了解完嵌入模型、向量数据库相关知识后,在此基础上可以实现一个 RAG 本地问答系统。
什么 RAG?
RAG(Retrieval-Augmented Generation)检索增强生成,即大模型 LLM 在回答问题或生成文本前,会先从大量的文档中检索出相关信息,然后基于这些检索出的信息进行回答或生成文本,从而可以提高回答的质量,而不是任由 LLM 来发挥。
使用一个简单的公式来描述 RAG:RAG = 检索技术 + LLMs 提示
RAG 技术就是给大语言模型新知识,解决大模型的'AI 幻想症'、'无法获取领域知识'和数据安全性问题!!
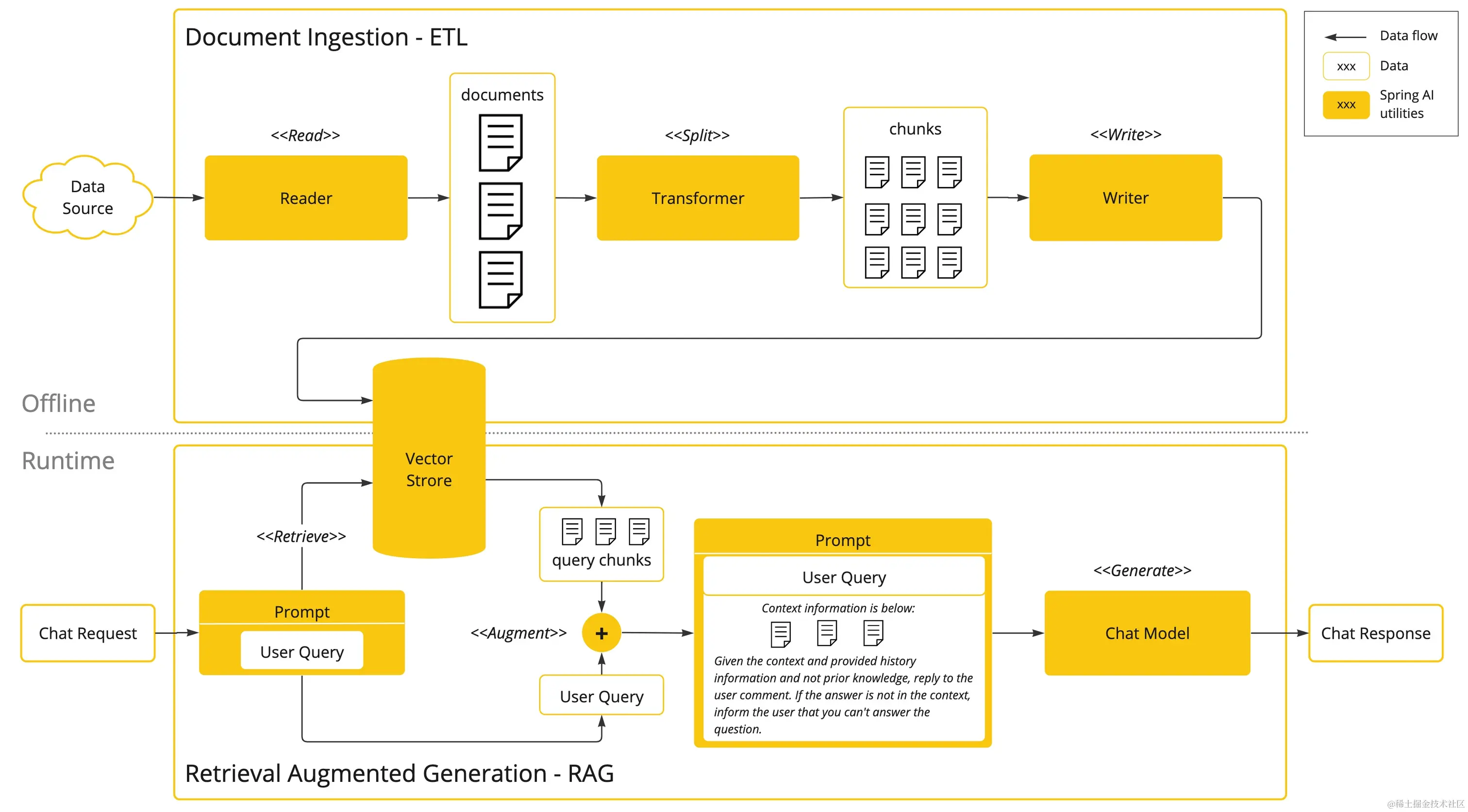
RAG 架构
架构由离线部分和在线部分两部分组成;
- 离线部分:数据读取 -> 文档拆分 -> 向量化 -> 数据存储
- 在线部分:用户提问 -> 数据检索(召回) -> prompt 拼装 -> LLM 生成
该架构为最简单的 RAG 架构,有关论文介绍了 RAG 的演化由朴素 RAG->高级 RAG->模块化 RAG,因此简单 RAG 是后续发展的理论基石,所以先将其掌握,在后续研究高级 RAG 加入了哪些优化,如何落地的。现在先仅实现一个简单的 RAG 问答系统。
离线部分 ETL Framework
对于 ETL 主要涉及到文件的读取、拆分、写入三个部分,将详细看下实现源码:
文件读取 DocumentReader
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
实现类:
- JsonReader:读取解析 Json 格式的文档
- TextReader:读取解析纯文本格式的文件
- TikaDocumentReader:从多种文档格式读取解析数据,包括像 PDF, DOC/DOCX, PPT/PPTX 和 HTML。底层使用 Apache tika 技术实现。
- PagePdfDocumentReader:以页的方式读取解析 PDF 文件,底层依赖 PdfBox 实现。
- ParagraphPdfDocumentReader:以段落的方式读取解析 PDF 文件,根据 TOC 目录结构。注意:并不是所有的 PDF 文件都包含 PDF catalog。
文件拆分 DocumentTransformer
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return (List)this.apply(transform);
}
}
其有 4 个实现类型,根据多种策略实现不同的类;
