
PythonAI算法
Python 爬虫副业指南:主流接单平台与注意事项
Python 爬虫作为副业的可行性,列举了国内外的主要接单平台如程序员客栈、Upwork 等,并探讨了技术栈准备、法律风险规避及定价策略。内容涵盖从入门到项目交付的全流程建议,帮助开发者利用爬虫技能获取额外收入,同时强调合规性与技术安全的重要性。
发布于 2025/2/736 浏览0 点赞
博客作者
人生只有一次
340
已发布文章
8.9K
博客获赞
611K
博客浏览
第 16 页
Python 爬虫作为副业的可行性,列举了国内外的主要接单平台如程序员客栈、Upwork 等,并探讨了技术栈准备、法律风险规避及定价策略。内容涵盖从入门到项目交付的全流程建议,帮助开发者利用爬虫技能获取额外收入,同时强调合规性与技术安全的重要性。

垂直领域大模型微调涉及基座模型选择、架构设计、数据构建及训练策略。核心经验包括:医学场景推荐 BLOOMZ 模型;架构上建议结合知识库与微调模型;数据方面强调质量优于数量,需防灾难性遗忘并控制噪音;训练时需平衡预训练与微调比例,注意指令微调轮次,根据参数量选择全参数或 LoRA/QLoRA 方案,并关注优化器与显存管理。

AI 大模型的基本原理,包括神经网络结构与权重机制。介绍了 LangChain 框架及 RAG 检索增强生成技术的作用。详细说明了开发环境的配置步骤,涵盖 Git SSH 密钥生成、Conda 虚拟环境搭建、项目依赖安装及 NLTK 资源下载。最后梳理了从基础理解到私有化部署的系统化学习路径,适合希望入门大模型应用的开发者参考。

全面解析了大语言模型(LLM)的原理、构建及应用。内容涵盖语言模型进化历程,从统计模型到 Transformer 架构的演变;重点介绍了 GPT、LLaMA、PaLM 等主流模型家族的特性。详细阐述了模型构建的关键步骤,包括数据清洗、分词、位置编码、预训练、微调(如 LoRA)及对齐技术(RLHF、DPO)。探讨了模型的实际应用、局限性(如幻觉、记忆缺失)及…

系统梳理了 AI 产品经理面试的核心考点,涵盖机器学习与深度学习基础算法原理、AIGC 底层技术架构及 100 道高频面试题。内容包括 KNN、SVM、CNN、Transformer 等经典模型的技术解析,以及从技术背景、工作场景、产品素养到行业认知的全方位问答指南。文章旨在帮助求职者建立完整的知识体系,掌握算法选型、数据治理及项目落地流程,提升面试竞争力。

基于华为及多家大厂 AIGC 产品经理面试经历,梳理了业务、总监及 HR 三轮面试的核心问题。重点涵盖 AI Agent 架构设计、RAG 检索增强生成优化、Prompt 工程技巧、向量库选型及模型内容安全等关键技术点。同时总结了从算法工程师转型产品岗位的通用路径,为求职者提供系统化的备考方向与行业认知参考。

探讨了 AI 大模型时代提示词工程的演变。随着 DeepSeek 等模型具备更强的意图理解能力,传统的指令式提示词正逐渐向意图预测型交互转变。文章分析了从服从指令到预测意图的范式转移,指出基础指令趋于隐形化,而创意提示成为激发 AI 潜力的关键。同时强调了人类在需求洞察力和创意连接力上的核心价值,并介绍了 CO-STAR 框架及结构化提示词的最佳实践。最终结…

AI 数字人制作中图像无缝融合的两种核心技术:拉普拉斯金字塔融合与泊松融合。拉普拉斯金字塔通过多尺度分解与重建,适合保留高频细节;泊松融合基于梯度域编辑,能实现光照自适应的平滑过渡。文章提供了完整的 Python 代码示例,详细解析了 OpenCV 中相关函数的用法及参数含义,并对比了两种算法的适用场景与优缺点,为实际开发提供技术参考。

介绍 AI 大语言模型与传统搜索引擎的区别,涵盖提问技巧如逻辑推导、认知检验及反向提问。详细解析插件应用,包括联网搜索、计算绘图及多模态生成。阐述 GPT 自定义功能、图像局部修改及语音交互特性。提供结构化思考方法 MECE 与 SPA 问题解决模型,并给出 AI 产品经理的学习路线图,涵盖系统设计、提示词工程、平台开发至微调训练的全流程技能提升建议。

DeepSeek-R1 利用大规模强化学习在推理任务上表现优异。解析如何通过知识蒸馏技术,将 R1 的推理能力迁移至参数量更小的 Qwen 模型。核心步骤包括构建结构化模板引导生成、使用拒绝采样筛选高质量推理轨迹、以及基于监督微调的对齐训练。该技术实现了'以大带小'的能力迁移,使小模型在资源受限场景下也能处理复杂推理任务,为 AI 模型的轻量化部署提供了有效…

Python 深度学习框架 TensorFlow 的核心概念与实战应用。内容涵盖深度学习基础、TensorFlow 的安装与环境配置、张量与变量的操作、计算图机制、神经网络构建流程(包括损失函数与优化器)、以及图像识别、语音识别和自然语言处理等典型应用场景。文章通过代码示例演示了如何从零构建并训练一个简单的神经网络,并对常见实践与注意事项进行了总结,旨在帮助…

构建基于 Python Unittest 的自动化测试框架,利用 Excel 管理用例数据并通过自定义装饰器实现数据驱动测试。框架整合 Jinja2 模板引擎生成 HTML 可视化报告,支持日志记录与结果回显。同时集成邮件、钉钉及企业微信通知机制,实现测试流程的自动化闭环与团队信息同步。

Python 提供了 pandas 和 openpyxl 等库用于处理 Excel 文件。介绍如何安装依赖、读取指定 Sheet 数据、写入新文件以及修改现有单元格内容。通过示例代码展示了 DataFrame 转换、样式设置及异常处理机制,帮助开发者高效完成数据自动化任务。

详细解析了 Python 字典的内部实现原理,涵盖核心数据结构 PyDictObject、PyDictKeysObject 及 PyDictKeyEntry 的定义与用途。内容深入探讨了字典初始化流程、插入查找删除操作的底层字节码与 C 源码逻辑,重点分析了哈希表机制、哈希冲突解决策略(开放寻址法)及哈希攻击防御。文章还补充了字典的性能特点、空间开销分析及最…

AI 短视频制作涵盖文本生成视频、图片生成视频及视频生成视频三种核心模式。文本生成视频利用 NLP 和 TTS 技术将文案转化为视听内容;图片生成视频通过序列帧合成实现静态图动态化;视频生成视频则基于 GAN 或扩散模型进行风格迁移或内容重构。各模式的工作原理、标准工作流程及 Python 代码实现,涵盖 MoviePy、gTTS 及 TensorFlow…

大语言模型在多位数运算上存在困难,主要源于 Tokenizer 切分策略、Next Token 预测机制、位置编码及长度外推能力等限制。通过优化数字切分、采用逆序输入、引入对齐提示符与特殊位置编码(如 Abacus Embedding)、使用 FIRE 相对位置编码及随机化位置编码技巧,可显著提升计算准确率。然而,受限于模型幻觉概率,完美准确率仍具挑战,通常…
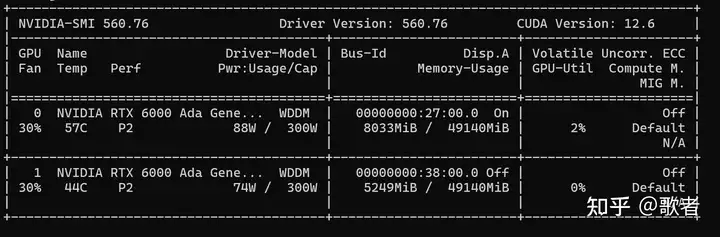
探讨了个人本地部署 7B 至 70B 大模型的硬件配置方案。核心在于显存容量,推理显存估算公式为模型参数量乘以量化位数除以 8。推荐配置包括 32-64 核 CPU、128GB 以上内存及高速 SSD。GPU 选择上,根据预算可从 RTX 3090/4090 到 A100/H100 不等,需注意多卡通信效率损耗。实测显示双卡 RTX 6000 Ada 可流畅…

Android IM 开发指南,基于 Smack 客户端库与 Openfire 服务端搭建。涵盖服务器环境配置、Gradle 依赖引入、XMPP 连接建立、用户注册登录流程、消息收发实现及离线消息处理。重点展示连接监听、自动重连机制及在线状态管理,提供完整的 Java 代码示例,帮助开发者快速构建即时通讯功能模块。

详细阐述了 AI 产品经理的进阶路线,涵盖人工智能产业链结构、行业架构、产品经理四象限分类及岗位布局。文章指出 AI 产品经理需具备 AI 思维,区分突破型、创新型、应用型及普及型四类角色,并针对常见误区提出能力提升建议。内容强调技术理解、数据分析、商业敏感度及跨学科知识的重要性,展望了 AIGC 时代下 AI 产品经理角色的转变,即从功能定义转向人机协作引…

利用 Python 对知乎平台用户数据进行采集与分析的技术方案。通过构建初始用户群体并追踪关注关系,识别出特定兴趣圈层的高频互动用户。数据分析涵盖了话题偏好、职业分布及地理位置等维度,揭示了程序员群体在特定社交网络中的活跃度。文章详细描述了数据采集的四个步骤、技术实现细节(如 Redis 存储、Pandas 分析)以及反爬策略。同时,重点探讨了数据采集过程中…