
编程语言AI算法
AI 系统视角下的大模型发展与技术挑战
探讨了大模型的发展历程、架构演变及其对 AI 系统的深远影响。文章详细区分了 AI System 与 AI Infra 的概念边界,分析了从萌芽期到爆发期的技术特征。重点阐述了在千亿参数规模下,分布式并行、算子优化及硬件协同成为制约模型发展的关键因素。同时指出未来算法设计需兼顾工程效率,AI 系统已成为决定大模型成败的核心力量。
发布于 2025/2/626 浏览0 点赞
博客作者
专注微服务架构
323
已发布文章
16K
博客获赞
750K
博客浏览
第 16 页
探讨了大模型的发展历程、架构演变及其对 AI 系统的深远影响。文章详细区分了 AI System 与 AI Infra 的概念边界,分析了从萌芽期到爆发期的技术特征。重点阐述了在千亿参数规模下,分布式并行、算子优化及硬件协同成为制约模型发展的关键因素。同时指出未来算法设计需兼顾工程效率,AI 系统已成为决定大模型成败的核心力量。

阿里巴巴、字节跳动、百度、腾讯、拼多多等国内顶尖互联网大厂的产品经理面试真题与参考回答思路。内容涵盖项目经验、专业技能、行业认知、创新思维、职业规划等多个维度,并提供了具体的应对策略与建议。通过深入分析用户调研、竞品分析、数据驱动决策等核心能力要求,帮助求职者系统准备面试,提升通关概率。

在个人工作站上部署 Teamcenter 与 DeepSeek-R1 模型构建本地企业知识库的方案。通过结合 RAG 框架与向量数据库 OpenSearch,实现了产品设计文档的智能问答。方案涵盖硬件选型、软件环境配置、微服务架构搭建及测试验证流程,确保数据本地化安全与推理效率。该实践展示了工业软件与大模型融合的路径,有助于提升企业研发效率与生产力。
探讨了 Python 在办公自动化、数据分析及网络爬虫领域的应用,通过具体代码示例展示了如何使用 Pandas 处理 Excel 数据、Matplotlib 进行可视化以及 Requests 抓取网页信息,帮助职场人士提升效率并增强竞争力。

介绍如何使用 Python 的 requests 库和正则表达式解析百度文库页面,提取文档标题、页码信息及文本内容,并将结果保存为 doc 文件。同时提供图片数据的提取与下载方法,包含请求头设置、参数解析及去重处理等关键步骤。代码涵盖环境准备、核心类设计、详细实现及运行说明,强调合法合规使用及反爬注意事项。

WSGI 是 Python Web 应用与服务器间的接口规范,uWSGI 是支持多语言的应用容器服务器,uwsgi 是其内部二进制通信协议。详细阐述了三者概念区别,涵盖安装配置、Nginx 反向代理、负载均衡及 Socket 类型选择。通过 Flask 示例演示完整部署流程,解析 uwsgi.ini 参数含义,对比 HTTP 与 TCP 模式差异,并提供常见…

无问芯穹开源的端侧全模态大模型 Megrez-3B-Omni 的实测结果与部署方案。模型具备文本、图像、语音三模态理解能力,在端侧部署中具有低资源消耗优势。实测显示其在逻辑推理、信息抽取方面表现良好,但在复杂数学计算和 OCR 精度上仍有优化空间。文章还深入解析了配套的 Web-Search 项目,包括 RAG 架构设计、Prompt 模板及基于 vLLM…
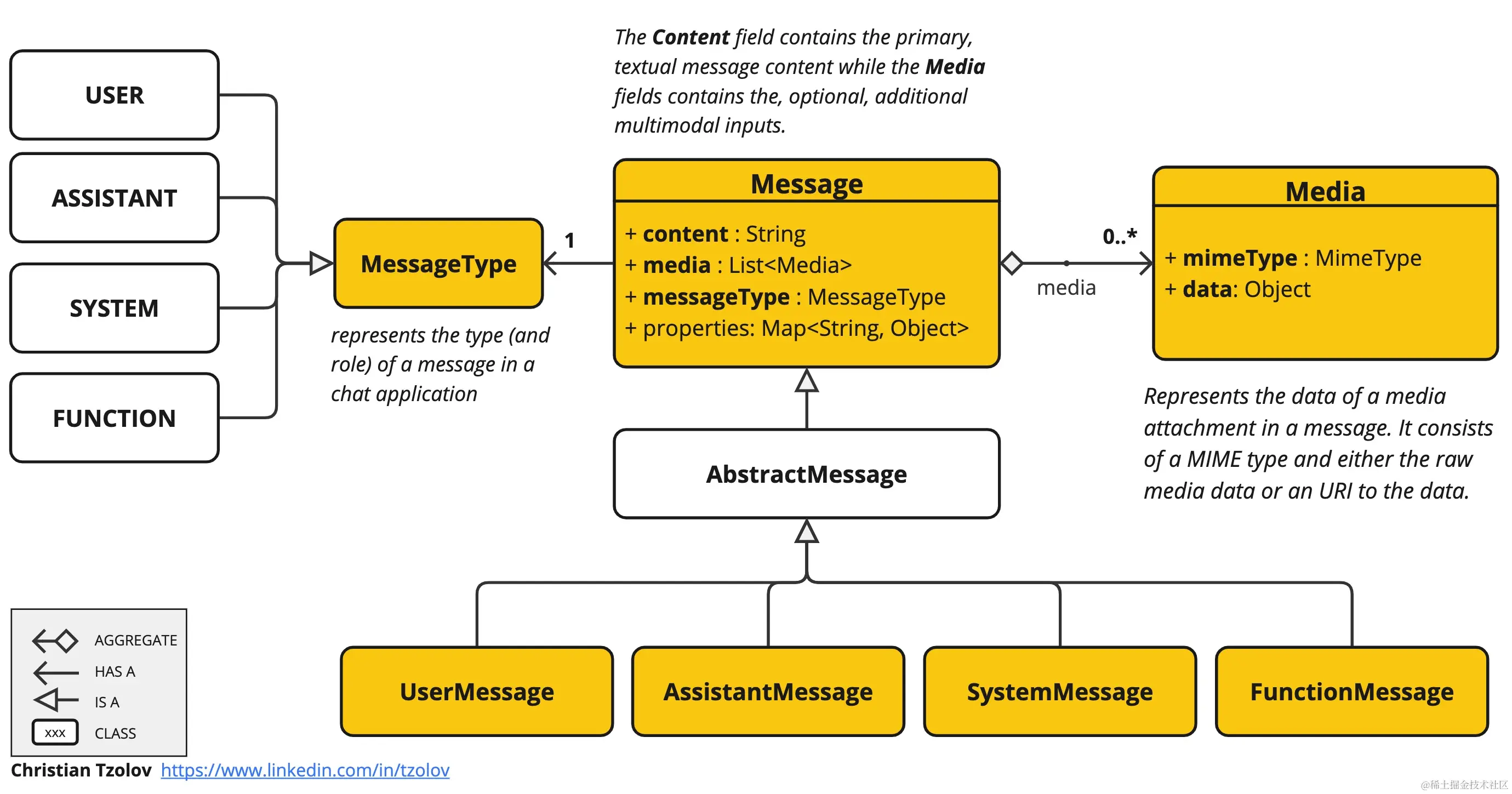
如何利用 Spring AI 框架集成本地 Ollama 服务,实现多模态大模型应用。内容涵盖多模态概念解析、Spring AI 消息抽象机制、Ollama 本地环境搭建、Maven 依赖配置及 Spring Boot 代码实战。通过具体示例展示了如何构建包含图片和文本的用户消息,并调用 LLaVA:7b 模型进行图像描述。文章还提供了常见问题排查、性能优化…

检索增强生成(RAG)技术的概念、发展及工作原理,重点阐述了如何利用 Ollama 和 AnythingLLM 搭建本地私有化知识库。内容涵盖 Docker 环境配置、Ollama 模型安装、AnythingLLM 部署流程、数据导入方法及效果验证。文章还提供了常见问题排查与优化建议,帮助用户在保障数据安全的前提下,利用大模型能力处理私有数据,解决知识局限性…

探讨了 AI 大模型对创业者和职场人的影响及应用策略。内容涵盖大模型在解决问题、商业机会、职业发展方面的价值;针对自媒体创业者、中级职场人及资深从业者的具体应用场景;大模型的选择标准与评估方法;以及构建智能问答系统的实战案例。文章强调提示词工程的重要性,并提供了从基础理论到垂直领域实践的系统学习路径,旨在帮助读者高效利用 AI 技术提升竞争力。

网络安全基础中的主机信息获取与端口扫描技术。内容涵盖准备工作、系统环境选择、常用网络工具的使用、常见端口识别、漏洞原理简析以及防御建议。强调合法合规操作的重要性,旨在帮助读者建立正确的安全认知,掌握基本的网络侦察与防护技能,而非用于非法入侵。

提供了一份从零开始的网络安全自学路线图,涵盖 Web 安全概念、渗透工具使用、实战操作、操作系统基础、服务器加固、脚本编程及源码审计等八大模块。重点推荐 Python 作为主要编程语言,并提供代码示例。文章强调合法合规的重要性,建议在隔离环境中练习,旨在帮助初学者建立系统化的安全知识体系,从基础命令到高级攻防技术逐步进阶。

通过六个实际场景问题,包括天气查询、房产政策、法律问答及 Java 代码生成(部门树构建、数据处理、多线程下载),对 KIMI、文心一言和通义千问三款国产大模型进行了横向对比。测试结果显示,各模型在不同任务上表现各异:文心一言在实时信息获取和逻辑条理性上表现较好;KIMI 依赖搜索引擎,部分数据存在滞后或错误;通义千问在代码生成简洁性和执行稳定性上具有一定优…

介绍网络安全 SRC 漏洞挖掘的合法途径、常用工具及学习路径。涵盖信息收集、常见漏洞原理(如 SQL 注入、XSS)、渗透测试流程及法律法规合规性要求。适合零基础转行人员参考,强调授权测试的重要性与技术积累。

总结了 AI 产品经理转型需知的 9 个核心问题,涵盖产业机遇、技术理解、需求边界、评价体系、长尾现象、B 端与 G 端差异、企业转型路线及 AI 中台算力规划。文章强调懂技术并非为了写代码,而是辅助决策和界定产品范围。通过交通违章、抽烟识别等案例说明需求拆解的重要性,并详细介绍了图像分割、精度评价指标及算力管理的四个维度。旨在帮助从业者建立系统的 AI 产…

探讨了企业级大模型相较于通用和行业大模型的优势,强调知识库是构建企业级大模型的核心。文章详细阐述了构建企业级大模型的四个关键环节:多模态数据存储、高质量语料加工、大模型开发工具链(含微调与 RAG 技术)以及应用开发平台。同时,重点分析了安全合规、灵活部署模式及产业链知识共享的重要性,指出企业级大模型将通过整合内外部数据,成为推动企业数智化升级和新质生产力发…
手机 App 防沉迷系统旨在合理规划每日应用使用时间。核心逻辑包括设定 24 小时允许时段、单时段独占机制及优先级冲突处理。当高优先级时段与低优先级冲突时自动注销后者;同优先级下后添加者无效。该方案通过时间片管理与优先级调度解决过度使用问题。

阿里 P7 职级通常对应年薪 80 万至百万区间,核心区别在于从 P6 的单兵执行转向 P7 的项目统筹与技术攻坚。P6 侧重独立模块开发与质量保障,而 P7 需具备全局视野,能拆分复杂项目、协调人员并把控技术风险,担任技术 Owner。晋升关键在于从单纯完成任务转变为对结果负责及具备行业深度的技术见解。
955 工作制指每日早九晚五、每周工作五天,相较于 996 更强调工作与生活的平衡。部分外企及互联网公司的 955 白名单,涵盖北京、上海、深圳等多地部门。需注意名单基于特定地区反馈,不同部门实际情况可能存在差异,部分公司虽整体水平较好但仍偶有加班。该列表旨在为求职者提供参考,数据源自社区公开项目。

David Beazley 开源的 Python 教程涵盖 9 个章节及 130 个实战示例,内容从基础数据结构到高级技巧如装饰器、生成器,再到测试与发布流程。适合希望快速掌握 Python 核心概念及工程化实践的开发者,周末即可系统学习完毕。