LangChain Agent 智能应用构建指南
LangChain 介绍
随着各种开源大模型的发布,越来越多的人开始尝试接触和使用大模型。在感叹大模型带来的惊人表现的同时,也发现一些问题,比如没法查询到最新的信息,有时候问一些数学问题时候会出现错误答案,还有一些专业领域类问题甚至编造回答等等。有没有什么办法能解决这些问题呢?答案是 LangChain。
LangChain 是一个开源的语言模型集成框架,旨在简化使用大型语言模型(LLM)创建应用程序的过程。利用它可以让开发者使用语言模型来实现各种复杂的任务,例如文本到图像的生成、文档问答、聊天机器人、调用特定的 SaaS 服务等等。随着 ChatGPT、Midjourney 等 AI 技术的爆火,LangChain 在短时间内获得了大量关注,版本迭代异常快,社区十分活跃。
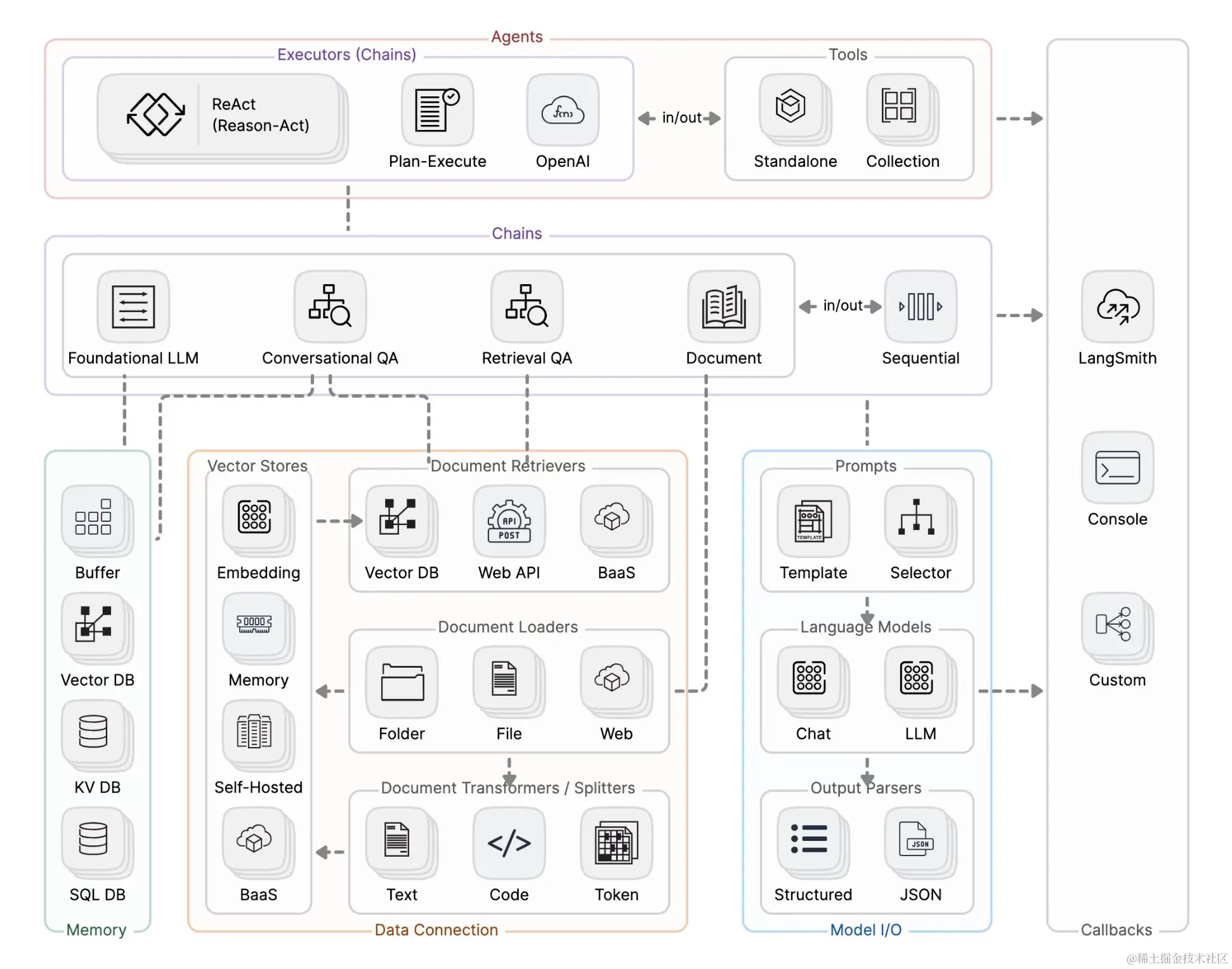
LangChain 的核心架构主要包含如下模块:
- Model I/O:大模型的输入输出,包含提示词(Prompt)、任何大模型接口、结果解析器。
- Retrieval:涉及到数据集相关,主要包含文档提取器、文档转换器、向量数据库等,用于实现 RAG(检索增强生成)。
- Chains:允许将多个不同组件组合在一起使用,形成链条式调用,处理特定工作流。
- Memory:在大模型调用期间提供存储能力,保存对话历史或上下文状态。
- Agents:链式调用是硬编码的,而代理是由大模型根据实时情况来决定如何调用工具,具有更高的灵活性。
- Callbacks:大模型各个阶段的回调系统,对于日志记录、监控、流传输和其他任务非常有用。
Agent 核心原理
大模型一般只拥有他们被训练的知识,这种知识可能很快就会过时了,所以在推理的时候大模型与外界是处于'断开'状态的。为了克服这一限制,LangChain 在 Yao 等人于 2022 年 11 月提出的「推理和行动(ReAct)」框架上提出了'代理 (Agent)'的解决方案。此方案可以获取最新的数据,并将其作为上下文插入到提示中。Agent 也可以用来采取行动(例如,运行代码,修改文件等),然后该行动的结果可以被 LLM 观察到,并被纳入他们关于下一步行动的决定。
运行流程
运行大体流程为:1. 用户给出一个任务 (Prompt) -> 2. 思考 (Thought) -> 3. 行动 (Action) -> 4. 观察 (Observation),然后循环执行上述 2-4 的流程,直到大模型认为找到最终答案为止。
Agent 内部具体拆解逻辑如下:
- Thought: 模型分析当前状态,决定下一步做什么。
- Action: 选择具体的工具并生成参数。
- Observation: 工具执行后返回结果,作为新的上下文输入给模型。
- Final Answer: 当模型认为信息足够时,输出最终结论。
实现步骤详解
使用 Agent 有两个必备条件:相关能力工具和对这些工具的正确描述。工具的命名和描述直接决定了大模型能否准确理解何时调用该工具。
定义工具
工具的定义只需要集成 BaseTool 类,然后在 _run 方法中编写你的逻辑就行,大模型会把合适的参数传进来。需要定义类变量有:
- name: 工具名称,很重要,大模型内部会使用到,需简洁明确。
- description: 工具描述,很重要,告知大模型在什么情况下来使用这个工具,描述越详细效果越好。
- return_direct: 这个字段默认为 false,如果设置为 true,工具返回结果后,大模型就不再循环思考了会直接将这个结果当做答案。
LangChain 已经内置了 duckduckgo 搜索引擎,pip install duckduckgo-search 安装一下依赖包即可使用。下面是我定义的两个工具,一个用于电影搜索,一个用于数学计算:
re
langchain.tools BaseTool, DuckDuckGoSearchRun
():
name =
description =
return_direct =
() -> :
( + query)
search = DuckDuckGoSearchRun()
search.run(query)
():
name =
description =
return_direct =
() -> :
:
(query)
Exception e:
