在 AI 的发展中,大规模语言模型已经取得了令人瞩目的成果,然而随之而来的是模型质量和不确定性的问题。如何衡量和改进模型的质量,一直是面临的一个挑战。
什么是 TruLens

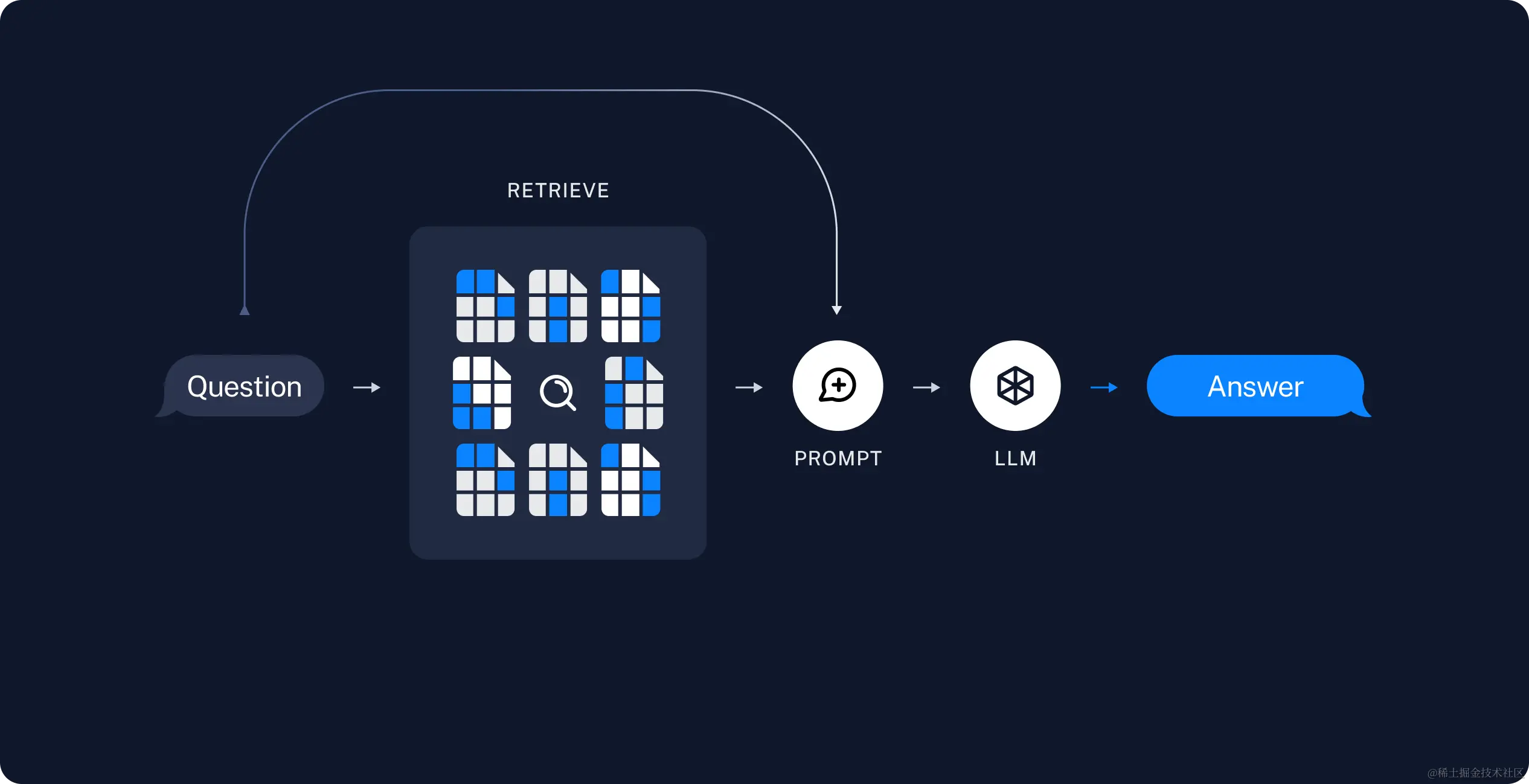
TruLens 是面向神经网络应用的质量评估工具,它可以帮助你使用反馈函数来客观地评估基于 LLM(语言模型)应用的质量和效果。反馈函数可以帮助以编程的方式评估输入、输出和中间结果的质量,从而加快和扩大实验评估的范围。你可以将它用于各种各样的用例,包括问答、检索增强生成和基于代理的应用。
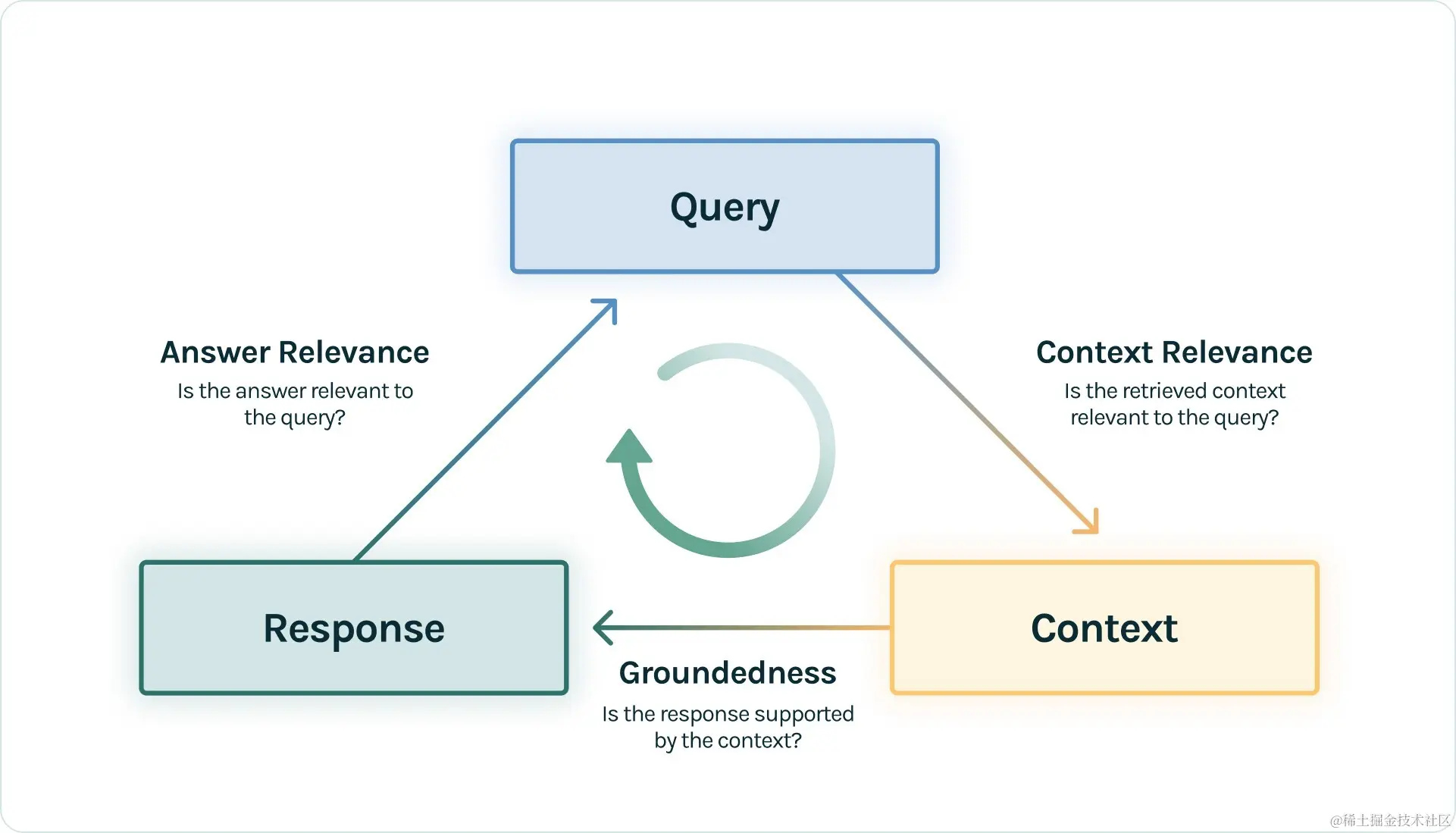
TruLens 的核心思想是,你可以为你的应用定义一些反馈函数,这些函数可以根据你的应用的目标和期望,对你的应用的表现进行打分或分类。例如:
- 定义一个反馈函数来评估你的问答应用的输出是否与问题相关,是否有依据,是否有用。
- 定义一个反馈函数来评估你的检索增强生成应用的输出是否符合语法规则,是否有创造性,是否有逻辑性。
- 定义一个反馈函数来评估你的基于代理的应用的输出是否符合道德标准,是否有友好性,是否有诚实性。
TruLens 可以让你在开发和测试你的应用的过程中,实时地收集和分析你的应用的反馈数据,从而帮助你发现和解决你的应用的问题,提高你的应用的质量和效果。你可以使用 TruLens 提供的易用的用户界面,来查看和比较你的应用的不同版本的反馈数据,从而找出你的应用的优势和劣势,以及改进的方向。
如何在 LangChain 中使用 TruLens 来评估模型输出和检索质量
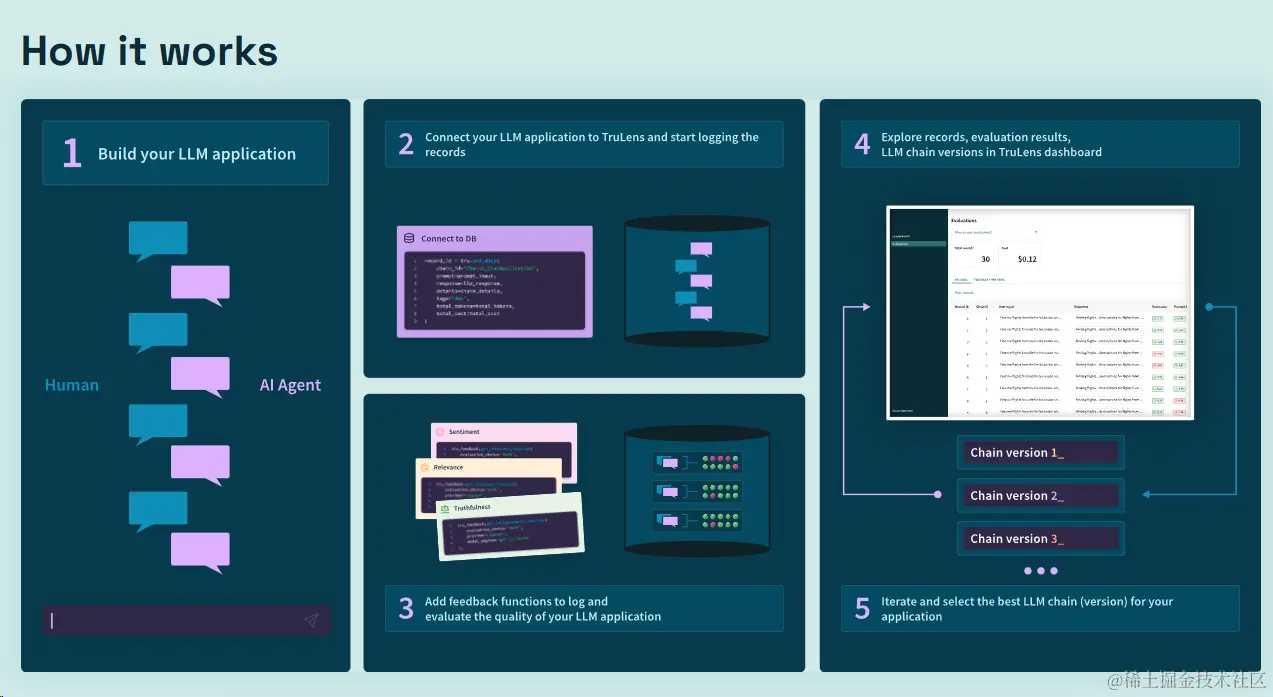
LangChain 作为一种新的语言模型框架,提供了一种有效的部署和管理大规模语言模型的框架。使用 LangChain 管理模型,不仅可以轻松部署和执行模型,还可以方便地观察模型的内部状态。再结合 TruLens 的评估工具,我们就可以对模型的质量进行深入理解和改进。
要在 LangChain 中使用 TruLens 来评估你的应用,你只需要做两件事:
- 在你的 LangChain 代码中,导入 TruLens,并使用 TruChain 类来包装你的 LangChain 对象。TruChain 类是一个装饰器,它可以让你的 LangChain 对象在运行时,自动地调用 TruLens 的反馈函数,并记录反馈数据。
- 在你的 TruLens 代码中,指定你想要使用的反馈函数,以及你想要给你的应用的 ID。你可以使用 TruLens 提供的内置的反馈函数,也可以自定义你自己的反馈函数。你可以为你的应用指定一个唯一的 ID,这样你就可以在 TruLens 的用户界面中,根据 ID 来查找和比较你的应用的反馈数据。
下面是一个简单的示例,展示了如何在 LangChain 中使用 TruLens 来评估一个问答应用:
pip install trulens_eval
# 导入 LangChain 和 TruLens
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts PromptTemplate
langchain.prompts.chat ChatPromptTemplate, HumanMessagePromptTemplate
trulens_eval TruChain, Feedback, Huggingface, Tru, OpenAI TruOpenAI
trulens_eval.feedback.provider.langchain Langchain
tru = Tru()
full_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template=,
input_variables=[],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([full_prompt])
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=chat_prompt_template, verbose=)
hugs = Huggingface()
f_lang_match = Feedback(hugs.language_match).on_input_output()
provider = TruOpenAI()
f_qa_relevance = Feedback(provider.relevance).on_input_output()
tru_recorder = TruChain(
chain,
app_id=,
feedbacks=[f_lang_match, f_qa_relevance])
tru_recorder recording:
chain()
tru_record = recording.records[]
(, tru_record)
tru.run_dashboard()