
PythonAI算法
Sentence-BERT 句嵌入模型介绍与实践
Sentence-BERT 是一种基于 BERT 的句嵌入模型,通过孪生网络结构实现高效的语义相似度计算。 Embedding 技术原理,对比了传统 BERT 与 Sentence-BERT 的差异,并提供了基于 PyTorch 和 HuggingFace 库的训练与检索实践方案。内容包括环境配置、数据预处理、模型搭建、损失函数选择及余弦相似度检索流程,旨在…
发布于 2025/2/725 浏览0 点赞
博客作者
数据流工程师
382
已发布文章
17K
博客获赞
790K
博客浏览
第 18 页
Sentence-BERT 是一种基于 BERT 的句嵌入模型,通过孪生网络结构实现高效的语义相似度计算。 Embedding 技术原理,对比了传统 BERT 与 Sentence-BERT 的差异,并提供了基于 PyTorch 和 HuggingFace 库的训练与检索实践方案。内容包括环境配置、数据预处理、模型搭建、损失函数选择及余弦相似度检索流程,旨在…

探讨了 LangChain 在工程实践中逐渐被弃用的原因。主要观点包括:LangChain 的高层抽象导致生产环境调试困难,增加了认知负荷;复杂的 Agent 架构受限于框架灵活性;团队花费过多时间理解框架而非构建业务逻辑。尽管 LangChain 提供了丰富的组件,但在 LLM 领域快速变化下,简单的原生代码或特定工具(如 LangSmith)可能更适合长…

基于微软论文研究了大语言模型微调的优化技术。重点分析了梯度检查点、LoRA、DeepSpeed ZeRO 和 Flash Attention 四种技术对 GPU 内存和运行时间的影响。实验表明,ZeRO-2 结合 LoRA 是平衡内存与运行时的最佳默认选项;ZeRO-3 配合 LoRA 及 CPU 卸载可支持数十亿参数模型的微调。Flash Attentio…

深入探讨了基于大型语言模型(LLM)的智能体(Agent)架构及其核心组件。涵盖了智能体的大脑规划、记忆管理、工具调用机制以及面临的挑战与解决方案。重点分析了思维链、ReAct 等规划方法,短期与长期记忆的实现方式,以及函数调用在扩展 LLM 能力中的作用。同时提供了构建高效、安全智能体的实践建议与技术展望。

如何在本地通过 Ollama 工具部署和运行 Meta 发布的 Llama 3.1 大语言模型。内容涵盖系统环境要求、安装步骤、模型下载与交互、本地 API 服务开启以及常见问题的排查方法,帮助用户快速搭建私有化大模型环境并进行基础测试。

深入探讨了检索增强生成(RAG)技术的原理、工作流程及其与大模型微调的对比。文章分析了 RAG 在解决大模型幻觉、知识更新滞后及领域专业性不足方面的优势,同时也指出了检索精确率低、召回率不足、上下文窗口限制及运维成本高等核心挑战。针对这些问题,提出了包括混合检索、重排序、查询改写、模型蒸馏及高级 RAG 架构在内的性能提升方案,为构建高效可靠的 RAG 系统…

Agentic RAG 技术及其在复杂多文档问答中的应用。通过构建文档智能体与元智能体架构,结合 LangChain、OpenAI 及 FAISS 向量存储,实现了具备工具调用能力的检索增强生成系统。内容涵盖环境配置、RAG 链构建、LangGraph 工作流设计以及实际问答测试,展示了如何利用外部搜索与学术检索工具提升 LLM 回答的准确性与时效性。

推荐了九本关于大模型应用的优质图书,涵盖智能文本处理、推荐系统、信息检索、AI 助理、数据分析、Prompt 工程及 AI 绘画等领域。同时梳理了从系统设计、提示词工程、平台开发、知识库构建、微调开发到多模态及行业应用的七阶段学习路径,旨在帮助读者系统掌握大模型技术,解决实际工作问题。

探讨了人工智能时代产品经理的角色转变与核心能力要求。内容涵盖 AI 产品的特殊性、行业分析维度、需求量化方法、AI 产品体系架构(基础设施、数据、安全)、机器学习基础及工作流程。同时提供了从系统设计、提示词工程到模型微调的完整学习路径,旨在帮助从业者构建知识体系,掌握软硬实力,实现职业转型与升级。

近期上市银行中报中大模型的应用进展。国有大行中工行与邮储银行重视度最高,分别完成了全栈自主可控部署和千亿级算力集群建设。股份行如招行、中信、平安等在生态建设和垂直场景落地方面表现积极。中小银行通过引入外部合作或自建平台实现差异化竞争。关键技术趋势包括 RAG 检索增强、私有化部署、MaaS 平台及多模态融合。尽管面临数据安全、成本和人才挑战,大模型正从试点走…

在本地 Mac M3 环境下私有化部署 Llama 大模型的两种主流方案:GPT4All 和 Ollama 配合 Open WebUI。内容涵盖软件安装、模型下载配置、文档向量检索功能以及图形化界面使用。对比了两种方案的优缺点,如 GPT4All 的便捷性与聊天记录丢失问题,Ollama 的多模型支持与 Docker 部署优势。同时补充了硬件要求、Token…

推荐了三本 AI 大模型开发领域的核心书籍。《AI 大模型开发之路》适合初学者,涵盖环境配置、LangChain 框架及部署实战;《大规模语言模型》侧重理论基础,深入讲解预训练、微调及强化学习,适合有数学基础的开发者;《动手做 AI Agent》聚焦智能体开发,通过图解和实例解析 Agent 设计与实现。读者可根据自身技术背景选择相应书籍,从入门到进阶系统掌…

2024 年中文大模型技术综述。涵盖模型定义、核心能力如文本生成与语义理解。详解提示词工程、LangChain 框架应用、知识库构建及微调策略。分析电商、物流、医疗等行业落地场景。提供从入门到部署的全栈开发路径,助力开发者掌握 GPU 算力与垂直领域训练技能,应对大数据时代需求。

详细阐述了 AI 产品经理的职业发展路径,涵盖构建资源网络、参加专业课程、获取实操经验、整理作品集、扩展人脉、求职及面试准备等七个关键步骤。文章强调了技术洞察与产品思维的平衡,介绍了如 Cursor、Firebase、Stripe 等实用工具在原型构建中的应用,并指出跨学科思维、数据驱动决策及伦理意识是成为卓越 AI 产品经理的核心素质。旨在帮助读者系统掌握…
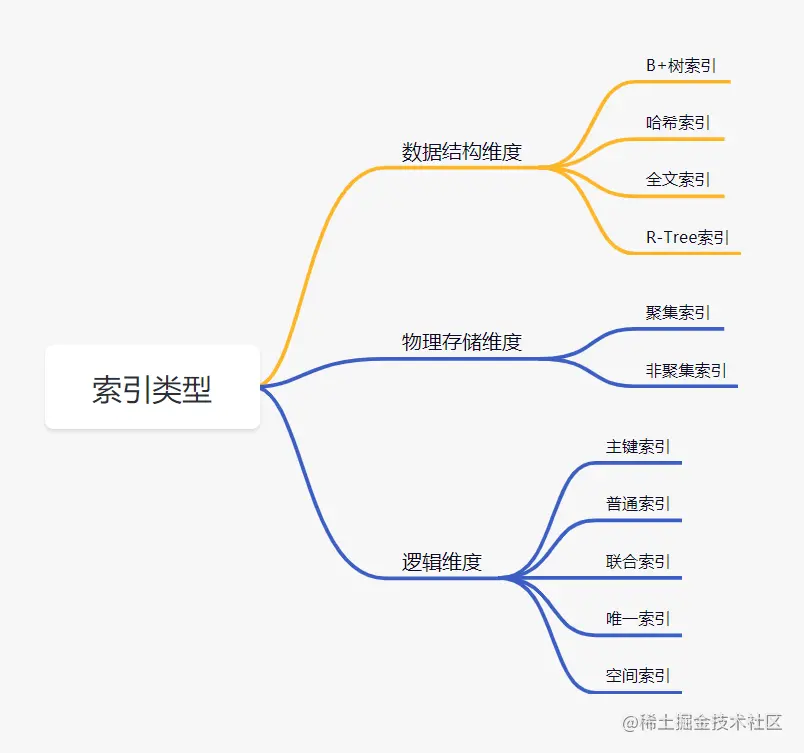
对三年经验后端工程师整理了一份核心面试题集,涵盖 MySQL 索引失效场景、存储引擎对比、主从同步原理,Redis 持久化与淘汰策略、ZSet 实现,Java HashMap 底层机制、IO 多路复用,以及 HTTP/HTTPS 加密流程、Raft 共识算法、MQ 高可用与不丢消息保障,最后附带滑动窗口算法题解。内容经过清洗与补全,去除无关推广信息,旨在提供…

探讨了 To B 领域最容易落地的 Agent 场景 DataAgent。文章详细分析了 DataAgent 的核心架构,涵盖数据源(结构化、半结构化、非结构化)、模型技术路径(Text-to-SQL、Text-to-Code、Text-to-API)及应用场景(自助分析、预测、可视化)。文中介绍了用友、九章云极、数势科技等商业案例,并对比了 Open In…

ChatBI Agent 架构包含规划、工具、行动和记忆四大模块。规划模块利用思维树、少样本学习等策略制定任务;工具模块提供代码解析与数据库支持;行动模块处理多轮对话;记忆模块管理长短期信息。文章结合电信运营商数据统计案例,展示了从任务规划到数据执行的全流程实现,通过 Python 与 SQL 集成完成复杂数据分析任务。

AI 技术正深刻改变各行各业运作模式,推动 AI 产品经理成为热门职业。该角色需具备技术理解力、行业洞察及用户导向能力,充当技术与商业的桥梁。随着企业数字化转型加速,人才缺口扩大,职业发展路径广阔。同时面临伦理法规挑战,要求从业者持续学习并关注社会责任。

分享了一位研二学生从零产品经验到成功入职 B 端产品经理岗位的求职经历。面对缺乏实际项目经验的困境,通过优化简历结构、构建作品集、系统学习产品技能及模拟面试,最终打破僵局获得 Offer。核心建议包括利用 STAR 法则重写经历、产出竞品分析与 PRD 文档作为能力证明,以及保持行动力克服焦虑。适合希望转岗或入行的求职者参考。

对三十岁左右人群面临的失业问题,提供了系统的应对策略。文章首先引导读者正确看待失业,强调心态调整的重要性;其次建议通过 SWOT 分析进行自我评估与定位;接着详细阐述了简历优化、渠道拓展及面试准备的实战技巧;最后探讨了持续学习、技能提升及自由职业等备选方案。核心观点在于通过科学规划和积极行动,将职业空窗期转化为转型机遇,实现职业生涯的可持续发展。