斯坦福李飞飞团队发布新多模态模型:统一动作与语言理解
人类的沟通交流充满了多模态的信息。为了与他人进行有效沟通,我们既使用言语语言,也使用身体语言,比如手势、面部表情、身体姿势和情绪表达。因此,为了理解和生成人类动作,理解这些多模态的行为至关重要,而且这一研究方向最近受到的关注也越来越多。
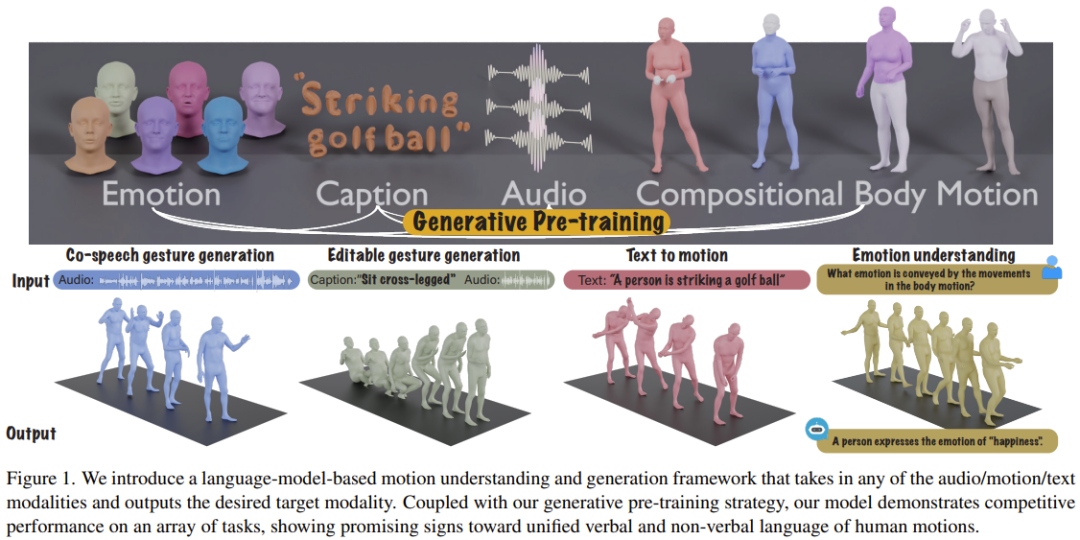
多模态语言模型看起来颇具潜力,可将多种模态的不同任务统一在一个框架下。近日,斯坦福大学李飞飞、Gordon Wetzstein 和 Ehsan Adeli 领导的一个团队在这方面做出了贡献,探索了语音 - 文本 - 动作生成任务。他们提出了一个全新的多模态语言模型,可以实现富有表现力的动作生成和理解。
模型核心能力
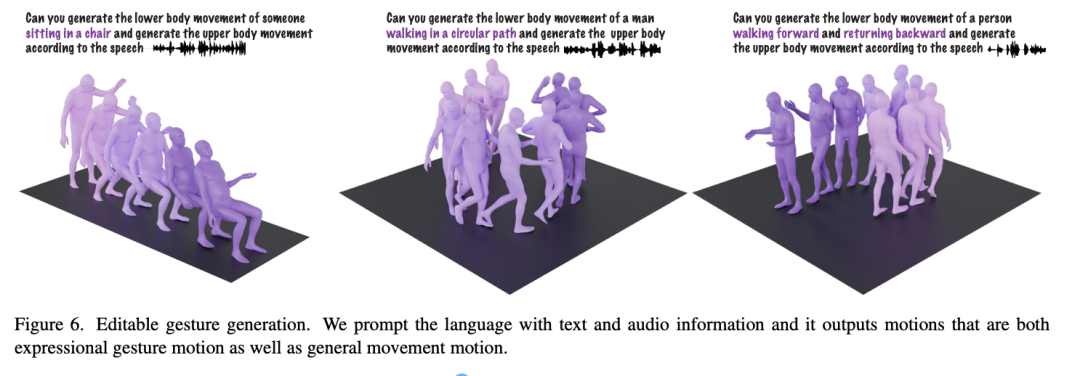
这个模型可以同时接受音频和文本输入来生成动作。例如,指定下半身的动作是绕圈走,并根据语音生成上半身动作,它就会配合生成对应的动作。更重要的是,它支持动作编辑,可以将原本的绕圈走动更换为其他动作序列(如后退、跳跃、前跑、后跑等)。更换了动作指令,模型生成的动作依然自然流畅,并与语音内容保持良好的协调性。
这项研究对于李飞飞的长远「空间智能」目标大有裨益。论文标题为《The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion》。

论文概览
首先,该团队指出,为了统一人类动作的言语和非言语语言,语言模型是至关重要的。他们给出了三点原因:
- 语言模型能自然地与其它模态连接起来;
- 语音富含语义,而「建模因笑话而发出的笑声」这样的任务需要强大的语义推理能力;
- 经过大量预训练之后,语言模型能够具备强大的语义理解能力。
基于这样的理解,该团队打造出了一种全新的多模态语言模型。
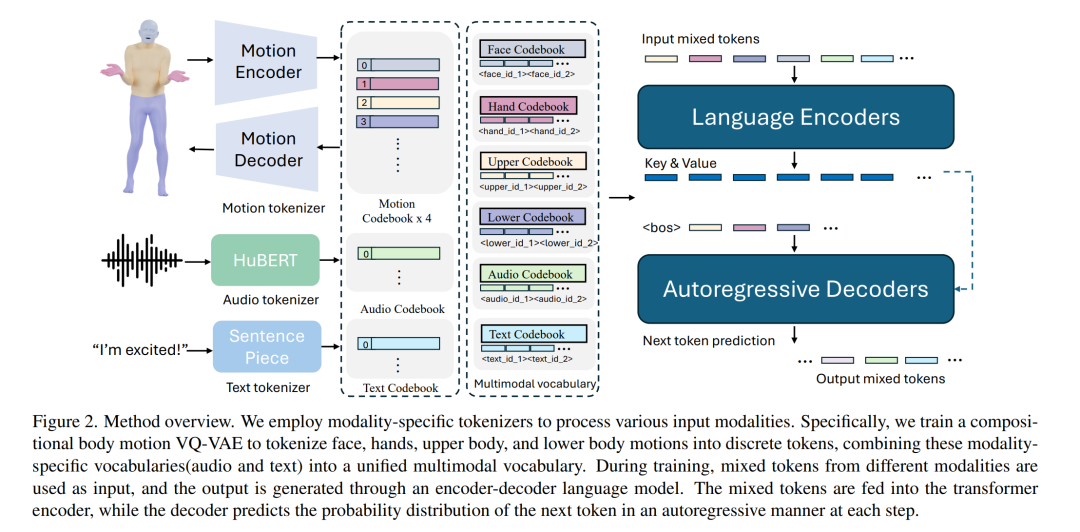
动作 Token 化
为了使用语言模型来建模动作,首先自然要想办法将动作变成 token。该团队的做法是针对不同的身体部位(脸、手、上身、下身)来实现动作的 token 化。事实上,之前已有研究表明,这种划分策略在建模人脸表情方面确实很有效。
之后,再搭配上现成可用的文本和语音 token 化策略,就可以将任何模态的输入都表示成 token 了。
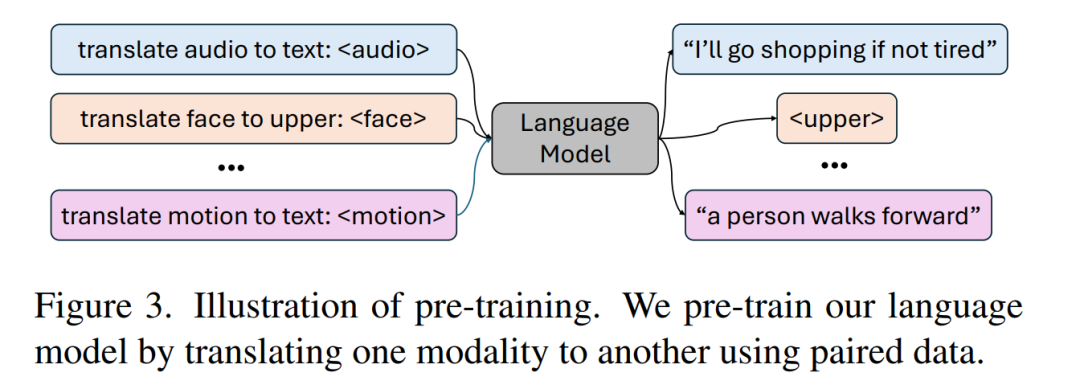
两阶段训练流程
为了训练这个使用多种模态的 token 的语言模型,该团队设计了一个两阶段式训练流程:
- 预训练:目标是通过身体组合动作对齐与音频 - 文本对齐来对齐各种不同的模态。
- 指令微调:预训练完成后,将下游任务编译成指令,并根据这些指令训练模型,使模型能够遵循各种任务指令。
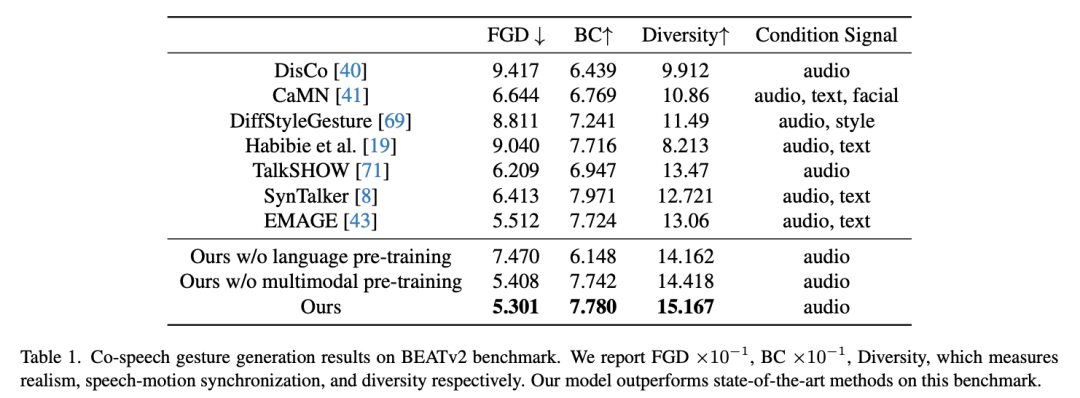
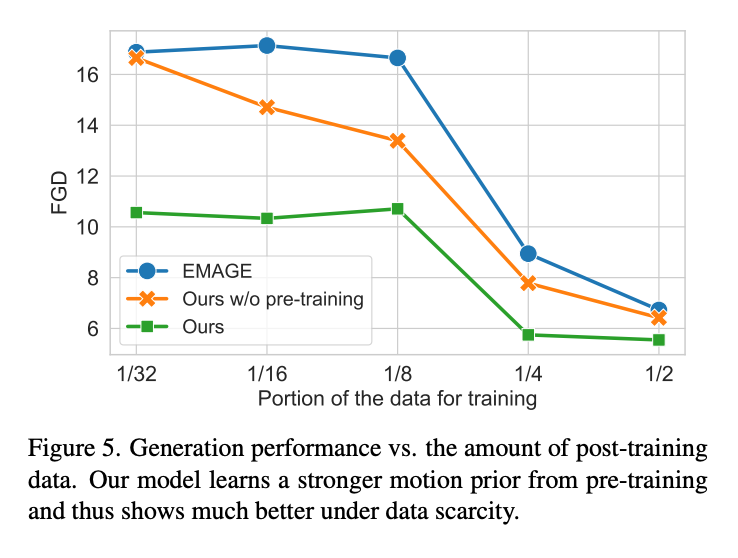
该团队自然也进行了实验验证,结果发现新方法得到的多模态语言模型确实比其它 SOTA 模型更优。不仅如此,他们还发现,在严重缺乏数据的情况下,这种预训练策略的优势更为明显。
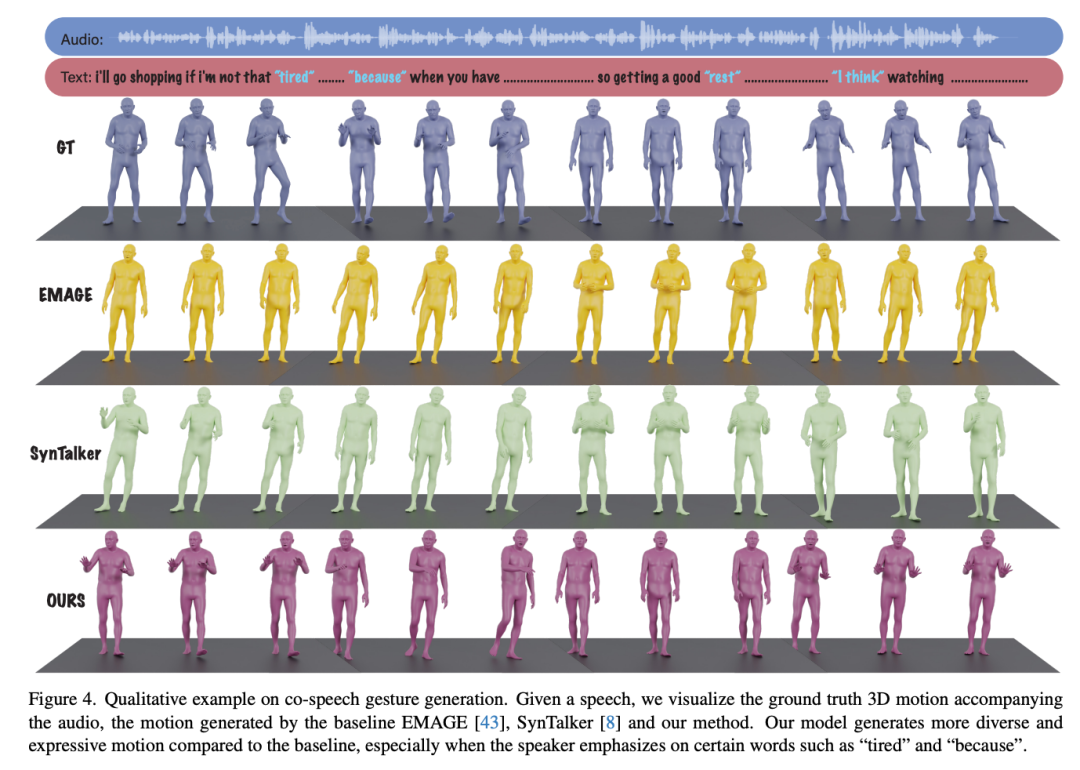
与其他伴语手势生成模型的效果对比 与其他文生动作模型的效果对比
尽管该模型在预训练期间从未见过语音 - 动作数据,但在用于数据相对较少的全新说话人时,它依然达到了颇具竞争力的性能,表现出了显著的泛化能力。
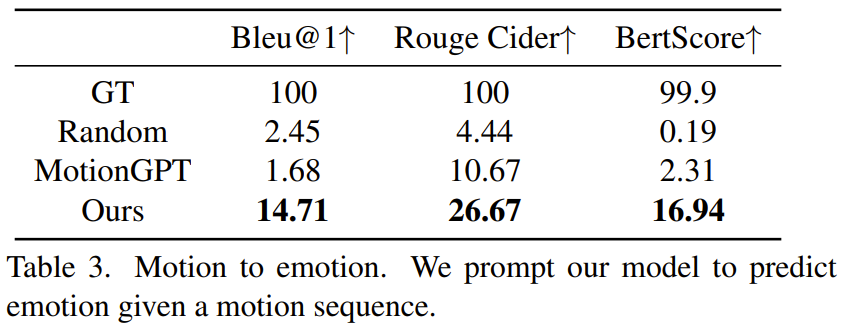
该团队表示:「就我们所知,这是首个构建多模态语言模型来统一 3D 人体动作的言语和非语言语言的工作。」
技术细节详解
用于动作生成和理解的多模态语言模型
模型的整体结构如下图 2 所示。