一、问答系统简介
问答系统(Question Answering System,简称 QA System),其核心是用简要的自然文本回答用户提出的问题。QA 的难度主要在于回答这个问题所依赖的信息在长文档中的分布情况,具体可以大致分为下面三种情况:
- L1:相关信息可以出现在不超过一个固定上下文长度(如 512 tokens)限制的 block 以内。
- L2:相关信息出现在多个 block 里,出现的总数不超过 5-10 个,且最好能在大模型支持的有效长度内。
- L3:需要考虑多个片段,并综合结合上下文信息甚至全部内容才能得到结果。
受限于数据集的大小和规模以及问题的难度,目前主要研究偏向于 L1 和 L2。由于高质量的中文数据集整理会耗费很大的人力、物力,现在 QA 问题的数据集文档长度普遍偏低,而且规模较小,与实际应用相差甚远。当然,借助大模型的能力,能比较好的整合和回答 L1 类问题,L2 类问题也有比较不错的结果,但对于 L3 类问题,如果所涉及到的片段长度过长,还是无法做到有效的回答。
二、基于 LLM 的问答系统架构
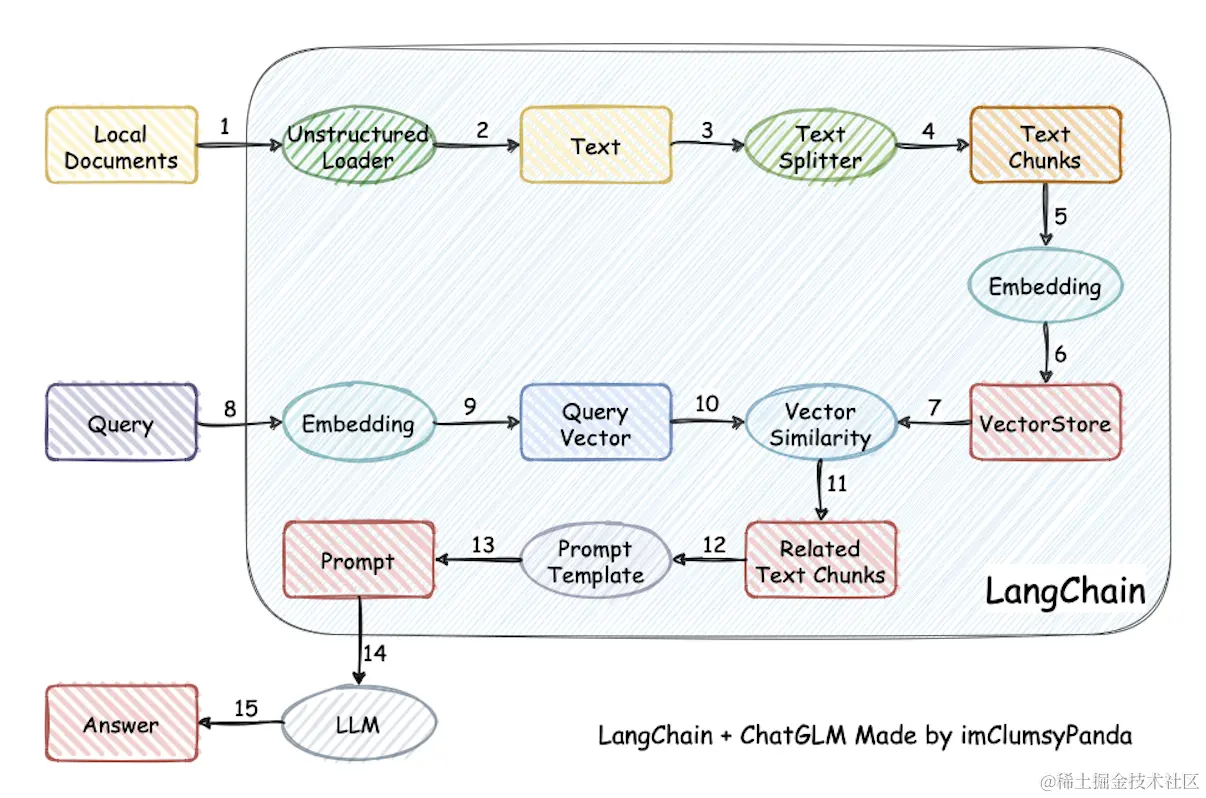
目前比较常见的开源 LLM 的问答系统都会遵循下图这种结构去进行设计,整个流程用文字表述如下:加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k 个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。
LangChain+ChatGLM 框架示意图:
参照之前,我们将之前的 QA 问题的过程进行细化,梳理出更详细的解决方案:
- 文本切分:将长文档以某种方式切分为若干 block,每个 block 大小一般会小于向量模型能处理的最大上下文。切分方式可以简单也可以是一个复杂的策略。比如,相邻的 block 之间可以保留重复的内容,用来降低简单切分方式造成的信息损失,并进一步补充 block 的上下文信息。
- 向量检索:将每个 block 映射为一个 vector。对于每个问题,也通过相同的方式与 block 进行相关性匹配,或者其他方式进行匹配。选择最相关的 1 个或者多个 block,加上问题,组合为 prompt 输入给 LLM,让其进行回答。
对于 L2 的问题,所需的 block 数量比较多,再加上提示词模板,很容易超过 LLM 的长度,因此需要进行信息的压缩和回溯。具体一个可选方案就是:
- 每一个 block 和提问的问题进行组合输入给 LLM,然后返回相关信息。
- 将多个相关信息进行汇总和筛选,总结,将相关性较高的内容作为新的 context 输入给 LLM 进行回答。
三、问题分析与解决方案
根据上述的方案设计,我们会很容易发现几个问题。虽然 L1 类问题解决比较容易,但是 L2 类问题涉及到了信息的压缩和整合,如果多次调用 LLM,则代价很大,而且时间开销不低。
整个向量检索到最后 LLM 生成的整体链路很长。需要对文本切分,然后向量化之后存储到向量数据库中。然后需要进行 KNN 检索最相似的 K 个文本片段,拼接成提示词去调用 LLM。这几个步骤都有可能出现问题,导致带来连锁反应,使得最后结果的可信度满足不了客户效果。
从整体流程梳理,细节的问题主要集中在下面几点:
- 文本切分,切分策略需要按数据集进行适配和微调,没有低成本、高质量的方案。
- 向量模型的语义表达能力问题,长文本的召回率和相关性一般。
- 作为基座的 LLM,能力不够,天花板太低。
针对出现的问题,提供几个可能的解决方案和优化措施,经过我们实验,能在一定程度上缓解这些问题。
一)文本切分
目前对文本切片的方案,主要有两种,一种就是基于策略规则,另外一种是基于算法模型。同时,文本切分的策略也和向量模型息息相关,建议同时考虑向量模型的建模能力去设定切分的方案。例如,BERT 模型能处理的最大文本长度为 512,但切分时并不一定按照 512 去切分。
基于策略规则,主要有几种不同的策略可以供选择:
- 截断:截取前 510 个或后 510 个或前 128 + 后 382。
- 分段:分段 k=L/510,然后各段可以求平均、求 max。
- 滑动窗口(Sliding window):即把文档分成有重叠的若干段,然后每一段都当作独立的文档送入 BERT 进行处理。最后再对于这些独立文档得到的结果进行整合。
Sliding window 可以使用 LangChain 里的 或者 LangChain-Chatchat 实现的 进行切分,对中文相比较友好一些。重叠的长度和窗口长度需要根据实际进行调整,没有特别明确的规则,可以根据文档的平均长度为参考基准。核心可以参考的几个指标有,响应时间、检索相关性以及产生幻觉的次数。
