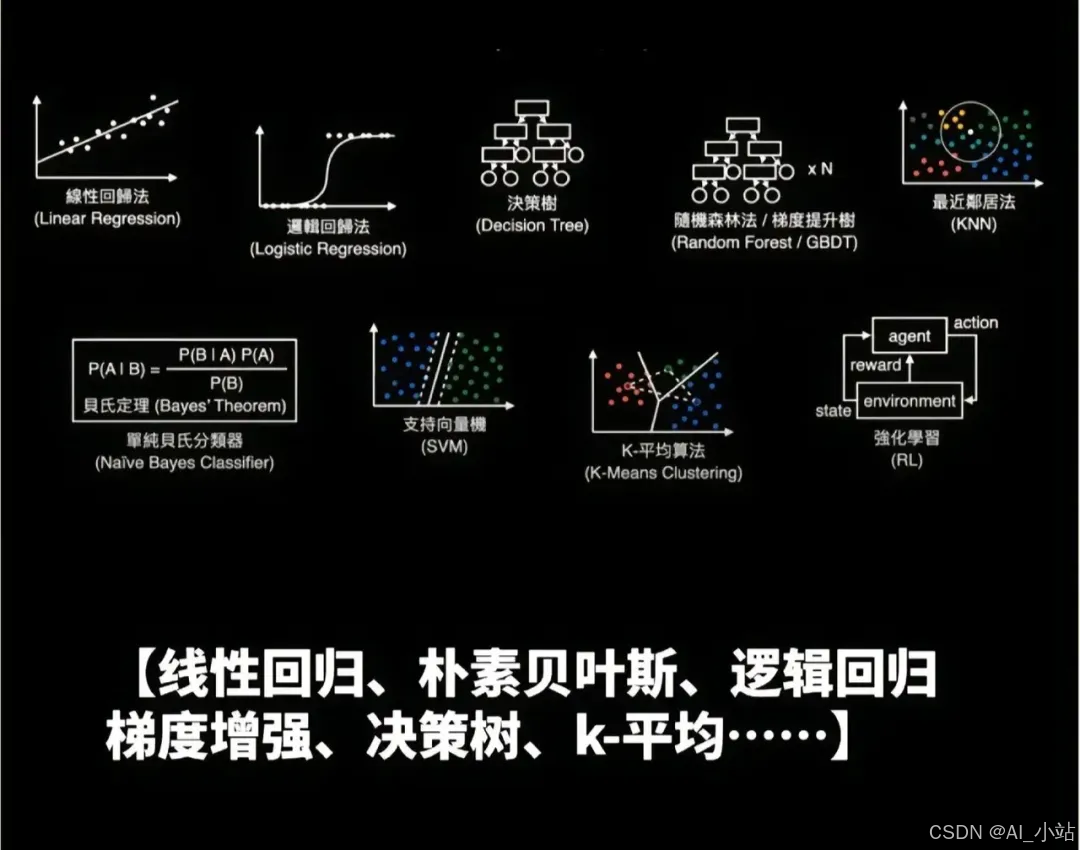
机器学习九大核心算法详解与原理分析
引言
机器学习是人工智能的核心基石,而算法则是构建、训练和应用这些模型的基础。理解经典机器学习算法不仅有助于掌握 AI 大模型的底层逻辑,还能在实际业务场景中快速定位问题并选择合适的解决方案。本文将详细解析九种核心的机器学习算法,涵盖从基础回归到集成学习及神经网络的广泛领域。
1. 线性回归 (Linear Regression)
线性回归是最基础且易于理解的监督学习算法之一。它假设输入变量(特征)与输出变量(目标)之间存在线性关系。
原理
模型试图找到一条直线(或超平面),使得预测值与真实值之间的误差平方和最小。数学表达式通常为: $$ y = w_0 + w_1x_1 + w_2x_2 + ... + w_nx_n $$ 其中 $w$ 为权重系数,$x$ 为特征,$y$ 为预测值。
优缺点
- 优点:简单高效,可解释性强,计算成本低。
- 缺点:对异常值敏感,无法处理非线性关系,假设残差服从正态分布。
应用场景
房价预测、销售额预估等连续数值预测任务。
2. 逻辑回归 (Logistic Regression)
尽管名称中包含'回归',逻辑回归实际上是一种分类算法,广泛用于二分类问题。
原理
通过引入 Sigmoid 函数将线性回归的输出映射到 (0, 1) 区间,表示样本属于某一类的概率。 $$ P(y=1|x) = \frac{1}{1 + e^{-(w^Tx + b)}} $$
优缺点
- 优点:输出概率值,便于阈值调整;模型简单,训练速度快。
- 缺点:容易欠拟合,难以捕捉复杂的非线性特征交互。
应用场景
点击率预测、垃圾邮件检测、疾病风险分类。
3. K 近邻算法 (K-Nearest Neighbors, KNN)
KNN 是一种基于实例的学习方法,属于惰性学习(Lazy Learning)。
原理
对于一个新的样本,在训练集中寻找距离最近的 K 个邻居,根据这 K 个邻居的类别进行投票(分类)或取平均(回归)来决定新样本的类别。
优缺点
- 优点:无需训练过程,原理直观,适合多分类。
- 缺点:计算量大(需计算所有距离),对高维数据效果差(维度灾难),对噪声敏感。
应用场景
推荐系统、图像识别中的简单匹配。
4. 朴素贝叶斯 (Naive Bayes)
这是一种基于贝叶斯定理的概率分类算法,假设特征之间相互独立。
原理
利用先验概率和条件概率计算后验概率: $$ P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)} $$ 由于分母对所有类别相同,只需最大化分子即可。
优缺点
- 优点:对小规模数据表现良好,训练速度快,对缺失数据不敏感。
- 缺点:特征独立性假设在现实中往往不成立,可能影响精度。
应用场景
文本分类(如情感分析)、垃圾邮件过滤。
5. 支持向量机 (Support Vector Machine, SVM)
SVM 是一种基于间隔最大化的分类算法,旨在找到一个最优超平面。
原理
通过核技巧(Kernel Trick)将低维空间的数据映射到高维空间,使其线性可分。目标是最大化决策边界(超平面)与最近样本点(支持向量)之间的距离。
