
PythonAI算法
LLaMA-Factory 快速开发自定义大模型实战指南
基于 LLaMA-Factory 框架进行大模型微调的全流程,涵盖环境搭建、数据集构建、LoRA 指令微调、推理测试、效果评估及模型导出部署。通过命令行与 WebUI 两种方式,演示了从原始模型验证到 GGUF 格式转换至 Ollama 部署的完整链路,帮助开发者快速掌握垂直领域大模型的训练与应用。
发布于 2025/2/739 浏览0 点赞
博客作者
用代码写诗意
336
已发布文章
9.6K
博客获赞
620K
博客浏览
第 16 页
基于 LLaMA-Factory 框架进行大模型微调的全流程,涵盖环境搭建、数据集构建、LoRA 指令微调、推理测试、效果评估及模型导出部署。通过命令行与 WebUI 两种方式,演示了从原始模型验证到 GGUF 格式转换至 Ollama 部署的完整链路,帮助开发者快速掌握垂直领域大模型的训练与应用。

使用 OpenLLM 构建和部署大语言模型应用的完整流程。首先分析了 LLM 爆发背景下企业自建模型的高可控性、数据安全性和成本效益需求,以及生产环境部署面临的硬件、扩展性、吞吐量和延迟挑战。接着详细阐述了 OpenLLM 框架的核心功能,包括多模型支持、快速启动、HTTP API 及 Python SDK 调用,重点解析了 Continuous Batch…

RAG(检索增强生成)是大模型应用的主流架构,通过结合搜索与 LLM 生成来提升回答准确性。文章详细解析了 RAG 的基础流程,包括文本分块、向量化及索引构建。重点介绍了高级优化技术,如混合检索、Query 变换、Rerank 重排序、聊天引擎及智能体集成。此外,还探讨了模型微调策略与性能评估框架,为构建高质量 RAG 系统提供了全面的技术指南。

PyTorch 安装涉及显卡驱动、CUDA 版本匹配及 Python 包管理工具选择。详述了如何查看显卡信息、确认 CUDA 兼容性、通过 Pip 或 Conda 安装 PyTorch、验证安装结果以及处理常见驱动版本不匹配错误。内容涵盖硬件检查、版本策略、多平台安装方法、环境验证脚本及故障排查指南,帮助开发者快速搭建稳定的深度学习开发环境。

Llama 3 模型通过蒸馏技术迁移至 Mamba 架构,实现了推理速度提升 1.6 倍且性能不减反增。该项目由 Mamba 架构提出者 Tri Dao 参与,采用三阶段蒸馏流程(伪标签蒸馏、指令微调、人类反馈优化),并结合推测解码算法加速推理。实验显示混合模型在 AlpacaEval、MT-Bench 及 OpenLLM Leaderboard 上表现优异…

详细阐述了检索增强生成(RAG)系统的 12 种核心调优策略,涵盖数据索引与推理两大阶段。索引阶段涉及数据清洗、分块技术、嵌入模型选择、元数据管理、多索引架构及索引算法优化。推理阶段重点讲解查询转换、检索参数调整、高级检索策略、重排序模型应用、语言模型微调及提示工程设计。文章还补充了评估指标与常见陷阱分析,旨在帮助开发者构建高性能、低延迟的 RAG 生产级应…

提示工程是引导 AI 大模型生成高质量输出的关键技术。阐述了提示的定义及其作为人机交互核心单元的作用,区分了提示与提示工程的本质差异。内容涵盖了指令设计、上下文利用、先验知识融合及迭代优化等核心技巧,并通过短视频脚本生成的实例展示了实际应用。此外,补充了零样本、少样本及思维链等常见模式,旨在帮助开发者更有效地利用大模型能力,提升任务执行的准确性与效率。

RAG 大模型在处理知识密集型任务时面临知识冲突问题,严重影响性能与安全性。深度解析三种主要冲突类型:上下文与参数知识冲突、上下文内部冲突及参数化知识内部冲突。文章探讨了各类冲突的起因如时间错位与信息污染,表现如依赖偏差与自我不一致性,并总结了微调、提示工程、知识编辑等解决方案。通过综述现有研究,帮助理解模型在事实准确性上的挑战及未来研究方向。

深入剖析了 LLM 多智能体协作工作流的三种主流框架:ChatDev、MetaGPT 和 AutoGen。文章阐述了多智能体协作通过角色分工、流程解耦和相互校验提升任务效率的原理。ChatDev 模拟虚拟软件公司,采用瀑布模型进行全周期开发;MetaGPT 引入 SOP 和流水线作业,强调工程化标准;AutoGen 提供通用的对话框架,支持人机协同和灵活的任…

详细阐述了 AI 产品经理的定义、职责及其与传统产品经理的区别,指出懂技术是核心门槛。文章将 AI 产品经理分为软件(专业领域型、平台型)和硬件(智能硬件、算力)两大类,并深入分析了必备技能体系,包括算法理解、系统架构认知、SQL 数据分析能力及业务转化 Sense。此外,提供了在校生和传统 PM 转型的具体路径建议,并结合大模型发展趋势,探讨了行业面临的挑…

生成式大模型安全评估白皮书系统梳理了近 20 个主流大模型的发展现状与安全风险,涵盖伦理、技术、内容三大风险类别。报告提出了伦理性、隐私性、事实性、鲁棒性四大评估维度及指标衡量与模型攻击两类评估方法,为学术研究、产业实践和政策制定提供参考。文章详细解析了各风险维度的具体含义及应对策略,强调构建全生命周期安全体系的重要性。

详细解析了人工智能模型评估的核心指标与方法体系。涵盖分类任务中的准确率、精确率、召回率、F1 分数及混淆矩阵,解释其数学定义与实际应用场景。同时介绍回归任务中的平均绝对误差和均方误差,以及 ROC 曲线与 AUC 分数的含义。通过 Python sklearn 代码示例展示各指标的计算方式,帮助开发者根据具体业务需求选择合适的评估标准,全面理解模型性能。

在 Windows 环境下安装 Stable Diffusion 秋叶整合包的完整流程。涵盖硬件配置要求、驱动依赖安装、软件启动及基础绘图操作。详细解析了模型、VAE、LoRA 等核心概念的使用,并提供提示词编写技巧与常见问题排查方法,帮助用户快速上手 AI 绘画。
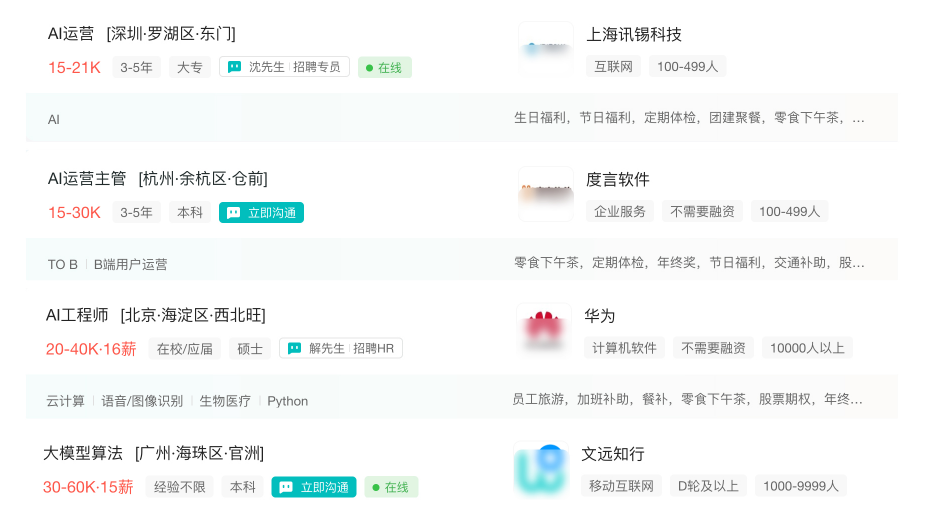
详细阐述了大模型时代的岗位需求与薪资水平,介绍了 NLP、CV、科学计算及多模态四大类主流大模型的特点与应用。核心内容提供了 2024 年大模型学习的七阶段路线图,涵盖系统设计、提示词工程、平台开发、知识库构建、微调技术及多模态实战。针对不同基础人群(零基础、传统开发、AI 研究人员)给出了定制化学习方案,并分析了 Java 及 AI 从业者转型大模型的优势…
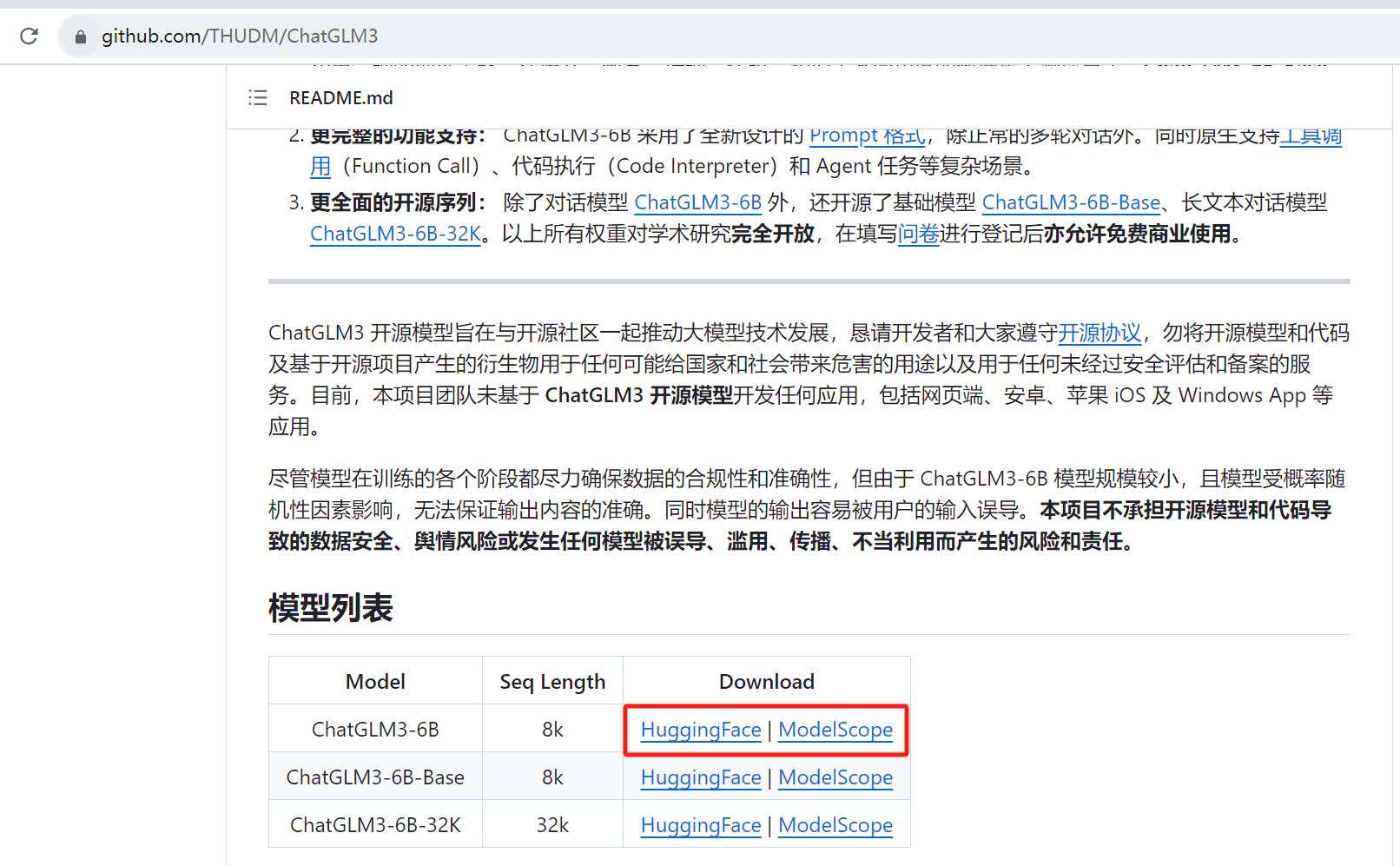
国产大语言模型 ChatGLM3 的本地化部署全流程。涵盖源码获取、Conda 环境配置、PyTorch 依赖安装及 CUDA 版本匹配。重点讲解了显存优化方案,包括 FP16 与 4-bit 量化的区别与应用场景。提供了基于 Gradio 和 Streamlit 的 Web Demo 启动方法,并针对 GPU 识别失败等常见问题给出排查步骤。此外,还阐述了…

深入探讨了 LLM 反思工作流的三种典型技术:Self-Refine、CRITIC 和 Reflexion。Self-Refine 通过单一模型的迭代反馈优化输出;CRITIC 利用外部工具交互验证并修正结果;Reflexion 则引入语言强化学习和长期记忆机制,使 Agent 能从失败中积累经验。文章分析了各方法的原理、架构及在数学、编程等任务上的性能提升…

基于检索增强生成(RAG)的生成式 AI 系统构建方案。文章首先分析了大模型幻觉问题及 RAG 的基本原理,随后重点阐述了 LlamaIndex、Deep Lake 和 Pinecone 等技术栈的选择与应用。内容涵盖数据预处理、分块策略、向量索引构建、检索优化及生成后处理等关键步骤。此外,还探讨了知识图谱驱动、人类反馈强化学习、多模态数据处理等高级特性,并…

2024 年大模型领域的核心开源项目,涵盖应用开发平台、文档解析、数据库交互、本地部署及推理框架等关键方向。内容包含 Dify、FastGPT、RAGFlow、Ollama、LlamaFactory 等知名工具的详细功能介绍与适用场景分析,旨在帮助开发者快速构建基于大语言模型的智能化应用,并提供从数据处理到模型微调的全链路技术选型参考。

大模型(LLM)的入门学习路径,涵盖三大核心角色:基础学习者、科学家和工程师。内容从机器学习数学基础、Python 编程、神经网络及 NLP 入手,深入讲解 Transformer 架构、指令数据集构建、预训练、微调(SFT/LoRA/RLHF)、评估、量化及新趋势。工程师部分重点阐述模型运行、向量存储、RAG 高级应用、推理优化、部署方案及安全性防护。文章…

产品经理岗位常见的 45 道必背面试题及其参考回答。内容涵盖用户调研、竞品分析、需求管理、项目协作、数据分析、商业化策略及职场软技能等多个维度。文章不仅提供了标准化的回答思路,还补充了考察点解析、关键方法论及实战案例,帮助求职者系统化准备面试,提升逻辑思维与表达能力。适合初级至中级产品经理求职者参考学习。