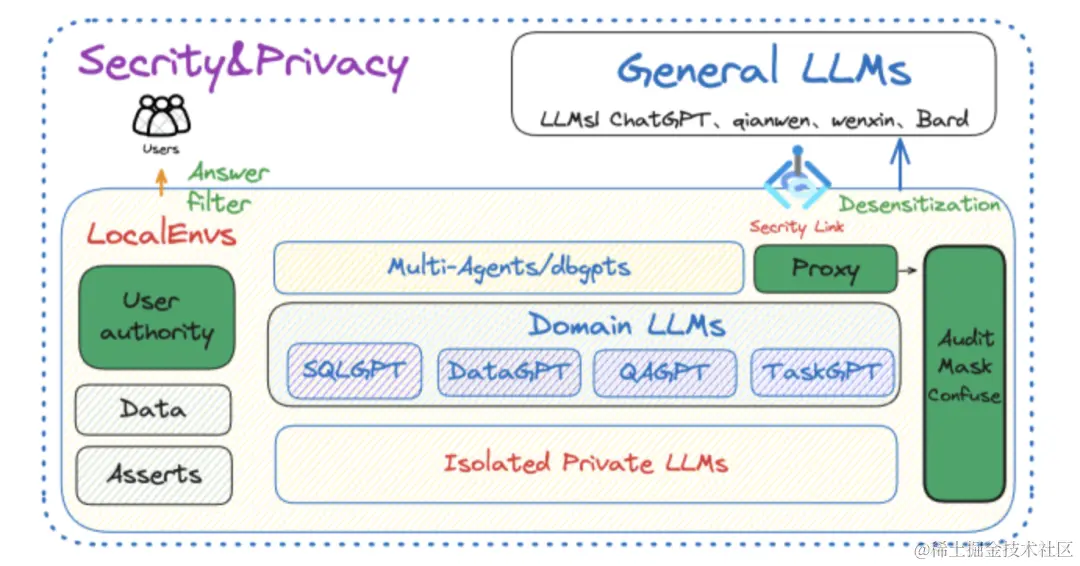
数据分析与商业智能(BI)在中大型企业的日常运营中至关重要。无论是基本的财务数据分析,还是涵盖对复杂的客户和运营数据进行深入洞察的需求,都需要借助专业的工具。传统 BI 工具使用门槛高、过度依赖技术部门、结果产出周期长的问题,在 AI 时代可以借助大模型的能力得以缓解。
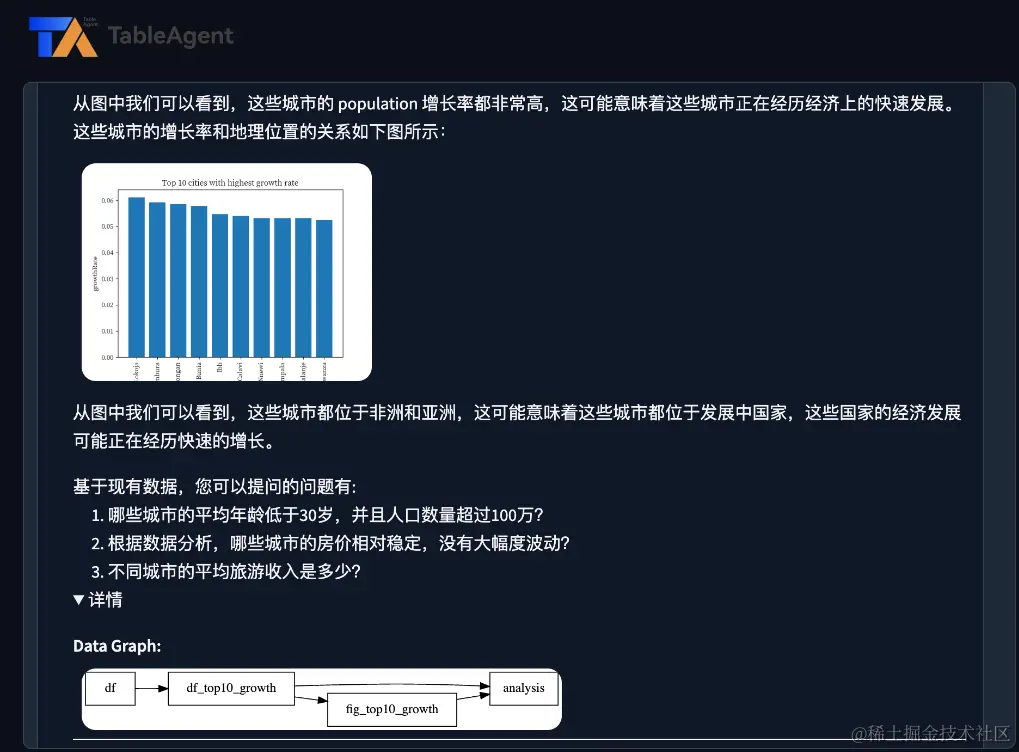
基于大模型的数据分析助手(Data Agent),可以以自然语言处理的方式进行数据分析任务,无需深入了解复杂的查询语言或编程技巧。这些 Data Agents 能够将自然语言指令转换为具体的数据操作,如 API 调用、数据库查询,甚至编写专门的数据分析脚本,实现数据的提取、分析和结果的可视化。这种方法的底层架构和工作原理将 AI 的先进能力与数据分析需求进行结合,可以降低 BI 工具的使用门槛,加快洞察的获取速度。
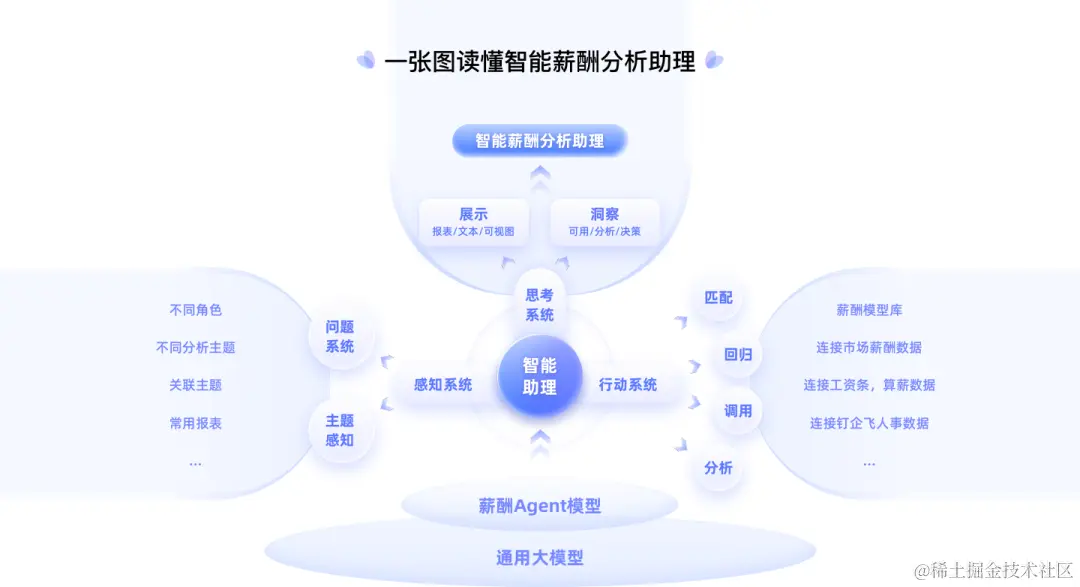
在一个 DataAgent 的开发过程中,主要涉及三个维度的核心关键因素:数据源、大模型、应用及可视化。
一、数据源
数据分析的第一步永远要回答一个问题:我们的数据从哪里来?针对现在主流 LLM 应用以及企业用户应用场景,大概可分为以下几个数据源。
结构化数据:
结构化数据应是目前作为首要考量的数据类型。一方面结构化数据处理难度更低,更好快速实现;另一方面企业中大部分数据都以结构化数据为主,这包括企业内部的各种业务系统,如销售系统、采购系统、库存管理系统、客户关系管理系统(CRM)、企业资源计划系统(ERP)等。
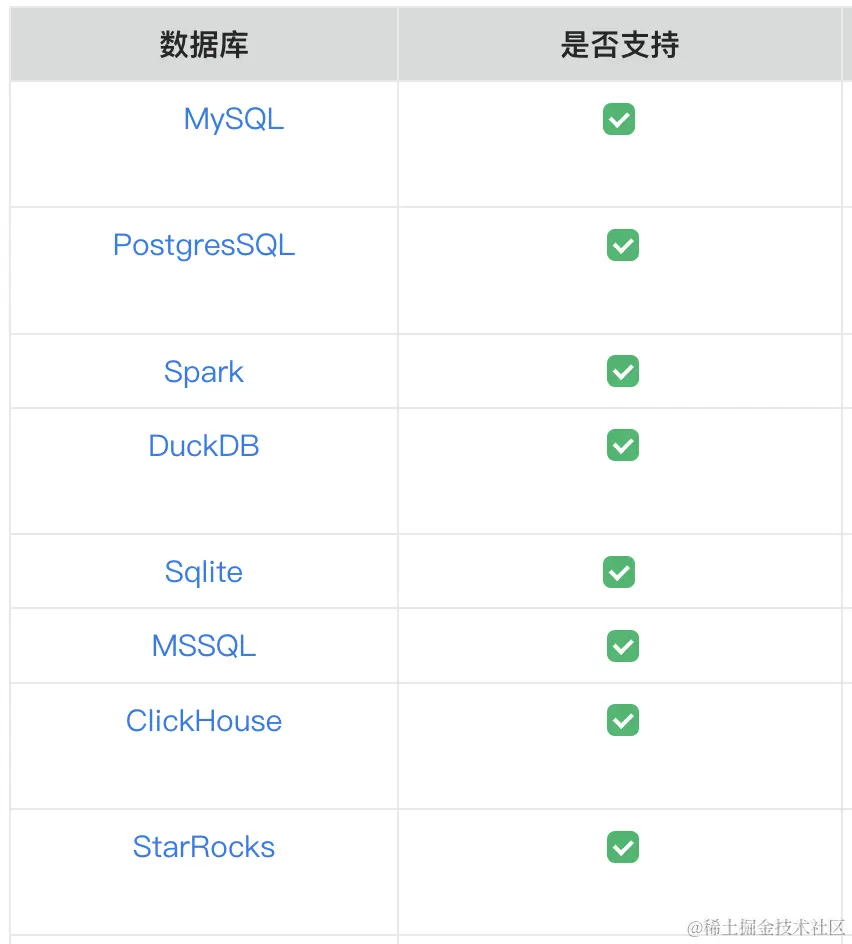
● 关系型数据库(至少可以要考虑支持 MySQL,Oracle,Microsoft SQL Server,PostgreSQL) ● 电子表格(如 Excel, Google Sheets) ● JSON/XML(轻量级数据交换格式) ● (可选)Hive(大数据仓库软件,用于处理存储在 Hadoop 中的大规模数据集) ● (可选)Spark DataFrames(分布式数据集合)
普通结构化数据需要在加载时对数据进行说明来帮助 LLM 理解数据,或者上传一个文件来帮助理解。对于数据库来说可以有两种交互方式:直接让 LLM 与数据库连接的侵入式,或者非侵入式。侵入式原理相对简单,LLM 直接连接数据库获取数据库的 schema 和 comment 来理解表单。而非侵入式一般依赖于特殊的架构,我们会在后面讨论。
半结构化数据:
半结构化数据介于结构化和非结构化之间,通常包含标签或其他标记来分隔元素和属性。
● Log 文件(如 Apache log, syslogs 等) ● Markdown(轻量级标记语言) ● XML/JSON 配置文件
处理半结构化数据通常需要解析器将其转化为键值对或树状结构,以便 LLM 能够理解上下文。例如,日志文件可以通过正则表达式提取关键字段后存入向量数据库。
非结构化数据:
传统的数据分析来讲一般不太涉及半结构化数据以及非结构化数据。一般为了从半结构化数据以及非结构化数据中提取有效信息,需要开发算法/模型进行数据的加载,如 OCR 模型,PDF 加载器。这部分数据是长久以来都是人们忽视的数据,但其中可能蕴含很多重要信息。比如,工业生产中的流水线机器日志,通过训练一个模型给他一份机器日志,预测机器是否损坏,损坏的部位,产生的零件良品率等。
从多模态的角度来讲,视频音频的引入固然可以为大模型带来自然语言无法描述或记录的数据/知识,但现阶段多模态分析性能并不理想。此外虽然现在主流数据分析 Agent 是以数据分析为主要目标,但未来也可以考虑将更底层的数据治理也包含进解决方案中。
● 照片(如 JPEG, PNG, GIF 等图像文件) ● 视频(如 MP4, AVI, MKV 等视频文件) ● 音频(如 MP3, WAV, FLAC 等音频文件) ● PDF 文档 ● Word 文档(如 DOC, DOCX) ● PowerPoint 演示文稿(如 PPT, PPTX) ● 电子邮件(如 Outlook PST, MBOX 等格式) ● Web 页面(HTML, CSS) ● 源代码(如 Python, Java, C++ 等)
二、模型
无论是对本地的 Excel 数据文件分析,或者对数据库中的关系型数据分析,又或者对互联网的非结构化数据分析,当前大模型实现数据分析的技术途径基本还是以三种方式为主:自然语言转 API、自然语言转 SQL、以及自然语言转代码。
自然语言转代码:
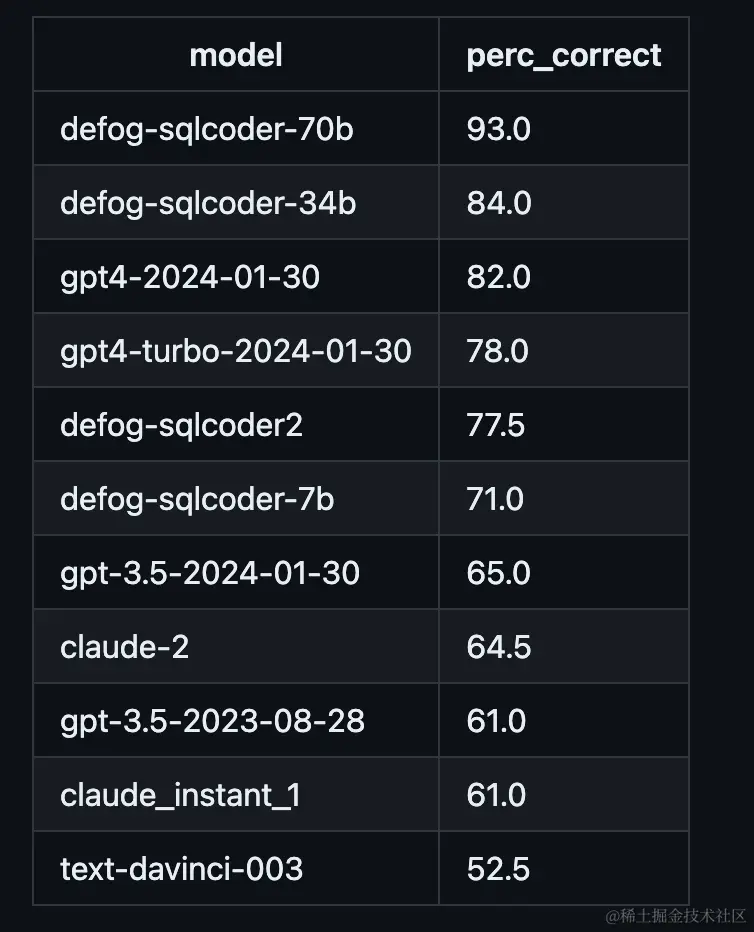
因为模型在训练数据中就有代码部分,所以大部分模型本身就有生成数据分析代码/SQL 语句的能力,并且参数越大的模型表现性能一般会更好。但需要注意的是参数越大也意味着需要硬件的性能也越高,一般情况下在 16 位的精度下 1B 参数需要 2-3GB 的显存。这种方式灵活性最高,适合复杂逻辑,但执行环境的安全控制要求较高。
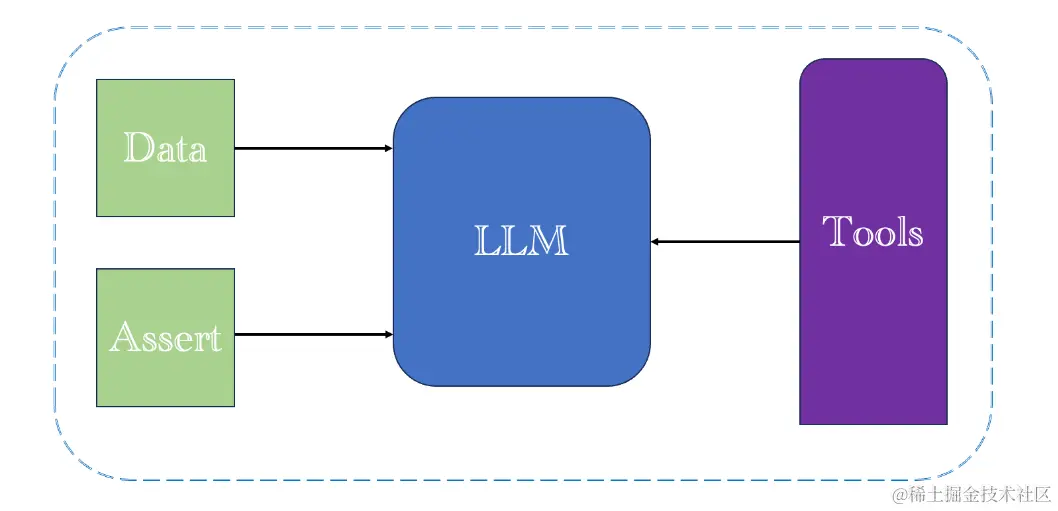
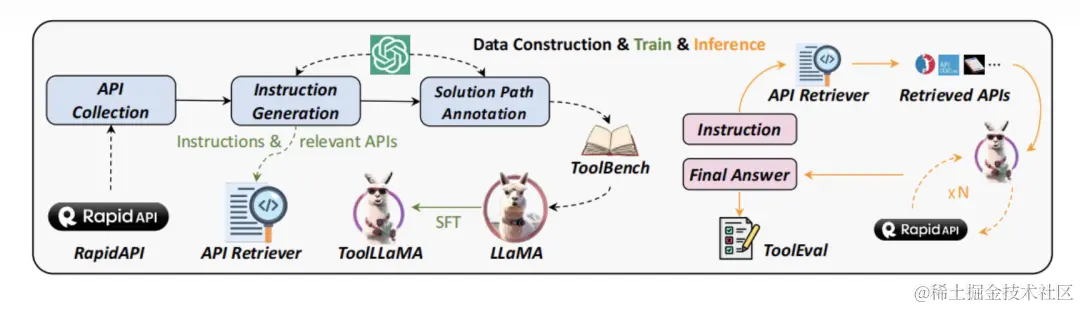 Toollama 结构示意图
Toollama 结构示意图