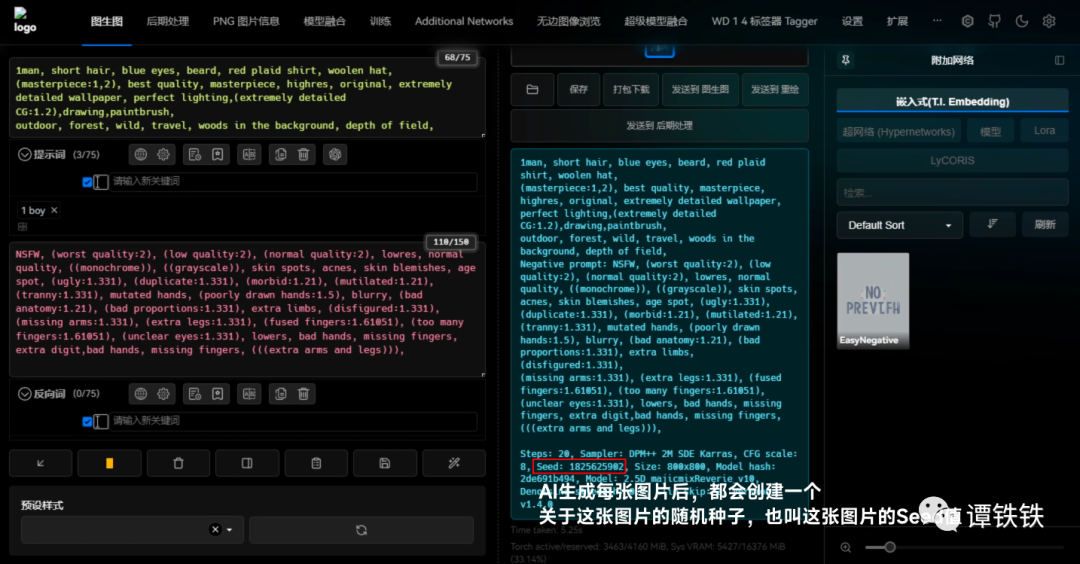
Stable Diffusion 图生图功能详解与参数优化指南
本文主要涵盖以下核心内容:
- 图生图原理深度解析
- 图生图操作流程详解
- 随机种子 Seed 的应用策略
- 图生图典型应用场景
- 高级参数设置与常见问题处理
在之前的教程中,我们讲解了 Prompt 提示词原理,并尝试使用「文生图」结合 Prompt 生成了一些作品。今天开始深入讲解 Stable Diffusion (SD) 的「图生图」功能。
1. 图生图原理深度解析
我们前面介绍过「文生图」,其最大的特点是「随机性」。对图片的操作几乎没有可控性一说,它画出来的图片可能根本不符合我们的需求。

在 Midjourney 中叫「垫图」,而在 Stable Diffusion 中我们叫「图生图」,其实是差不多的意思。
1.1 为什么需要图生图?
在我们的现实生活里,这种对需求的偏差与错误理解还是很普遍存在的。假如你是客户,负责产生设计需求,而设计师负责实现需求。你除了不断用文字和语言描述你的需求,还有什么方法让设计师秒懂你需求想法呢?
你是不是通常会找一张类似风格的图片,说:跟这张图差不多的风格,你帮我模仿着这张图来。

那么在 AI 的世界里,同样也存在这样的情况。「文生图」就好像你对着一个 AI 设计师不断的用语言沟通,AI 对你的需求理解是存在偏差的。
「图生图」就好像,你找好了一个模板给 AI 设计师,说:给我按照这个风格来。那么 AI 设计师就会从图片上获得更多信息,原本的图片上记录的像素信息会在这个「加噪」和「去噪」的过程中被作为一种特征反应在作品上,最后越来越接近你的需求。
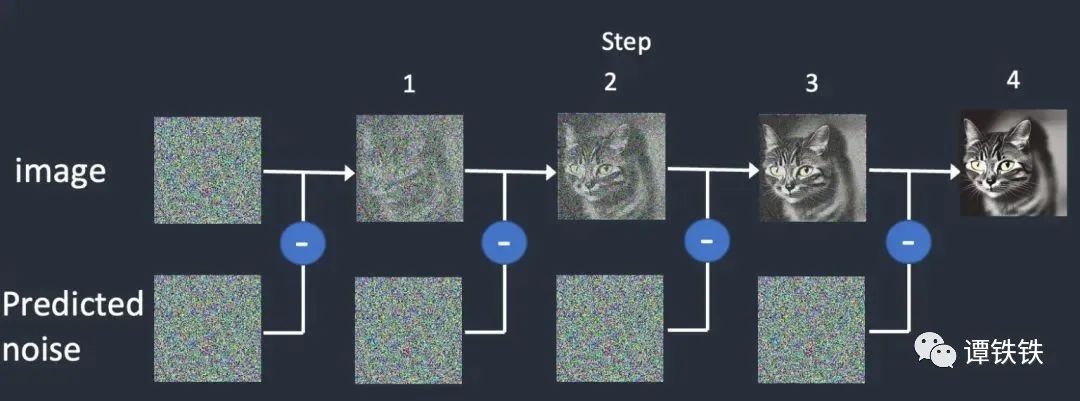
简单来说的话,「图生图」可以帮助你把一张图片画成另一种模样。借助 AI 里面的「图生图」,你可以将真实世界里的人物变成二次元世界的人物,你也可以将动漫角色人物变成真实人物面孔。
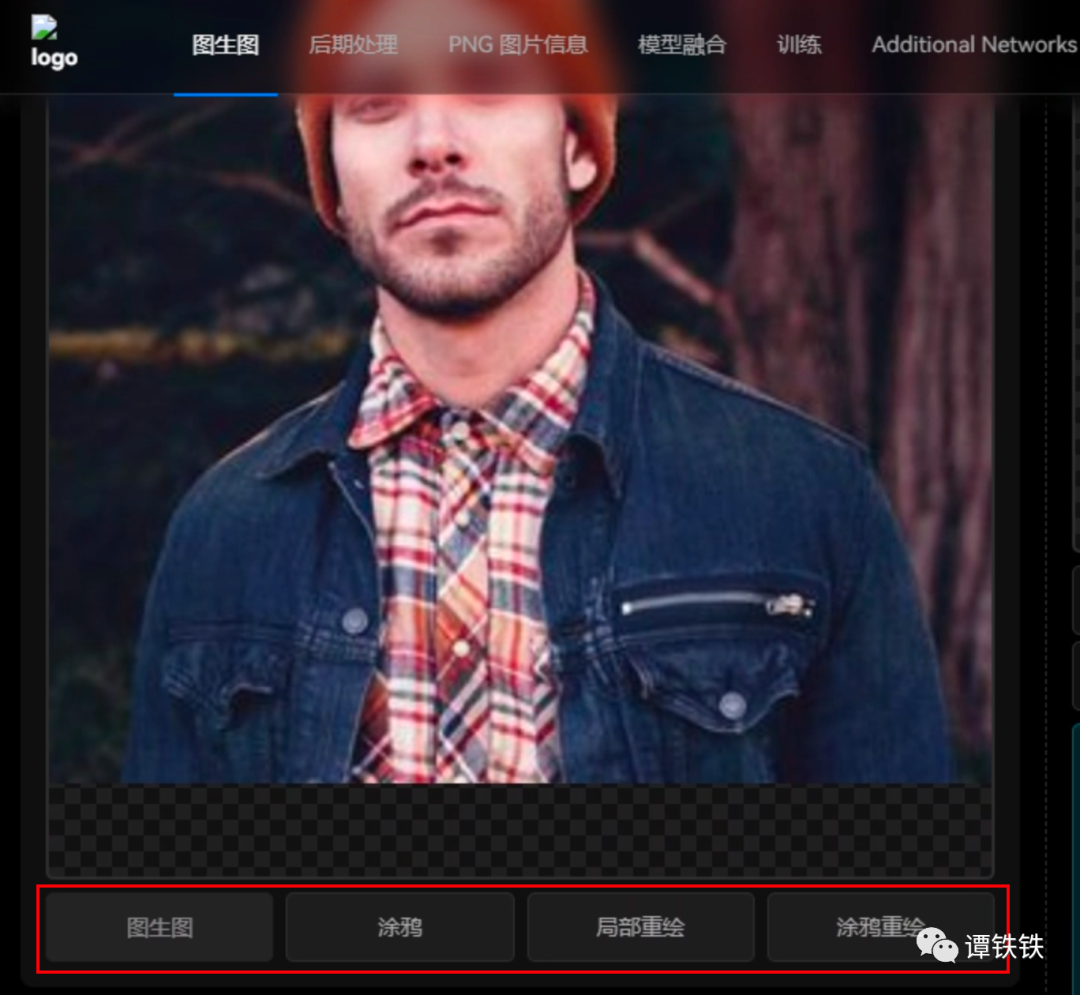
2. 图生图操作流程详解
在 SD WebUI 里面进行「图生图」主要分为三步:导入图片、书写提示词、调整参数。
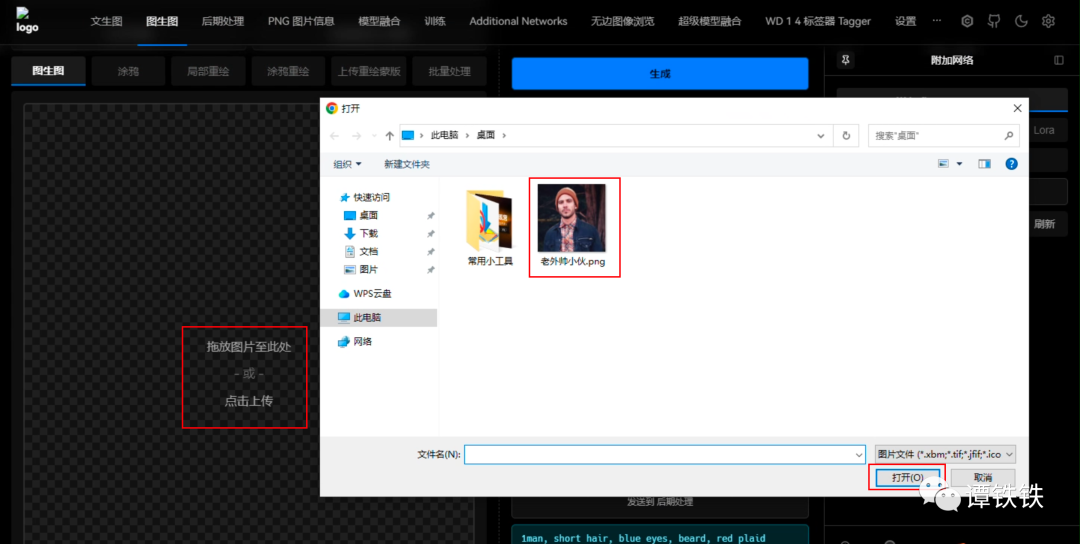
2.1 第一步:导入图片
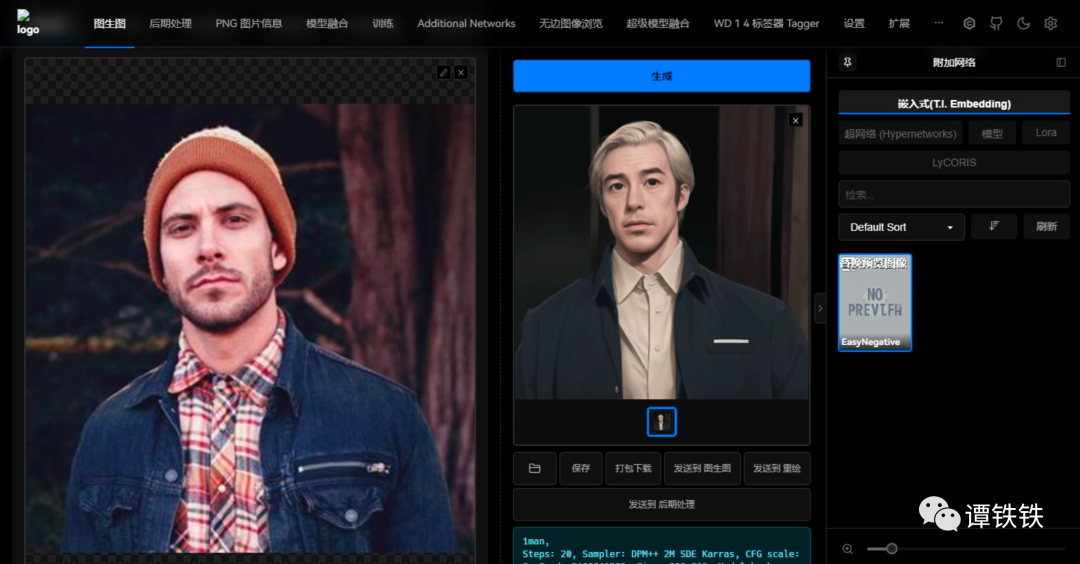
打开 SD WebUI 找到「图生图」的操作界面,基本功能和「文生图」差不多,但在中间多了一个「上传图片」的流程。
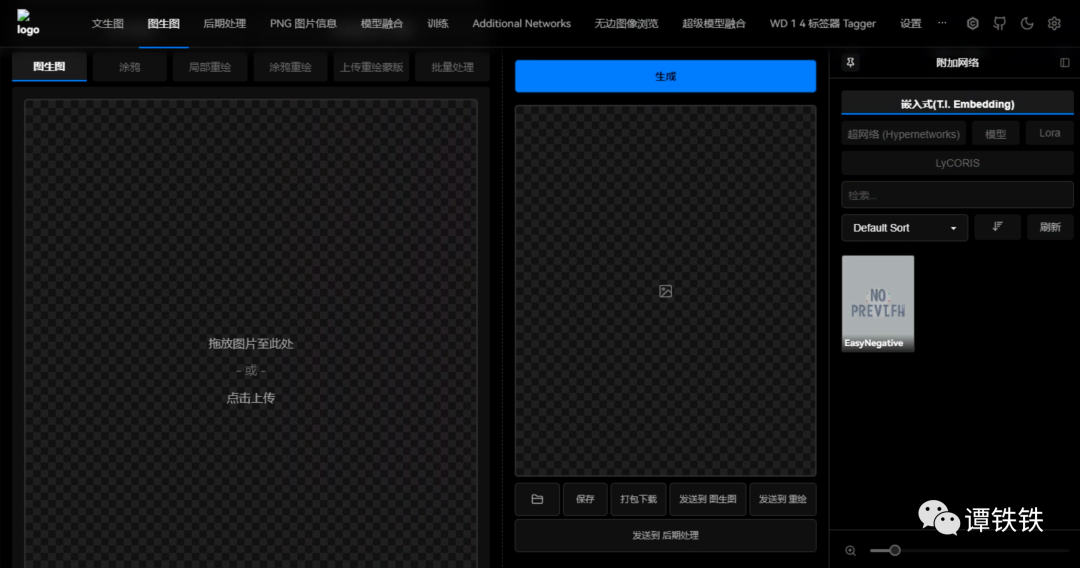
这个位置也是我们上传本地图片到 SD 中的主要环节。将我们准备好的图片上传上去。