
PythonAI算法
基于 AI 大模型的图像 OCR 识别实践与对比分析
探讨了利用 AI 大模型进行图像 OCR 识别的技术方案。首先介绍了 OCR 技术背景及 LLM 在文本理解、格式修复和多模态融合方面的优势,同时分析了高计算成本、数据隐私等缺点。通过图形验证码识别案例,对比了文心一言、通义千问等主流模型的表现,并提供了基于阿里云 DashScope API 的 Python 代码实现。文章还讨论了开源模型(Qwen2-VL…
发布于 2025/2/726 浏览0 点赞
博客作者
.NET开发者
341
已发布文章
11K
博客获赞
798K
博客浏览
第 16 页
探讨了利用 AI 大模型进行图像 OCR 识别的技术方案。首先介绍了 OCR 技术背景及 LLM 在文本理解、格式修复和多模态融合方面的优势,同时分析了高计算成本、数据隐私等缺点。通过图形验证码识别案例,对比了文心一言、通义千问等主流模型的表现,并提供了基于阿里云 DashScope API 的 Python 代码实现。文章还讨论了开源模型(Qwen2-VL…

大模型落地主要通过私有化部署和公有云 API 两种模式,后者因成本低、灵活性高成为主流。这一趋势促使云计算竞争从单纯售卖算力转向框架、模型及生态的竞争。头部厂商如 AWS、阿里云等通过构建开放模型生态、降低 API 价格及深度绑定自研模型来争夺市场。随着成本降低,API 调用量预计大幅增长,且大模型与云厂商深度绑定导致迁移成本高企。当前 IaaS 和 Paa…

大模型应用落地面临数据质量、计算资源、系统集成及伦理安全等多重挑战。深入分析了这些难点,并提出数据工程优化、模型轻量化、MLOps 架构及 RAG 等技术解决方案。通过医疗影像诊断的具体案例,阐述了联邦学习、边缘计算及可解释性技术在垂直领域的应用实践。文章强调需建立科学评估体系与人机协同机制,以实现大模型从实验到生产的平稳过渡。

文章详细分析了进入互联网大厂算法工程师岗位所需的核心条件。主要涵盖教育背景(硕士及以上、名校偏好)、公司项目背景(业务匹配度、跨域转型难度)、技术能力(经典与深度学习模型、框架语言、工程化落地)、学术与竞赛成果(顶会论文、Kaggle 名次、开源贡献)以及面试准备策略。内容旨在帮助求职者全面了解岗位要求,制定合理的职业规划与能力提升路径。

程序缺陷修复涉及了解、复现、定位、确认、修复、验证六个标准步骤。高效修复依赖准确的信息收集、完备的日志体系及自动化测试机制。提升定位效率需掌握断点调试、日志分析等方法。长期来看,深入理解语言特性、架构设计、性能优化及源码阅读是解决复杂问题的根本途径。持续积累业务知识与技术经验,才能从根本上减少缺陷产生并提升开发质量。

LLaMA-Factory 是一个统一的大模型微调框架,集成了多种高效训练方法如 LoRA、QLoRA、GaLore 等,支持 100 多个模型和 50 多个数据集。该框架通过模型加载器、数据处理器和训练器三大模块,结合 FlashAttention-2、Unsloth 等技术,大幅降低显存占用并提升训练效率。用户可通过 WebUI 或命令行进行全参数、冻结…

Meta 发布了 Llama 3.1 系列大语言模型,包含 8B、70B 和 405B 三种参数规模。新模型支持 128K 上下文窗口,在 MMLU 及 HumanEval 等基准测试中表现超越 GPT-4。文章详细介绍了其技术规格、多语言支持与安全性,对比了与竞品的性能差异,并提供了基于 Hugging Face Transformers 的 Python…

精选了 2024 年大模型入门与人工智能基础领域的优质书籍。涵盖《GPT 图解》、《大模型应用开发》、《动手学深度学习》等经典教材,内容涉及自然语言处理核心原理、AI Agent 设计、AWS 生成式 AI 实战及强化学习等。旨在帮助读者系统构建 AI 知识体系,从理论基础到工程实践全面掌握大模型技术。

介绍如何在本地离线部署清华 ChatGLM3 大模型。需准备高性能显卡(显存 13G+)和内存(32G+)。通过 Git 克隆项目并下载模型文件,配置 Conda 虚拟环境及 Python 依赖。修改客户端配置文件指向本地模型路径后,使用 Streamlit 启动 Web 服务。支持对话、工具调用及代码解释器模式,确保数据隐私安全的同时享受 AIGC 功能。

详细阐述了大语言模型(LLM)中超参数的定义、分类及调优方法。内容涵盖模型大小、迭代次数、学习率、批大小、最大输出 token、解码类型、Top-k/p 采样、温度、停止序列及惩罚机制等核心参数。文章对比了随机搜索、网格搜索和贝叶斯优化三种调优策略,并结合实际工程场景讨论了延迟、成本、安全与可复现性等考量因素,为开发者提供了一套系统的 LLM 参数配置与优化…

探讨了知识图谱与大语言模型(LLM)的结合方式及其在构建智能应用新生态中的作用。文章首先分析了两者的特点与互补性,指出知识图谱能提供结构化、高真实性的知识以减轻大模型幻觉,而大模型则能自动化构建和补全知识图谱。接着详细阐述了大模型增强知识图谱的具体路径,包括实体抽取、关系抽取及联合推理;同时介绍了知识图谱如何通过预训练数据注入、检索增强生成(RAG)及可解释…

大模型应用架构通过知识图谱增强方案解决预训练模型在时效性与准确性上的局限。架构设计遵循集成性、灵活性与工具化原则,核心模块涵盖数据管理、标注、模型、提示工程、知识建模及应用层。关键技术包括知识图谱的结构化推理、向量检索的语义匹配、搜索引擎的实时信息获取及业务引擎的场景适配。应用场景覆盖医疗、智能客服、金融科技及智能制造等领域。实施中需注意数据一致性、延迟控制…

如何使用 LangChain 的 Agents 模块实现灵活的检索增强生成(RAG)系统。通过将 Retriever 封装为工具,使大模型能够自主判断何时调用检索器,从而在必要时检索外部知识,无需检索时直接使用模型原有能力。文章详细讲解了构建检索器、封装工具、配置 Prompt 及模型、创建 Agent 执行器的完整流程,并分析了不同场景下的运行结果。此外,…

检索增强生成(RAG)是解决大模型知识幻觉的关键技术。基于 LangChain 框架,详细讲解了搭建最小化 RAG 系统的完整流程。内容涵盖环境配置、数据加载与切片、BGE 向量化模型集成、Chroma 向量数据库存储、检索器构建以及 LCEL 链式生成逻辑。文章还分析了简单 RAG 系统常见的幻觉与检索精度问题,并提出了混合检索、重排序等优化方向,为开发者…

详细梳理了阿里、字节、百度、腾讯、拼多多等互联网大厂的产品经理面试真题,涵盖项目经验、专业技能、行业认知、创新思维等维度,并提供参考回答思路。文章还补充了 AI 产品经理的核心能力模型,包括技术理解力、提示词工程、数据敏感度、伦理合规及场景落地能力,旨在帮助求职者系统准备面试,提升核心竞争力。

AI 产品经理是连接技术与业务的关键角色。梳理了 AI 产品经理的能力模型,涵盖沟通协作与行业认知;回顾了人工智能从图灵测试到深度学习的发展历史;解析了监督学习、强化学习等核心概念及弱/强人工智能的区别;最后提供了系统的学习路径建议,帮助从业者掌握基础算法与框架知识,实现职业转型。
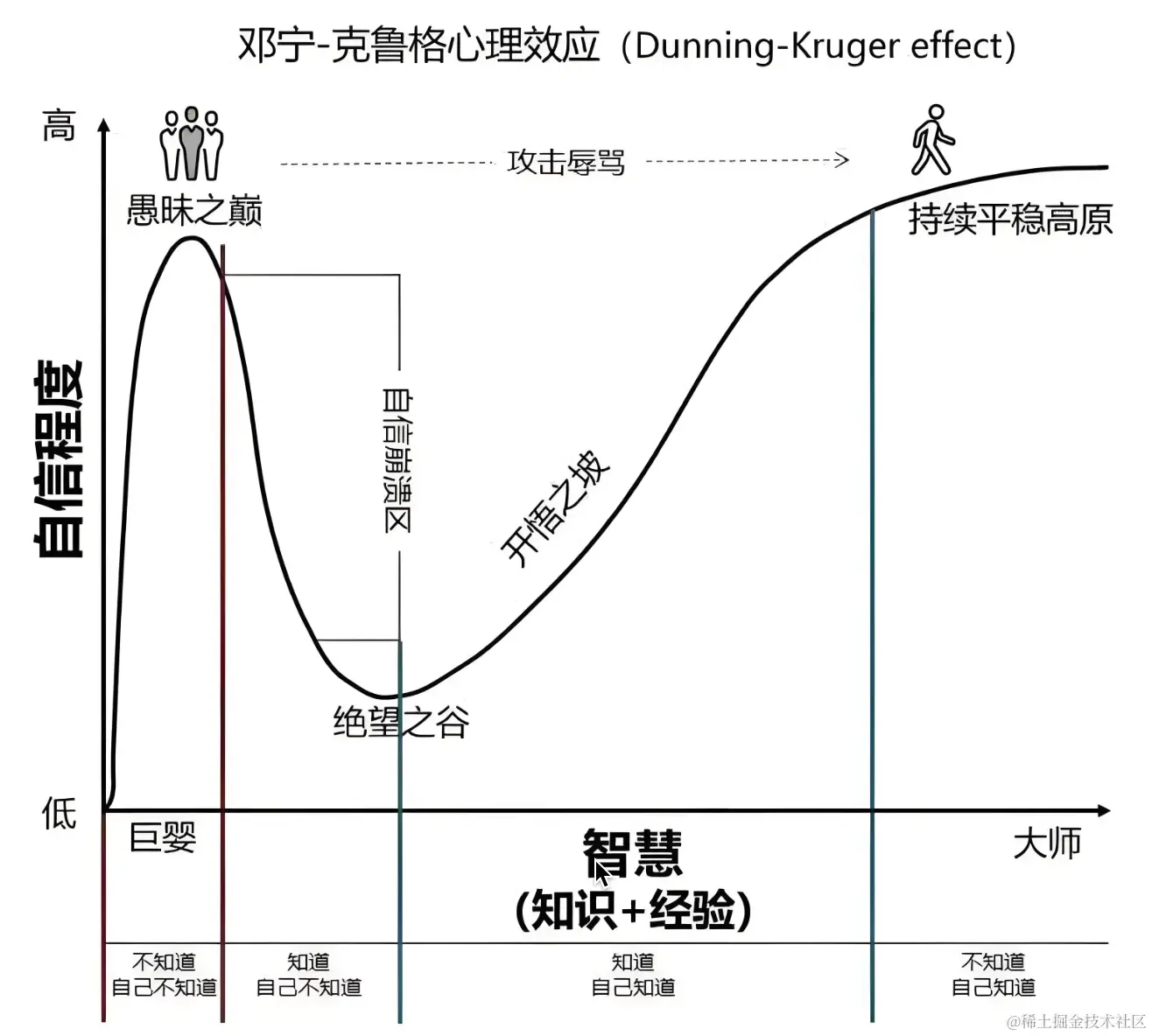
程序员常陷入学习越多越焦虑的怪圈,根源在于缺乏系统的知识体系。通过分析人类认知曲线,剖析职场焦虑成因,提出通过抽象思维、底层逻辑学习和知识关联构建来打破困境。建议从掌握核心原理出发,建立个人技术地图,以长期主义心态应对技术迭代,实现从量变到质变的成长。

在个人设备本地部署开源大模型的方法。重点讲解了 Meta 的 Llama 3 和微软的 Phi-3 两款轻量级模型的特性。通过 Ollama 工具在 Windows 电脑上实现一键运行,并利用 Termux 配合 proot-distro 在 Android 手机上构建 Linux 环境进行部署。文章对比了两种模型在响应速度、中文能力及代码生成方面的表现,提…

探讨了生成式 AI 在游戏开发与内容创作领域的应用实践。通过分析《细胞防线》等案例,介绍了利用大语言模型辅助代码生成、AI 绘画工具制作美术资源以及引擎集成的完整工作流。同时,文章还分析了 AI 在自媒体文案、虚拟模特及平面设计等其他行业的价值。内容强调了提示词工程的重要性,指出人机协作将成为未来职业技能的核心趋势,帮助读者理解如何利用 AI 技术提升生产力…

系统梳理了 Python 从基础语法到高级特性的完整知识体系,涵盖数据类型、函数编程、面向对象、模块使用及文件操作等核心内容。通过详解运算符、变量作用域、装饰器原理及爬虫基础,辅以代码示例帮助读者快速掌握 Python 开发规范。此外还包含 AI 绘画环境配置与练手项目,适合零基础转行或进阶学习者参考,旨在提供结构清晰、逻辑严密的自学路径。