概述
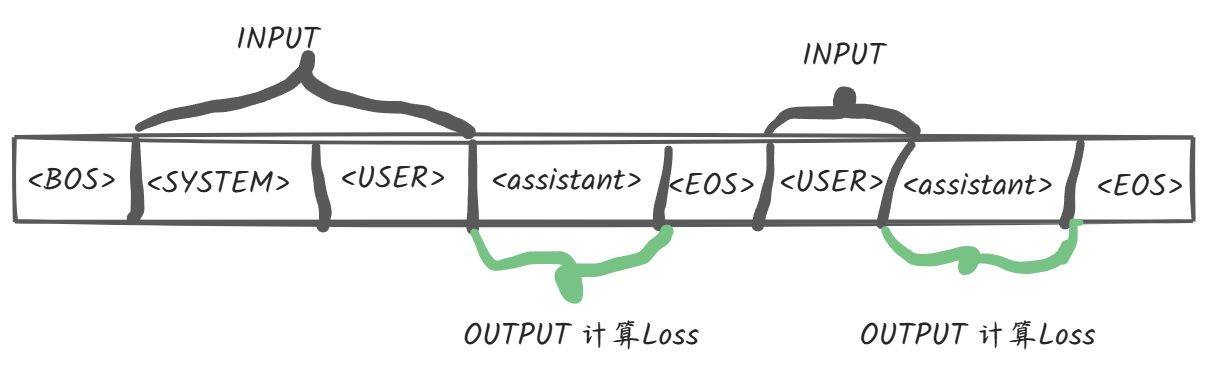
在大型语言模型(LLM)的微调实践中,大多数开发者关注的是如何调用 API 或配置训练脚本,而对于底层 Loss 计算的具体逻辑往往缺乏深入了解。Loss 计算的准确性直接决定了模型能否正确收敛以及生成质量的高低。本文重点剖析 GLM-4-9B 开源模型在微调时的 Loss 计算机制,特别是多轮对话场景下的 Mask 策略与标签处理逻辑。
数据格式规范
GLM-4 系列模型采用标准的 ChatML 风格进行对话交互。在微调数据集中,每条样本通常包含一个 messages 列表,其中每个元素代表一次交互的角色和内容。支持的角色包括 system(系统提示)、user(用户提问)、assistant(助手回复)以及 observation(工具调用观察结果)。
标准的数据结构示例如下:
[
{
"messages": [
{
"role": "system",
"content": "你是一个有用的助手。"
},
{
"role": "user",
"content": "你好,请介绍一下大模型。"
},
{
"role": "assistant",
"content": "大模型是指参数量巨大的深度学习模型..."
}
]
}
]
在实际训练中,这些文本会被 Tokenizer 转换为整数 ID 序列,以便模型进行概率预测。
Loss 计算核心逻辑
在 PyTorch 等深度学习框架中,CrossEntropyLoss 默认会将 ignore_index 设为 -100。这意味着在计算 Loss 时,所有标签为 -100 的位置不会参与梯度更新。GLM-4 的 Loss 计算正是基于这一机制,通过构建特定的 Label Mask 来决定哪些 Token 需要被预测。
