一、前言
知识库问答系统是一种应用广泛的解决方案,可以在企业文档管理、智能客服、技术支持等多个领域发挥重要作用。以往的系统通常基于固定规则匹配、传统相似度检索或者 Seq2Seq 模型构建。这类系统的开发成本较高,修改逻辑较为麻烦,尤其在数据准备阶段需要耗费大量精力进行标注和清洗。
随着大语言模型(LLM)技术的突破,这一局面得到了根本性改变。在 LLM 的加持下,无论是系统架构的编写还是数据的预处理工作,工作量都大大减少。开发者可以使用较少的代码实现非常智能的知识库问答系统,显著降低了技术门槛。
本文将详细介绍如何使用开源大语言模型,完全离线部署一套本地知识库问答系统,确保数据隐私安全的同时实现智能化交互。
二、前置知识
2.1 大语言模型基础
语言模型是自然语言处理领域中一个非常重要的概念,其核心任务是评估一串有序字符构成句子的概率。比较经典的模型包括 BERT 系列、GPT 系列等。而现在业界常说的大语言模型更多是指以 GPT 为代表的生成式预训练 Transformer 模型。
以往的 GPT 模型训练方式相对简单,主要是根据一个句子的前 n 个词,预测第 n+1 个词。这种看似简单的'文字接龙'方式,却赋予了 GPT 模型极大的泛化能力和自由度,使其能够理解上下文语义并生成连贯文本。
2.2 Prompt 工程
Prompt 工程是通过设计输入指令来引导模型输出特定结果的技术。例如我们可以直接把 GPT 应用在情感分析任务上,只需要设置一下输入的前缀:
这部电影真烂的情绪是
然后 GPT 就可以预测下一个词以及后续内容,最后得到结果'消极'。或者我们可以采用少样本学习的方式:
这部电影真烂,消极
太好看了,
然后 GPT 就可以预测出'积极'。输入的内容还可以更长,通过提供多个示例让模型学习模式:
这部电影真烂,消极
xxxx,积极
xxxx,消极
太好看了,
上面这种通过改变输入内容让 GPT 输出特定结果的方式就叫做 Prompt 工程。通过精心修改 Prompt,我们可以让 GPT 完成更复杂的工作,比如多轮对话、翻译、代码生成等。下面以翻译为例,我们只需要输入 Prompt:
中文:不要温顺的走进那个良夜
英文:
这样就可以让 GPT 输出对应的英文句子。
2.3 模板与占位符
在实际使用中,输入的 Prompt 往往包含部分内容是动态变化的,这部分可以用一些占位符来预留位置。例如:
这部电影真烂,消极
{sentence},
我们只需要输入具体的句子 s,然后用字符串替换的方式将 prompt 中的 {sentence} 替换掉,就得到了最终输入给 GPT 的完整 Prompt。上面这种带有占位符的 Prompt 结构被称为模板,它极大地提高了 Prompt 的可复用性。
2.4 RLHF 技术
早期的 GPT 模型主要采用无监督学习,即前面描述的根据前 n 个词预测下一个词。而现在主流的类 Chat 模型都是使用无监督预训练 + RLHF(基于人类反馈的强化学习)的方式。
首先无监督学习部分和早期 GPT 是一样的,做文字接龙或者类似句子接龙等任务,建立基础的语料理解能力。而 RLHF 则是在此基础上,引入人类反馈机制,在这个过程中会有人类老师帮助 GPT 纠正输出,让 GPT 的输出更符合人类的对话习惯和价值取向。也正是 RLHF 造就了 ChatGPT 这样优秀的对话模型。
三、实现原理
3.1 基于检索的传统问答
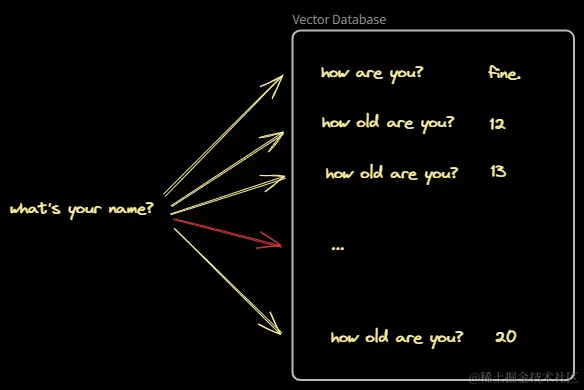
在 BERT 时代,还有一种基于向量相似度的问答系统。这种系统架构非常简单,但是前期数据的收集和处理需要花费较多的时间。这种系统与本文要讨论的系统有许多相似的地方。
首先我们需要收集大量的标准问答对,例如:
江西是省会是哪?南昌
北京是南方还是北方?北方
...?xx
收集完成后,使用 BERT 等模型提取问题的特征向量,然后存储到向量数据库中。在用户提问时,提取问题的特征向量,并在数据库中检索出最相似的问题,返回对应的答案。

3.2 基于大语言模型的知识库问答
基于检索的传统问答系统有几个明显的问题:因为数据必须严格符合问答对的形式,因此数据收集需要消耗大量时间整理;另外回答的内容是固定的,因此输入同一个问题,会得到相同的结果。在某些系统中,这是个优点,但是如果是客服系统或咨询系统,过于机械的回答体验较差。

